算法原理系列:优先队列
2017-05-25 14:51
435 查看
算法原理系列:优先队列
第一次总结这种动态的数据结构,一如既往,看了大量的教程,上网搜优先队列原理,能出来一大堆,但不知道为什么怎么这么多人搞不清楚原理和实现的区别?非要把实现讲成原理,今天就说说自己对优先队列的看法吧。缘由
顾名思义,优先队列是对队列的一种改进,队列为先进先出的一种数据结构,而优先队列则保持一条性质:在队头的原始始终保持优先级最高。
优先级最高,我们可以用一个数来衡量,所以简单的想法就是时刻把持队首的key元素最小(最小堆),或者key元素最大(最大堆)。
好了,开始构建优先队列的结构吧,现假定给你一堆数:
nums = [78, 82, 75, 35, 71, 23, 41, 42, 58, 8]
目标:
每次输出最小值,并从nums中删除该元素,直到nums的大小为0。
很简单,最navie的做法,每次遍历一遍数组,找出最小值,输出,并且置为INF,防止下次继续遍历,代码如下:
public static void main(String[] args) {
int[] test = RandomUtil.randomSet(1, 100, 10);
solve(test);
}
static final int INF = 1 << 30;
private static void solve(int[] nums){
for (int i = 0; i < nums.length; i++){
int index = -1, min = INF;
for (int j = 0; j < nums.length; j++){
if (nums[j] != INF && nums[j] < min){
index = j;
min = nums[j];
}
}
System.out.println(min);
nums[index] = INF;
}
}最简单的做法,但时间复杂度爆表,依次输出n个元素时,时间复杂度为O(n2),找最小值操作也需要O(n),此处有几个非常别捏的地方,该算法无法解决数组的动态扩展,而且把使用过的元素变为INF,所以我们需要设计一种动态扩展的数据结构来存储不断变动的nums,于是有了优先队列的数据结构。
优先队列API如下:
public class PriorityQueue<Key extends Comparable<Key>> {
Key[] array;
int N = 0; //记录插入元素个数
int SIZE; //当N>SIZE时,可以动态扩展
@SuppressWarnings("unchecked")
public PriorityQueue(int SIZE){
this.SIZE = SIZE;
array = (Key[]) new Comparable[SIZE];
}
public void offer(Key key){
}
public Key poll(){
return null;
}
public Key peek(){
return null;
}
public boolean isEmpty(){
return false;
}
}有了这样的API,我们就可以把nums中的元素全部offer进去,而当想要输出最小值时,直接poll出来即可,非常方便,想用就用,所以改进的做法如下:
public static void main(String[] args) {
int[] test = RandomUtil.randomSet(1, 100, 10);
PriorityQueue<Integer> queue = new PriorityQueue<>(10);
for (int i = 0; i < test.length; i++){
queue.offer(test[i]);
}
while (!queue.isEmpty())
System.out.println(queue.poll());
}同样能够最大不断输出最小值,且支持动态加入元素,是不是高级很多。所以该问题就转变成了设计优先队列的API了。
API设计
开始吧,在《算法》书中介绍了初级优先队列的实现,一种是基于stack操作的无序惰性算法,核心思想是,把所有的元素压入栈中,不管它们的顺序,只有当我需要最小值时,用O(n)的算法实现求最小,输出。惰性源于尽量满足插入常数级,不到迫不得已不去使用O(n)的操作。另外一种IDEA是在插入时就保持元素的有序,这样在取的操作,我们可以简单的移动一个指针来不断输出最小值,所以为了【维持插入的有序】操作,有了时间复杂度为O(n)的插入算法,而在取最小时,可以O(1)。
这是书中提到的两个初级实现,可以说它们没有什么特别的地方,想到也是理所当然的事,接下来就是实现细节的事了,我直接给出数组有序的版本(未实现动态扩展,感兴趣的可以自己实现下)。
代码如下:
/**
*
* @author DemonSong
*
* 实现基于插入排序的优先队列
*
* 插入元素 O(n)
* 删除元素 O(n)
*
* @param <T>
*/
public class PriorityQueue<T extends Comparable<T>> {
T[] array;
int N = 0;
int SIZE;
@SuppressWarnings("unchecked")
public PriorityQueue(int SIZE){
this.SIZE = SIZE;
array = (T[]) new Comparable[SIZE];
}
