【机器学习PAI实践七】文本分析算法实现新闻自动分类
2017-06-02 09:24
471 查看
一、背景
新闻分类是文本挖掘领域较为常见的场景。目前很多媒体或是内容生产商对于新闻这种文本的分类常常采用人肉打标的方式,消耗了大量的人力资源。本文尝试通过智能的文本挖掘算法对于新闻文本进行分类。无需任何人肉打标,完全由机器智能化实现。本文通过PLDA算法挖掘文章的主题,通过主题权重的聚类,实现新闻自动分类。包括了分词、词型转换、停用词过滤、主题挖掘、聚类等流程。
二、数据集介绍
具体字段如下:| 字段名 | 含义 | 类型 | 描述 |
|---|---|---|---|
| category | 新闻类型 | string | 体育、女性、社会、军事、科技等 |
| title | 标题 | string | 新闻标题 |
| content | 内容 | string | 新闻内容 |

三、数据探索流程
首先,实验流程图: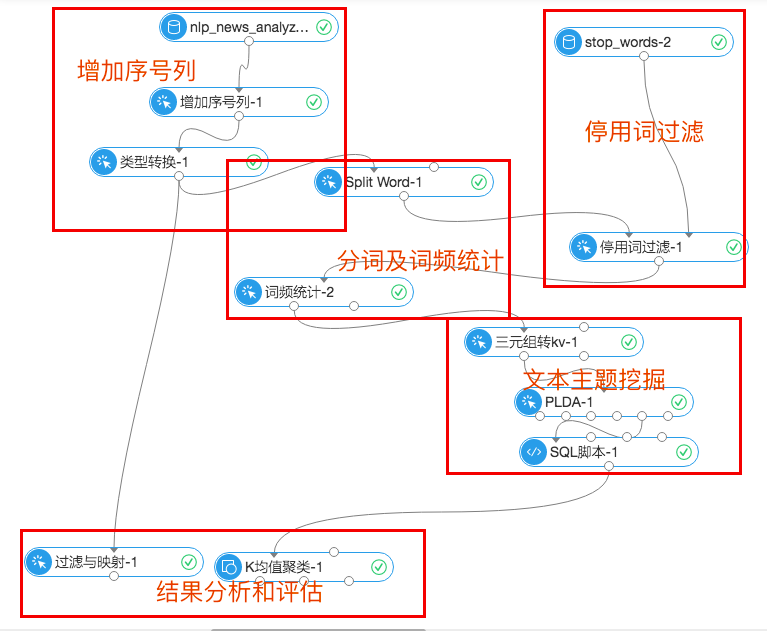
实验可以大致分为五个模块,分别是增加序号列、停用词过滤、分词及词频统计、文本主题挖掘、结果分析和评估。
1.增加序号列
本文的数据源输入是以单个新闻为单元,需要增加ID列来作为每篇新闻的唯一标识,方便下面的算法进行计算。2.分词及词频统计
这两步都是文本挖掘领域最常规的做法,首先利用分词控件对于content字段,也就是新闻内容进行分词。去除过滤词之后(过滤词一般是标点符号及助语),对于词频进行统计。如下图:
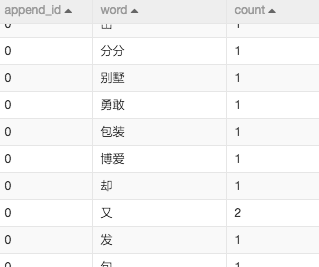
3.停用词过滤
停用词过滤功能用于过滤输入的停用词词库,一般过滤标点符号以及对于文章影响较少的助语等。4.文本主题挖掘
使用PLDA文本挖掘组件需要先将文本转换成三元形式,append_id是每篇新闻的唯一标识,key_value字段中冒号前面的数字表示的是单词抽象成的数字标识,冒号后面是对应的单词出现的频率。三元组组件生成结果如下: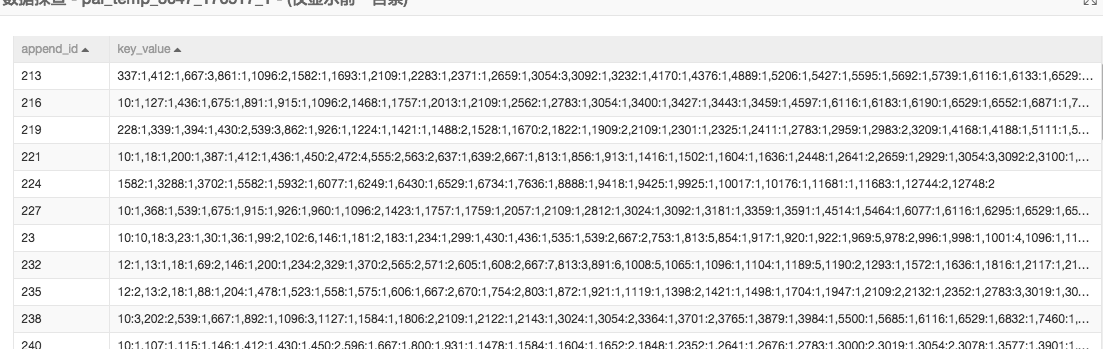
在上一步完成了文本转数字的过程,下一步数据进入PLDA算法。PLDA算法又叫主题模型,算法可以定位代表每篇文章的主题的词语。本次试验设置了50个主题,PLDA有六个输出桩,第五个输出桩输出结果显示的是每篇文章对应的每个主题的概率。如图:
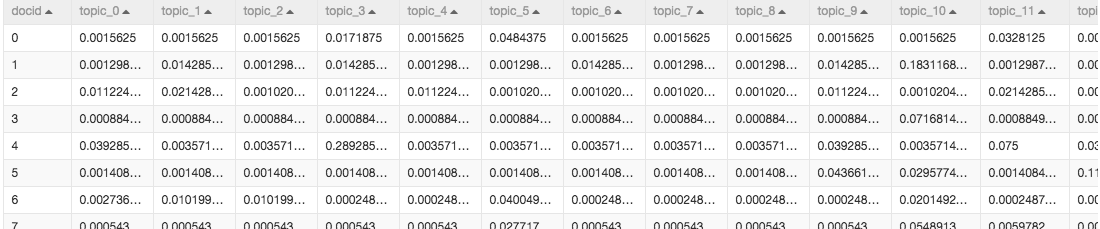
5.结果分析和评估
上一步把文章从主题的维度表示成了一个向量。接下来就可以通过向量的距离实现聚类,从而实现文章分类。我们这里可以简单看一下分类的结果。查看K均值聚类组件的结果,cluster_index表示的是每一类的名称。找到第0类,一共有docid为115,292,248,166四篇文章。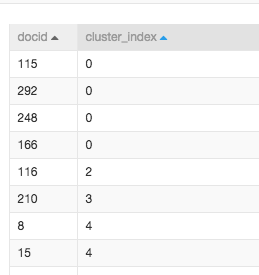
通过过滤与映射组件查询115,292,248,166四篇文章。结果如下:

