BP神经网络的数据分类
2017-05-31 19:22
302 查看
BP神经网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,前向传播是输入数据经过隐层的作用逐渐处理直至输出,根据输出和期望误差反向调节各个神经元参数以及阈值,使得输出越来越接近期望值。如图所示输入经过隐层到输出层的一个简易过程。

当输入层m到输出层n可以看做是一个自变量是m到n因变量的一个函数,神经网络的优势就在于有足够的参数和非线性的变换,不仅保证了数据的原有非线性关系还能通过足够多的参数使得对相似输入差别很小的输入在最后的结果得到改变。
BP神经网络是感知机的变种,单层感知机对非线性的分类划分能力很强,但是对于非线性问题能力不足,增加隐层数量可以使得划分能力增强。可以从下图直观看隐层数量对分类能力的一种划分。

BP神经网络说到底是对多隐层或单隐层网络的一种优化,通过有监督的训练使得对训练数据训练,对测试数据的测试结果达到更好的效果。输入层和输出层是确定好的,隐含层的数量和每一层神经元的数量选择没有确切的数目和参考依据,怎样的设置才会取得好的效果要经过大量的实验。
BP网络是有监督的前馈网络,所以网络的预测要先进行训练,像人脑一样通过训练获得联想记忆和预测能力,BP神经网络的训练包括一下几个步骤:1、网络初始化,根据输入输出序列(X,Y)确定输入层节点数你,隐层节点数l,输出节点 m,初始化输入层、隐含层、输出层神经元之间的链接权值

,初始化隐含层阈值a,输出层阈值b,给定学习率和激活函数。(这些参数个人认为来源生物神经学,神经元之间的链接通过一定的电脉冲信号传播,生物视觉是一个逐层分级的处理机制,底层提取边缘特征进行组合成高级特征,激活函数的变化相当于一个处理低级特征的过程,阈值的设置一方面是在数学函数处理上是一个调节过程,生物学上也是只有当脉冲信号达到一定程度才会有反应)。激励函数的选择输出结果一般是[-1,1]或者[0,1]所有,参数的初始化也有一定技巧,参数的初始化不能一开始让激活函数达到饱和状态趋于上届或者下届,这对参数调节带来麻烦,但是又没确切的准则具体到一个很小的范围,虽说参数要在[-1,1]之间,当然范围越小越有利于调节。阈值也是初始设定,一个常数,CNN字母识别初始值是0,一般设定1~10常数。
2、正向传递:有了输入和初始参数以及激活函数,那么一个节点的输出就可以表示为如下所示,对应输入乘以链接隐层的对应权值加上阈值,最后经过激活函数得到隐层节点的一个输出。计算表达式如下。f是激励函数


输出层计算隐含层H,对应链接权值和阈值b

3、反向传递:误差计算。代价函数:训练模型的过程就是优化代价函数的过程,代价函数对每个参数的偏导数就是梯度下降中提到的梯度,防止过拟合时添加的正则化项也是加在代价函数后面的。任何能够衡量模型预测出来的值h(θ)与真实值y之间的差异的函数都可以叫做代价函数C(θ),常用代价函数均方误差。公式为
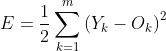
Y为期望输出,O为实际输出。权值更新共识隐层权值和输出层权值更新表达式为:
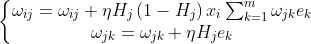
迭代更新是为了让误差函数达到最小值min(E)。梯度下降法的求解使用均方误差在求导是也方便计算。
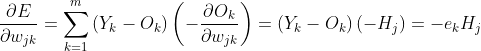
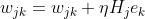
隐含层到输出层的权值更新计算以及更新后的权值如上所示。输出层到隐含层的更新计算:

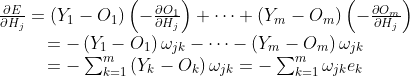

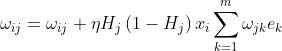
更新公式如上所示。
偏置阈值的更新
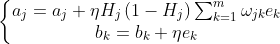
隐含层到输出层的偏置更新
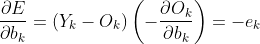
则偏置的更新公式为:
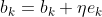
输入层到隐含层的偏置更新
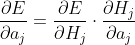
其中