public void offer(T key){
if (N == 0){
array[N++] = key;
return;
}
int i = 0;
while (i < N && key.compareTo(array[i]) > 0) i++;
if (i == N){
array[N++] = key;
return;
}
rightShift(i);
array[i] = key;
}
private void rightShift(int insert){
N++;
for (int i = N-1; i >= insert+1; --i){
array[i] = array[i-1];
}
}
public T poll(){
if (this.isEmpty()) return null;
T ele = array[0];
leftShift();
return ele;
}
private void leftShift(){
for (int i = 1; i < N; i++){
array[i-1] = array[i];
}
array[N-1] = null;
N--;
}
public T peek(){
return array[0];
}
public boolean isEmpty(){
return N == 0;
}
@Override
public String toString() {
if (this.isEmpty())
return "[]";
StringBuilder sb = new StringBuilder();
sb.append('[');
for (int i = 0; i < N; i++){
sb.append(array[i]+", ");
}
String res = sb.toString().substring(0, sb.length()-2);
return res + "]";
}
public static void main(String[] args) { int[] test = RandomUtil.randomSet(1, 100, 10); PriorityQueue<Integer> queue = new PriorityQueue<>(10); for (int i = 0; i < test.length; i++){ queue.offer(test[i]); } while (!queue.isEmpty()) System.out.println(queue.poll()); }
}
对代码感兴趣的可以研究下细节,注意,为了实现简单,我的poll操作还是O(n),并不是达不到O(1).
堆原理
怎么说呢,上述初级实现中有一个array数组,它的结构相当低级,这也是为什么offer操作是O(n)的时间复杂度,假设你把nums一堆数offer进去,该数组在计算机看来是这样子的:nums = [12, 16, 37, 41, 51, 55, 56, 74, 77, 84] queue的视角: 12 -> 16 -> 37 -> 41 -> 51 -> 55 -> 56 -> 74 -> 77 ->84
可以想象,这个关系是有多么的强,我只需要开头的最小值,结果你却维护了整个数组的有序,而为了维护整个数组的有序,我又是rightShift,又是比较的,这耗费了多少操作?
所以归根结底的原因在于,取最小的操作不值得维护整体的有序性,比如,我们换个视角来看问题,如下:
堆的视角: 12 -> 16 -> 41 -> 74 -> 37 -> 51 -> 77 -> 55 -> 84 -> 56 该结构相当零活,在第一层的一定是最小的,而第二层的元素一定比第三层元素小,符合这种结构的解唯一么?如下: 12 -> 37 -> 41 -> 74 -> 16 -> 55 -> 77 -> 51 -> 84 -> 56 同样符合,是吧?
在这里,我们可以得到一个有趣的猜想,一种数据结构出现的结果越不“唯一”,维护该结构所需要的消耗越小。
那么现在问题来了,动态加入一个元素后,如下:
queue.offer(19); 12 -> 37 -> 41 -> 74 -> 16 -> 55 -> 77 -> 51 -> 84 -> 56
怎么加,加哪里,该如何维护?想想,如果维护的是一个树结构,假设从根结点开始插入该元素,因为19>12,所以必然放入下一层,但放入37还是16这个结点下?无所谓,你可以放入任何一个结点的子树中,关键来了!!!这就少维护了一半的关系!每次对半坎,所以说树结构高级的原因就在于,有些操作在判断时,都会去掉一半元素,这就好比原本规模大小为n的问题,一下子递归为n2的子问题,那自然而然递归深度只有log2n了,是吧?
所以加入一个元素如下:
12 -> 19(37) -> 41 -> 74 -> 16 -> 55 -> 77 -> 51 -> 84 -> 56
这是堆原理的另一个关键步骤,我们知道了19比37来的小,所以它不可能再进入下一层,那37怎么办?第二层已经容不下它了,所以它必须下一层找出入。这里需要注意一个堆的性质,16结点的子树和37结点的子树是不相关的,它们各自维护一层层的关系,所以37没必要和16去判断。
ok,到这堆的原理已经讲完了,真正的两个精髓被我们找到了。
维护一个相对较弱的层级结构而非很强关系的有序结构,前者的维护成本要小很多。
维护插入元素时,随机挑选某个子结点进行沉降,遇到比它大的结点,把该结点的元素代入到下一层,直到叶子结点。
好了,接下来的优先队列的实现都是细节问题了,比如为什么用数组去维护二叉堆?
