Hadoop集群安装部署---单节点伪分布式
2017-05-13 19:15
891 查看
一:linux服务器环境配置
1、设置静态ip(manual)
IP地址:192.168.77.70
子网掩码:255.255.255.0
网关:192.168.77.2
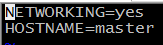
2、修改主机名:
vi /etc/sysconfig/network
3、ip地址与主机名对应:
vi /etc/hosts

**在windows下也要修改(如果在win下用到master和slave01):
C:\Windows\System32\drivers\etc

4、关闭图形化界面
vi /etc/inittab
将id:5:initdefault:-----> id:3:initdefault:

5、关闭防火墙
service iptables stop
chkconfig iptables off
二:安装jdk
1、用sftp(alt+p)将jdk传入Linux中

2、解压jdk
mkdir /usr/local/apps 创建安装目录
tar -zxvf jdk-7u65-linux-i586.tar.gz -C /usr/local/apps/ 解压到安装目录中
3、检查jdk是否存在问题
cd /usr/local/apps/jdk1.7.0_65
bin/java -version (java要小写)

4、修改配置文件
cd /usr/local/apps/jdk1.7.0_65
vi /etc/profile
在最后一行后面添加:
export JAVA_HOME=/usr/local/apps/jdk1.7.0_65
export PATH=$PATH:$JAVA_HOME/bin
5、让配置生效
cd /usr/local/apps/jdk1.7.0_65
source /etc/profile
三:安装hadoop
1、用sftp(alt+p)将hadoop传入Linux中
2、解压hadoop
tar -zxvf hadoop-2.4.1.tar.gz -C /usr/local/apps/
3、修改配置文件
cd /usr/local/apps/hadoop-2.4.1/etc/hadoop
vi hadoop-env.sh
修改JAVA_HOME=jdk安装目录

vi core-site.xml
vi hdfs-site.xml
先将mapred-site.xml.template改为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
然后vi mapred-site.xml
vi yarn-site.xml
vi slaves
(文件 slaves,配置datanode的主机名)
四:启动hadoop
1、格式化namenode
cd /usr/local/apps/hadoop-2.4.1/bin
./hadoop namenode -format
2、无密登录
a、生成密钥对:ssh-keygen
三次回车键(选择默认)
b、ssh-copy-id master
验证是否能无密登录:
登录:ssh master
退出:exit

3、自动化脚本启动
***在任何目录下都能运行下面的命令,需要改下配置文件:
vi /etc/profile
export JAVA_HOME=/usr/local/apps/jdk1.7.0_65
export HADOOP_HOME=/usr/local/apps/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