则偏置的更新公式为:
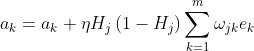
有很多的方法可以判断算法是否已经收敛,误差损失函数曲线的变化可以直观的看出损失函数的变化。BP神经网络的语音分类代码:
2)数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。
3)由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。例如神经网络的输出层若采用S形激活函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
4)S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067。归一化算法常用有最大最小法y = ( x - min )/( max - min );max,min代表数据里的最大和最小值。另外就是平均方差法:x=(x-mean(x))/var(x);
5、学习率的设置:学习率的设置是[0,1]之间,过大的学习率是权值学习过程产生震荡,过小的学习率又使得网络收敛过慢权值难趋于稳定。创新可以从自适应学习率下手。带附加动量的学习率。
以下是java语言实现的一个BP模拟算法:
测试数据:0.0 1.0 0.931939918163635
测试数据:1.0 0.0 0.9267936174891447
测试数据:1.0 1.0 0.10402885646098432
当输入层m到输出层n可以看做是一个自变量是m到n因变量的一个函数,神经网络的优势就在于有足够的参数和非线性的变换,不仅保证了数据的原有非线性关系还能通过足够多的参数使得对相似输入差别很小的输入在最后的结果得到改变。
BP神经网络是感知机的变种,单层感知机对非线性的分类划分能力很强,但是对于非线性问题能力不足,增加隐层数量可以使得划分能力增强。可以从下图直观看隐层数量对分类能力的一种划分。
BP神经网络说到底是对多隐层或单隐层网络的一种优化,通过有监督的训练使得对训练数据训练,对测试数据的测试结果达到更好的效果。输入层和输出层是确定好的,隐含层的数量和每一层神经元的数量选择没有确切的数目和参考依据,怎样的设置才会取得好的效果要经过大量的实验。
BP网络是有监督的前馈网络,所以网络的预测要先进行训练,像人脑一样通过训练获得联想记忆和预测能力,BP神经网络的训练包括一下几个步骤:1、网络初始化,根据输入输出序列(X,Y)确定输入层节点数你,隐层节点数l,输出节点 m,初始化输入层、隐含层、输出层神经元之间的链接权值
,初始化隐含层阈值a,输出层阈值b,给定学习率和激活函数。(这些参数个人认为来源生物神经学,神经元之间的链接通过一定的电脉冲信号传播,生物视觉是一个逐层分级的处理机制,底层提取边缘特征进行组合成高级特征,激活函数的变化相当于一个处理低级特征的过程,阈值的设置一方面是在数学函数处理上是一个调节过程,生物学上也是只有当脉冲信号达到一定程度才会有反应)。激励函数的选择输出结果一般是[-1,1]或者[0,1]所有,参数的初始化也有一定技巧,参数的初始化不能一开始让激活函数达到饱和状态趋于上届或者下届,这对参数调节带来麻烦,但是又没确切的准则具体到一个很小的范围,虽说参数要在[-1,1]之间,当然范围越小越有利于调节。阈值也是初始设定,一个常数,CNN字母识别初始值是0,一般设定1~10常数。
2、正向传递:有了输入和初始参数以及激活函数,那么一个节点的输出就可以表示为如下所示,对应输入乘以链接隐层的对应权值加上阈值,最后经过激活函数得到隐层节点的一个输出。计算表达式如下。f是激励函数
输出层计算隐含层H,对应链接权值和阈值b
3、反向传递:误差计算。代价函数:训练模型的过程就是优化代价函数的过程,代价函数对每个参数的偏导数就是梯度下降中提到的梯度,防止过拟合时添加的正则化项也是加在代价函数后面的。任何能够衡量模型预测出来的值h(θ)与真实值y之间的差异的函数都可以叫做代价函数C(θ),常用代价函数均方误差。公式为
Y为期望输出,O为实际输出。权值更新共识隐层权值和输出层权值更新表达式为:
迭代更新是为了让误差函数达到最小值min(E)。梯度下降法的求解使用均方误差在求导是也方便计算。
隐含层到输出层的权值更新计算以及更新后的权值如上所示。输出层到隐含层的更新计算:
更新公式如上所示。
偏置阈值的更新
隐含层到输出层的偏置更新
则偏置的更新公式为:
输入层到隐含层的偏置更新
其中
则偏置的更新公式为:
有很多的方法可以判断算法是否已经收敛,误差损失函数曲线的变化可以直观的看出损失函数的变化。BP神经网络的语音分类代码:
%% 清空环境变量
clc
clear
%% 训练数据预测数据提取及归一化
%下载四类语音信号
load data1 c1
load data2 c2
load data3 c3
load data4 c4
%四个特征信号矩阵合成一个矩阵
data(1:500,:)=c1(1:500,:);
data(501:1000,:)=c2(1:500,:);
data(1001:1500,:)=c3(1:500,:);
data(1501:2000,:)=c4(1:500,:);
%从1到2000间随机排序
k=rand(1,2000);
[m,n]=sort(k);
%输入输出数据
input=data(:,2:25);
output1 =data(:,1);
%把输出从1维变成4维
for i=1:2000
switch output1(i)
case 1
output(i,:)=[1 0 0 0];
case 2
output(i,:)=[0 1 0 0];
case 3
output(i,:)=[0 0 1 0];
case 4
output(i,:)=[0 0 0 1];
end
end
%随机提取1500个样本为训练样本,500个样本为预测样本
input_train=input(n(1:1500),:)';
output_train=output(n(1:1500),:)';
input_test=input(n(1501:2000),:)';
output_test=output(n(1501:2000),:)';
%输入数据归一化
[inputn,inputps]=mapminmax(input_train);
%% 网络结构初始化
innum=24;
midnum=25;