效果并不十分理想,将一篇财经、一篇科技的新闻跟两个体育类新闻分到了一起。主要原因是细节的调优没有做,也没有做特征工程,同时数据量太小也是一个主要的因素。本文只是一个简单的案例,商业合作可以私下联系我们,我们在文本方面我们有较完善的解决方案。
四、其它
作者微信公众号(与我联系):

相关文章推荐
- 基于贝叶斯算法文本分析之新闻分类
- 贝叶斯分类方法学习三 python+jieba+mongodb实现朴素贝叶斯新闻文本自动分类
- 余弦定理实现新闻自动分类算法
- 余弦定理实现新闻自动分类算法
- 基于朴素贝叶斯分类器的文本分类算法的实现过程分析
- 基于朴素贝叶斯分类器的文本分类算法的实现过程分析
- 余弦定理实现新闻自动分类算法
- [Weka]在自己的算法中调用Weka实现文本分类的一个例子
- Python 基于语句检测和语句频谱分析实现文本汇总算法 (document summary algorithm)
- 深度学习算法实践14---去噪自动编码机(dA)的Theano实现
- 第一篇:K-近邻分类算法原理分析与代码实现
- 深度学习算法实践15---堆叠去噪自动编码机(SdA)原理及实现
- 深度学习算法实践15---堆叠去噪自动编码机(SdA)原理及实现
- 文本分类算法之决策树.ID3实现
- 实现文本自动分类的基础--Term频率计算方法
- 根据贝叶斯定理实现的新闻自动分类
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
- 文本分类算法之--贝叶斯分类算法的实现Java版本
- C++写日志源代码分析,可实现根据日期自动创建文件夹、日志分类、文件大小控制等
- 数据挖掘:基于朴素贝叶斯分类算法的文本分类实践