第一篇:Hadoop简介
2017-05-19 14:19
190 查看
前言
本文大致介绍下Hadoop的一些背景知识,为后面深入学习打下铺垫。什么是Hadoop
Hadoop是一个开源分布式计算平台,它以HDFS文件系统和MapReduce计算框架为核心。前者能够让用户使用一些廉价的硬件搭建出分布式系统,后者则能够让用户在不需要过多了解底层架构细节的情况下,开发并行分布式应用程序。
-- 具体含义以后会详细分析。
Hadoop的作用
具体的来说,Hadoop的作用主要在于处理海量数据,这也是为什么大数据技术中常常提到这个概念的原因。更具体的来说,雅虎通过它做Web搜索,跑广告系统;百度用它做搜索日志分析,网页数据挖掘;阿里用它存储海量的交易数据;移动研究院用它进行数据分析并对外提供服务。
很多人看好它会在更多领域(如银行,医院等),更深层次,发挥出更大作用。
Hadoop的优势
为什么Hadoop能够胜任这些工作?有以下几个主要原因:
1. 高可靠性 - 能正确无误的处理数据
2. 高扩展性 - 可以方便的加入或屏蔽计算机集群中的节点
3. 高效性 - 能非常快速的处理数据
4. 高容错性 - 某个节点任务失败不会影响结果
Hadoop项目结构图
除了HDFS文件系统和MapReduce计算架构两大核心,Hadoop还提供了其他一些项目提供更多服务,这些项目也不可或缺。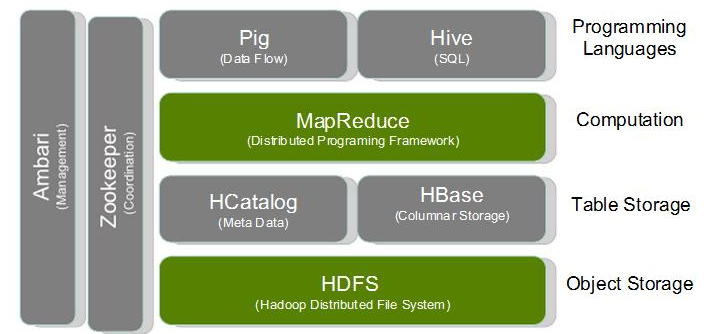
这些项目具体的使用方法,都是日后学习的重要内容,在此不做细致介绍。
Hadoop的体系结构
首先介绍HDFS文件系统的体系结构:HDFS采用M/S结构模型,Namenode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;而Datanode管理存储的数据。
下为HDFS文件系统的体系结构图:
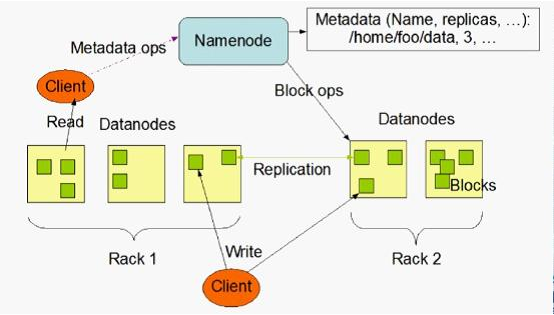
通常来说一个典型的集群环境是一台机器运行Namenode而其他每台机器运行一个Datanode。
这里再介绍下MapReduce计算架构的体系结构:
MapReduce其本质是一个非常简单易用的并行编程框架,它同样采用M/S模型,由一个单独运行在主节点的JobTracker和运行在各个从节点上的TaskTracker共同组成。
小结
本文旨在描绘出Hadoop这头“大象”的具体轮廓,其细节在以后的文章中会具体分析,细细体会,实际应用。
相关文章推荐
- 每天一点hadoop 第一篇(hadoop简介)
- HADOOP-MapReduce简介
- Hadoop学习:(二)hadoop的简介
- hadoop ipc原理简介
- hadoop简介
- 什么是HADOOP、产生背景、在大数据、云计算中的位置和关系、国内外HADOOP应用案例介绍、就业方向、生态圈以及各组成部分的简介(学习资料中的文档材料)
- Hadoop到底能做什么?怎么用hadoop? 与 R语言简介 以及 MapReduce
- 大数据技术hadoop入门理论系列之二—HDFS架构简介
- Hadoop简介
- 国内第一篇详细讲解hadoop2的automatic HA+Federation+Yarn配置的教程
- Hadoop分布式框架简介
- Hunk:Hadoop数据分析简介
- Hadoop简介(1):什么是Map/Reduce
- Hadoop入门 -- 简介,安装,示例
- Hadoop入门 -- 简介,安装,示例
- Hadoop:Hadoop简介及环境配置
- Hadoop 学习总结之一:HDFS简介
- hadoop-hdfs简介(三)
- hadoop——简介与安装