答:数组就不能维护二叉堆么?队首元素从下标1开始,所以当某个父结点为k时,左子结点为2k,右子结点为2k+1。同样的,已知子结点k,父结点为k/2。
为什么插入是从数组尾部开始?
答:我也想从头部开始插啊,但头部开插,我要写个随机算法来随机选择某个子结点?而且即使实现了,你这叶子结点的生长性也太随机了吧?随机的结果必然导致父子结点的k求法失效。
尾插的好处是什么?
答:每次都是严格的扩展完全二叉堆,这还不够好么?所以刚才是沉降操作,反过来自然有了上浮操作。
删除了头元素该怎么办?
答:现在是不是就可以头插了?毕竟没有元素在头,这个位置必须有元素可以替代,为了保证二叉堆的严格性,那肯定也是从最后一个元素取嘛,ok了,优先队列的设计完毕了。然后,再看看图吧,这些操作本来就是自然而然产生的。
上浮操作:
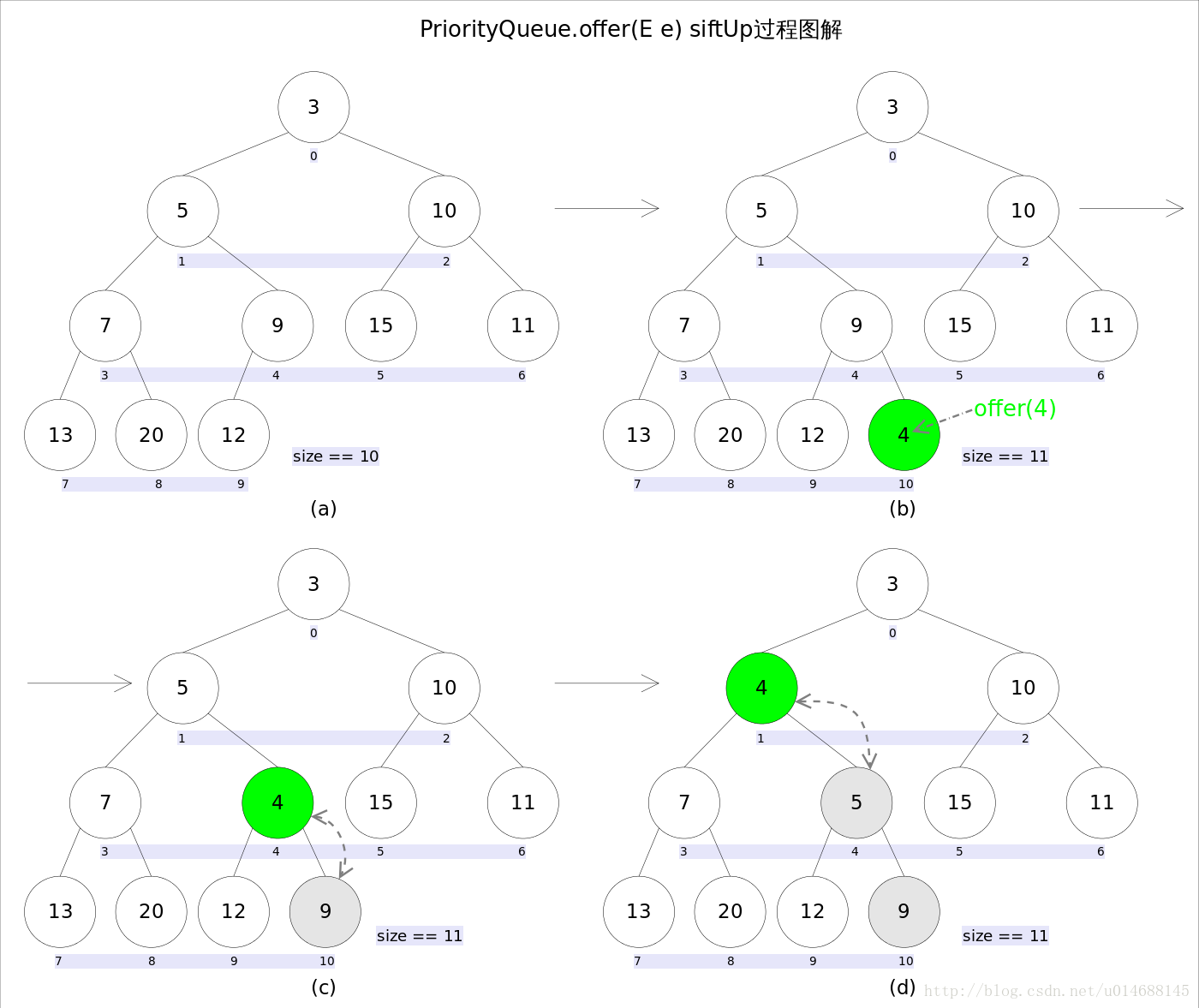
下沉操作:
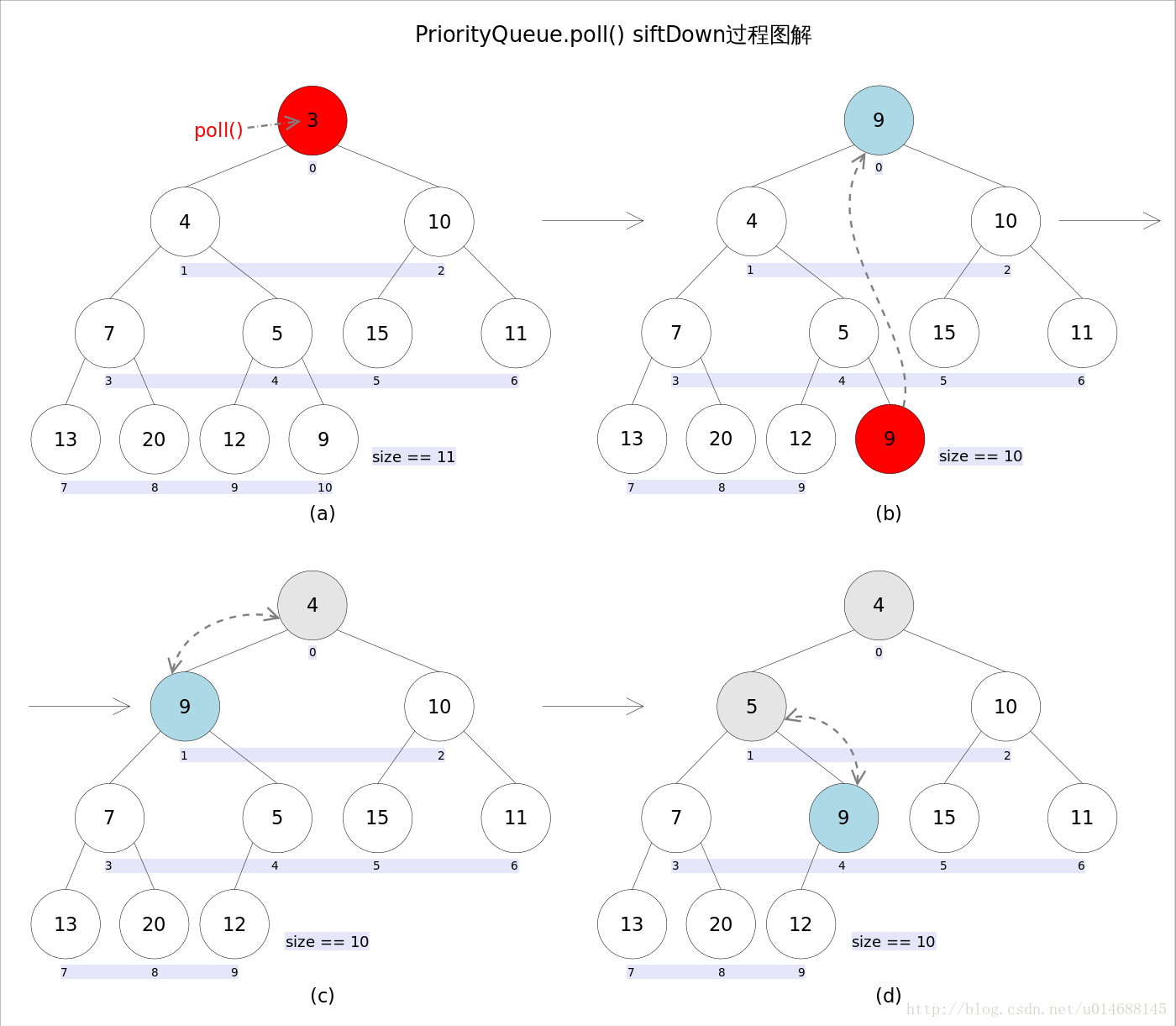
再来看看具体实现吧,建议亲自实现一遍,敲的时候就不要抄了,脑子过一遍,印象深刻。代码如下:
import java.util.Comparator;
import com.daimens.algorithm.utils.RandomUtil;
public class PriorityQueue<Key extends Comparable<Key>> {
Key[] array;
int N = 0;
int SIZE;
private Comparator<? super Key> comparator;
public PriorityQueue(int SIZE){
this.SIZE = SIZE;
array = (Key[]) new Comparable[SIZE+1];
}
public PriorityQueue(int SIZE, Comparator<? super Key> comparator){
this(SIZE);
this.comparator = comparator;
}
public void offer(Key key){