outnum=4;
%权值初始化
w1=rands(midnum,innum);
b1=rands(midnum,1);
w2=rands(midnum,outnum);
b2=rands(outnum,1);
w2_1=w2;w2_2=w2_1;
w1_1=w1;w1_2=w1_1;
b1_1=b1;b1_2=b1_1;
b2_1=b2;b2_2=b2_1;
%学习率
xite=0.1
alfa=0.01;
%% 网络训练
for ii=1:10
E(ii)=0;
for i=1:1:1500
%% 网络预测输出
x=inputn(:,i);
% 隐含层输出
for j=1:1:midnum
I(j)=inputn(:,i)'*w1(j,:)'+b1(j);
Iout(j)=1/(1+exp(-I(j)));
end
% 输出层输出
yn=w2'*Iout'+b2;
%% 权值阀值修正
%计算误差
e=output_train(:,i)-yn;
E(ii)=E(ii)+sum(abs(e));
%计算权值变化率
dw2=e*Iout;
db2=e';
for j=1:1:midnum
S=1/(1+exp(-I(j)));
FI(j)=S*(1-S);
end
for k=1:1:innum
for j=1:1:midnum
dw1(k,j)=FI(j)*x(k)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4));
db1(j)=FI(j)*(e(1)*w2(j,1)+e(2)*w2(j,2)+e(3)*w2(j,3)+e(4)*w2(j,4));
end
end
w1=w1_1+xite*dw1';
b1=b1_1+xite*db1';
w2=w2_1+xite*dw2';
b2=b2_1+xite*db2';
w1_2=w1_1;w1_1=w1;
w2_2=w2_1;w2_1=w2;
b1_2=b1_1;b1_1=b1;
b2_2=b2_1;b2_1=b2;
end
end
%% 语音特征信号分类
inputn_test=mapminmax('apply',input_test,inputps);
for ii=1:1
for i=1:500%1500
%隐含层输出
for j=1:1:midnum
I(j)=inputn_test(:,i)'*w1(j,:)'+b1(j);
Iout(j)=1/(1+exp(-I(j)));
end
fore(:,i)=w2'*Iout'+b2;
end
end
%% 结果分析
%根据网络输出找出数据属于哪类
for i=1:500
output_fore(i)=find(fore(:,i)==max(fore(:,i)));
end
%BP网络预测误差
error=output_fore-output1(n(1501:2000))';
%画出预测语音种类和实际语音种类的分类图
figure(1)
plot(output_fore,'r')
hold on
plot(output1(n(1501:2000))','b')
legend('预测语音类别','实际语音类别')
%画出误差图
figure(2)
plot(error)
title('BP网络分类误差','fontsize',12)
xlabel('语音信号','fontsize',12)
ylabel('分类误差','fontsize',12)
%print -dtiff -r600 1-4
k=zeros(1,4);
%找出判断错误的分类属于哪一类
for i=1:500
if error(i)~=0
[b,c]=max(output_test(:,i));
switch c
case 1
k(1)=k(1)+1;
case 2
k(2)=k(2)+1;
case 3
k(3)=k(3)+1;
case 4
k(4)=k(4)+1;
end
end
end
%找出每类的个体和
kk=zeros(1,4);
for i=1:500
[b,c]=max(output_test(:,i));
switch c
case 1
kk(1)=kk(1)+1;
case 2
kk(2)=kk(2)+1;
case 3
kk(3)=kk(3)+1;
case 4
kk(4)=kk(4)+1;
end
end
%正确率
rightridio=(kk-k)./kk4、数据的预处理:神经网络的数据预处理一般是归一化,归一化是把输入数据映射到[-1,1],或者[0,1]。为什么要归一化:因为1)输入数据的单位不一样,有些数据的范围可能特别大,导致结果是神经网络收敛慢、训练时间长。2)数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。
3)由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。例如神经网络的输出层若采用S形激活函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
4)S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067。归一化算法常用有最大最小法y = ( x - min )/( max - min );max,min代表数据里的最大和最小值。另外就是平均方差法:x=(x-mean(x))/var(x);
5、学习率的设置:学习率的设置是[0,1]之间,过大的学习率是权值学习过程产生震荡,过小的学习率又使得网络收敛过慢权值难趋于稳定。创新可以从自适应学习率下手。带附加动量的学习率。
以下是java语言实现的一个BP模拟算法:
package BPdemo;
public class BP {
//样本输入输出in&out
private double[] in;
private double[] out;
//隐藏层输入输出hidden_in*hidden_out
private double[] hidden_in;
private double[] hidden_out;
//输出层输入与输出out_in&out_out;
private double[] out_in;
private double[] out_out;
//各节点之间的权值w[i-h]&v[h-o]
private double[][] w;