让配置文件生效:source /etc/profile
启动HDFS服务进程:start-dfs.sh
关闭HDFS服务进程: stop-dfs.sh
启动yarn服务进程:start-yarn.sh
关闭yarn服务进程:stop-yarn.sh
启动所有服务:start-all.sh
关闭所有服务:stop-all.sh
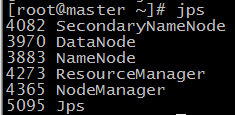
查看服务进程是否启动:jps(Java命令)
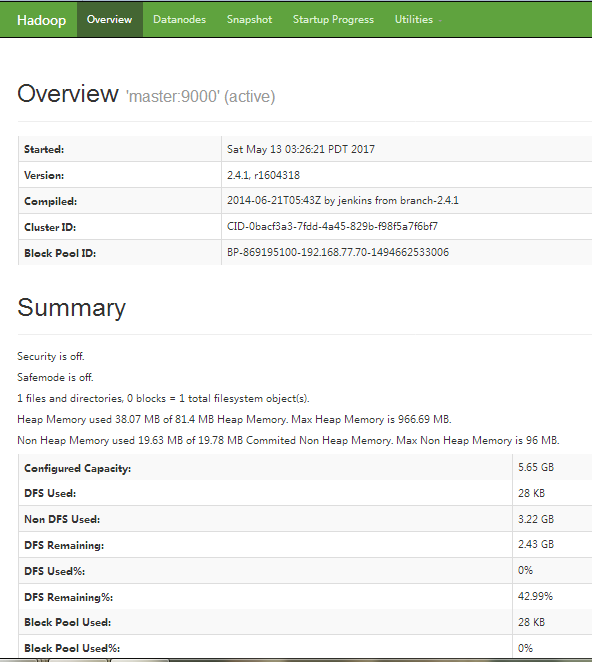
HDFS控制平台:
http://ip地址50070/
如,http://192.168.77.70:50070/
Yarn控制平台
ip地址:8080
如,192.168.77.70:8088
1、设置静态ip(manual)
IP地址:192.168.77.70
子网掩码:255.255.255.0
网关:192.168.77.2
2、修改主机名:
vi /etc/sysconfig/network
3、ip地址与主机名对应:
vi /etc/hosts
**在windows下也要修改(如果在win下用到master和slave01):
C:\Windows\System32\drivers\etc
4、关闭图形化界面
vi /etc/inittab
将id:5:initdefault:-----> id:3:initdefault:
5、关闭防火墙
service iptables stop
chkconfig iptables off
二:安装jdk
1、用sftp(alt+p)将jdk传入Linux中
2、解压jdk
mkdir /usr/local/apps 创建安装目录
tar -zxvf jdk-7u65-linux-i586.tar.gz -C /usr/local/apps/ 解压到安装目录中
3、检查jdk是否存在问题
cd /usr/local/apps/jdk1.7.0_65
bin/java -version (java要小写)
4、修改配置文件
cd /usr/local/apps/jdk1.7.0_65
vi /etc/profile
在最后一行后面添加:
export JAVA_HOME=/usr/local/apps/jdk1.7.0_65
export PATH=$PATH:$JAVA_HOME/bin
5、让配置生效
cd /usr/local/apps/jdk1.7.0_65
source /etc/profile
三:安装hadoop
1、用sftp(alt+p)将hadoop传入Linux中
2、解压hadoop
tar -zxvf hadoop-2.4.1.tar.gz -C /usr/local/apps/
3、修改配置文件
cd /usr/local/apps/hadoop-2.4.1/etc/hadoop
vi hadoop-env.sh
修改JAVA_HOME=jdk安装目录
vi core-site.xml
<configuration> <property> <name>fs.default.name</name><!-- namenode的URI --> <value>hdfs://192.168.77.70:9000/</value> </property> <property> <name>hadoop.tmp.dir</name><!-- Hadoop的默认临时文件存放路径 --> <value>/usr/local/apps/hadoop-2.4.1/tmp/</value> </property> </configuration>
vi hdfs-site.xml
<configuration> <property> <name>dfs.replication</name><!-- 副本个数 --> <value>1</value> </property> <property> <name>dfs.data.dir</name><!--datanode的工作目录 --> <value>/usr/local/apps/hadoop-2.4.1/tmp/dfs/data</value> </property> <property> <name>dfs.name.dir</name><!--namenode的工作目录 --> <value>/usr/local/apps/hadoop-2.4.1/tmp/dfs/name</value> </property> </configuration>
先将mapred-site.xml.template改为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
然后vi mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
vi yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
vi slaves
(文件 slaves,配置datanode的主机名)
四:启动hadoop
1、格式化namenode
cd /usr/local/apps/hadoop-2.4.1/bin
./hadoop namenode -format
2、无密登录
a、生成密钥对:ssh-keygen
三次回车键(选择默认)
b、ssh-copy-id master
验证是否能无密登录:
登录:ssh master
退出:exit
3、自动化脚本启动
***在任何目录下都能运行下面的命令,需要改下配置文件:
vi /etc/profile
export JAVA_HOME=/usr/local/apps/jdk1.7.0_65
export HADOOP_HOME=/usr/local/apps/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
让配置文件生效:source /etc/profile
启动HDFS服务进程:start-dfs.sh
关闭HDFS服务进程: stop-dfs.sh
启动yarn服务进程:start-yarn.sh
关闭yarn服务进程:stop-yarn.sh
启动所有服务:start-all.sh
关闭所有服务:stop-all.sh
查看服务进程是否启动:jps(Java命令)
HDFS控制平台:
http://ip地址50070/
如,http://192.168.77.70:50070/
Yarn控制平台
ip地址:8080
如,192.168.77.70:8088

相关文章推荐
- 搭建3个节点的hadoop集群(完全分布式部署)--3 zookeeper与hbase安装
- 搭建3个节点的hadoop集群(完全分布式部署)--2安装mysql及hive
- Hadoop集群安装部署---从单节点的伪分布式扩展为多节点分布式
- 搭建3个节点的hadoop集群(完全分布式部署)5 flume安装及flume导数据到hdfs
- hadoop 三个节点集群的安装部署
- 完全分布模式hadoop集群安装配置之二 添加新节点组成分布式集群
- 完全分布式Hadoop集群的安装搭建和配置(4节点)
- Hadoop单节点集群安装(伪分布式安装)
- hadoop大集群实施--比较实用的思路(设备选型、是否使用虚拟机、快速部署安装、自动复制节点等)
- Hadoop-2.7.4 八节点分布式集群安装
- centos7下安装编译并搭建hadoop2.6.0单节点伪分布式集群
- 在虚拟机上安装5节点Hadoop分布式集群(HA)-环境准备
- centos7(vm)下hadoop2.7.2完全分布式安装验证(x86)-hadoop3节点集群(2副本)
- Hadoop集群(三节点)安装与部署
- 1.如何在虚拟机ubuntu上安装hadoop多节点分布式集群
- Ambari安装之部署3个节点的HA分布式集群
- hadoop-2.4.1 HA 分布式集群安装部署
- Hadoop2.6完全分布式多节点集群安装配置
- 安装单节点伪分布式 CDH hadoop 集群
- Hadoop教程(五)Hadoop分布式集群部署安装