array[++N] = key;
swin(N);
}
private void swin(int k){
while (k > 1 && less(k, k / 2)){
swap(k, k / 2);
k = k / 2;
}
}
private boolean less(int i, int j){
if (comparator != null)
return comparator.compare(array[i], array[j]) < 0;
else
return array[i].compareTo(array[j]) < 0;
}
private void swap(int i, int j){
Key tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
public Key poll(){
Key key= array[1];
swap(1, N);
array
= null;
N--;
sink(1);
return key;
}
private void sink(int k){
while (2*k <= N){
int j = 2 * k;
if (j < N && less(j+1, j)) j++;
if(!less(j, k)) break;
swap(k, j);
k = j;
}
}
public Key peek(){
return array[1];
}
public boolean isEmpty(){
return N == 0;
}
@Override
public String toString() {
if (this.isEmpty())
return "[]";
StringBuilder sb = new StringBuilder();
sb.append('[');
for (int i = 1; i <= N; i++){
sb.append(array[i]+", ");
}
String res = sb.toString().substring(0, sb.length()-2);
return res + "]";
}
public static void main(String[] args) {
int[] test = RandomUtil.randomSet(1, 100, 10);
PriorityQueue<Integer> queue = new PriorityQueue<>(10, (a, b) -> (b-a));
for (int i = 0; i < test.length; i++){
queue.offer(test[i]);
}
while (!queue.isEmpty()){
System.out.println(queue.poll());
}
}
}

相关文章推荐
- [系列][编译原理]LR(0)分析算法的定义
- 优先队列的实现 Java数据结构与算法
- 小游戏系列算法之三连连看算法及原理
- uva 11374 最短路+记录路径 好题 dijkstra优先队列优化算法 邻接表法 可做模板 G++提交
- 经典算法研究系列:四、教你通透彻底理解:BFS和DFS优先搜索算法
- 各种算法的C#实现系列1 - 合并排序的原理及代码分析
- PhotoShop算法原理解析系列 - 像素化---》碎片。
- 算法系列15天速成——第九天 队列
- 算法系列15天速成——第九天 队列
- PhotoShop算法原理解析系列
- 关于 优先队列(C语言) ——(参考算法导论)
- 经典算法研究系列:四、教你通透彻底理解:BFS和DFS优先搜索算法(转csdn)
- 经典算法研究系列:四、教你通透彻底理解:BFS和DFS优先搜索算法
- 优先队列原理
- 算法笔记(堆实现的最大优先队列)
- Dijkstra单源最短路径算法; 优先队列+静态数组邻接表; STL优先队列还是没想明白排序原则;
- 经典算法研究系列:四、教你通透彻底理解:BFS和DFS优先搜索算法
- C#数据结构和算法学习系列七----队列、队列的实现和应用
- hdu 4544 湫湫系列故事——消灭兔子(优先队列 + 贪心)
- PhotoShop算法原理解析系列 - 像素化---》碎片。