private double[][] v;
//隐藏层和输出层的阈值hidden_y,out_y
private double[] hidden_y;
private double[] out_y;
//输入层隐藏层输出层节点数inputNum&hiddenNum&outputNum
private int inputNum;
private int hiddenNum;
private int outputNum;
//隐藏层输出层的一般误差
private double[] delta_hidden;
private double[] delta_out;
//总误差error
public double error;
//用于执行速率
private double rate_w;
private double rate_y;
public double sqr_err;
public BP(int inputNum, int hiddenNum, int outputNum, double rate_w,
double rate_y) {
super();
this.inputNum = inputNum;
this.hiddenNum = hiddenNum;
this.outputNum = outputNum;
this.rate_w = rate_w;
this.rate_y = rate_y;
in = new double[inputNum];
out = new double[outputNum];
hidden_in = new double[hiddenNum];
hidden_out = new double[hiddenNum];
out_in = new double[outputNum];
out_out = new double[outputNum];
w = new double[inputNum][hiddenNum];
v = new double[hiddenNum][outputNum];
hidden_y = new double[hiddenNum+1];
out_y = new double[outputNum+1];
delta_hidden = new double[hiddenNum];
delta_out = new double[outputNum];
RandomWeight();
}
private void RandomWeight() {
RandomWeight(inputNum,hiddenNum,w,hidden_y);
RandomWeight(hiddenNum,outputNum,v,out_y);
}
private void RandomWeight(int start, int end, double[][] weight, double[] yuzhi) {
for(int n=0;n<end;n++)
{
for(int m=0;m<start;m++)
{
weight[m]
= (Math.random()/32767.0)*2-1;
}
yuzhi
= (Math.random()/32767.0)*2-1;
}
}
public void train(double[] in, double[] out)
{
this.in = in;
this.out = out;
forward();
Calculate_err();
UpData();
}
private void forward() {
forward(inputNum,hiddenNum,w,hidden_y,in,hidden_in,hidden_out);
forward(hiddenNum,outputNum,v,out_y,hidden_out,out_in,out_out);
error = 0;
for(int k=0;k<outputNum;k++)
{
//System.out.println("real:"+out[k]+" test:"+out_out[k]);
}
}
private void forward(int start, int end, double[][] weight, double[] yuzhi, double[] setIn,double[] begin, double[] after) {
//inputNum,hiddenNum,w,hidden_y,in,hidden_in,hidden_out
for(int n=0;n<end;n++)
{
double sum = 0;
for(int m=0;m<start;m++)
sum += setIn[m]*weight[m]
;
begin
= sum - yuzhi
;
after
= Sigmoid(begin
);
}
}
private double Sigmoid(double d) {
// TODO Auto-generated method stub
return 1/(1+Math.exp(-d));
}
private void Calculate_err() {
Calculate_err_out();
Calculate_err_hidden();
}
private void Calculate_err_out() {
sqr_err = 0;
for(int k=0;k<outputNum;k++)
{
delta_out[k] = (out[k]-out_out[k]) * out_out[k] * (1-out_out[k]);
sqr_err += (out[k]-out_out[k])*(out[k]-out_out[k]);
}
sqr_err = sqr_err/2;
}
private void Calculate_err_hidden() {
for(int n=0;n<hiddenNum;n++)
{
double sum = 0;
for(int k=0;k<outputNum;k++)
sum += delta_out[k] * v
[k];
delta_hidden
= sum * hidden_out
* (1-hidden_out
);
}
}
private void UpData() {
UpData_v();
UpData_w();
}
private void UpData_v() {
for(int k=0;k<outputNum;k++)
{
for(int n=0;n<hiddenNum;n++)
v
[k] = v
[k] + rate_w * delta_out[k] * hidden_out
;
out_y[k] = out_y[k] + rate_w * delta_out[k];
}
}
private void UpData_w() {
for(int n=0;n<hiddenNum;n++)
{
for(int m=0;m<inputNum;m++)
w[m]
= w[m]
+ rate_y * delta_hidden
* in[m];
hidden_y
= hidden_y
+ rate_y * delta_hidden
;
}
}
public double[] test(double[] in)
{
this.in = in;
forward();
return out_out;
}
}产生训练和测试数据:package BPdemo;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class createFile {
public static void main(String[] args) throws IOException {
BufferedWriter bufw = new BufferedWriter(new FileWriter("D:\\sample.txt"));
bufw.write("0,0,1");
bufw.newLine();
bufw.write("0,1,1");
bufw.newLine();
bufw.write("1,0,1");
bufw.newLine();
bufw.write("1,1,0");
bufw.close();
BufferedWriter bufw1 = new BufferedWriter(new FileWriter("D:\\test.txt"));
bufw1.write("0,0");
bufw1.newLine();
bufw1.write("0,1");
bufw1.newLine();
bufw1.write("1,0");
bufw1.newLine();
bufw1.write("1,1");
bufw1.close();
}
}package BPdemo;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class Filetest {
public static void main(String[] args) throws IOException
{
/*int inputNum, int hiddenNum, int outputNum, double rate_w, double rate_y*/
BP bp = new BP(2,20,1,0.6,0.6);
int p = 0;
double error = 100;
while(p<30000000 && error>0.011)
{
BufferedReader bufr = new BufferedReader(new FileReader("D:\\sample.txt"));
String line = null;
error = 0;
while((line=bufr.readLine())!=null)
{
double[] in = new double[2];
double[] out = new double[1];
String[] s = line.split(",");
in[0] = Double.parseDouble(s[0]);
in[1] = Double.parseDouble(s[1]);
out[0] = Double.parseDouble(s[2]);
bp.train(in, out);
p++;
error += bp.sqr_err;
}
System.out.println("训练次数:"+p+" error:"+error);
}
BufferedReader bufr1 = new BufferedReader(new FileReader("D:\\test.txt"));
String line1 = null;
while((line1=bufr1.readLine())!=null)
{
double[] in1 = new double[2];
double[] out1 = new double[1];
String[] s1 = line1.split(",");
in1[0] = Double.parseDouble(s1[0]);
in1[1] = Double.parseDouble(s1[1]);
out1 = bp.test(in1);
System.out.println("测试数据:"+in1[0]+" "+in1[1]+" "+out1[0]);
}
}
}测试数据:0.0 0.0 0.9910598993051739测试数据:0.0 1.0 0.931939918163635
测试数据:1.0 0.0 0.9267936174891447
测试数据:1.0 1.0 0.10402885646098432

相关文章推荐
- BP神经网络的数据分类
- [置顶] 利用BP神经网络对语音数据进行分类
- BP神经网络的数据分类—语音特征信号识别
- 基于BP神经网络的数据分类
- 案例2:数据挖掘---BP神经网络的数据分类—语音特征信号分类
- 数据分类重排!
- 数据挖掘之web文本自动分类
- [导入]三级分类数据的排序
- 取不同分类下,每分类前N条数据的一个sql
- 关于数据挖掘(协同过滤、关联推荐、聚类分类)一些资料
- ASP无限分类数据库版
- 使用sql语句进行数据分类汇总
- 如何做数据的分类?
- Sql:取每个分类的前10条数据
- Delphi中根据分类数据生成树形结构的最优方法
- 专题一 数据结构分类与抽象数据类型(2005.10.24)
- ASP无限分类数据库版
- 28款数据恢复软件分类介绍
- 使用ComponentArt.WebUI.for.Asp.net.3.0的TreeView控件实现数据驱动的无限级分类管理[图文教程]
- 实现数据分类汇总的SQL语句 (转)