机器学习-周志华-个人练习10.1
2017-05-13 19:04
246 查看
10.1 编程实现k近邻分类器,在西瓜数据集3.0a上比较其分类边界与决策树分类边界的异同。
根据k近邻分类器的原理,可简单地写出如下代码,通过各近邻点投票来判断各点的类别,分别取k=3,4,5可以得到如下3图。由图可见,k近邻分类器所得结果在训练集上分类效果较好,而其余决策树分类边界相比最大的不同在于其边界并不为直线,而是可以为曲线。这是因为在确定近邻时,k近邻分类器采用的是到各点的欧氏距离,所以其边界一般是不规则的。# -*- coding: utf-8 -*-
# K-Nearest Neighbor Classifier(dataset3.0a)
import numpy as np
import matplotlib.pyplot as plt
def knn(train,test,num):
# train,test,num分别代表训练样本,待分类样本,近邻个数
output = [] # 输出相应样本的分类结果
m,n = len(train),len(test)
for i in range(n):
dist_ij = []
for j in range(m):
d = np.linalg.norm(test[i,:]-train[j,:-1])
dist_ij.append((j,d))
id_min = sorted(dist_ij, key=lambda x: x[1])[:num]
rate = [train[i[0],-1] for i in id_min]
if sum(rate)/num >= 0.5: # 当两类得票数相等时,优先划分为好瓜
output.append(1)
else:
output.append(0)
return output
data = np.array([
[0.697,0.460,1],[0.774,0.376,1],[0.634,0.264,1],[0.608,0.318,1],[0.556,0.215,1],
[0.403,0.237,1],[0.481,0.149,1],[0.437,0.211,1],[0.666,0.091,0],[0.243,0.267,0],
[0.245,0.057,0],[0.343,0.099,0],[0.639,0.161,0],[0.657,0.198,0],[0.360,0.370,0],
[0.593,0.042,0],[0.719,0.103,0]])
a = np.arange(0,1.01,0.01)
b = np.arange(0,0.61,0.01)
x,y = np.meshgrid(a,b)
k = 5
z = knn(data,np.c_[x.ravel(),y.ravel()], k)
z = np.array(z).reshape(x.shape)
fig,ax = plt.subplots(1,1,figsize=(5,5))
ax.contourf(x,y,z,cmap=plt.cm.summer,alpha=.6)
label_map = {1:'good', 0:'bad'}
ax.scatter(data[:,0], data[:,1], c=data[:,2], cmap=plt.cm.Dark2)
ax.set_xlim(0, 1)
ax.set_ylim(0, 0.6)
ax.set_ylabel('sugar')
ax.set_xlabel('density')
ax.set_title('decision boundary: %s-NN' % k)
plt.show()k=3时:
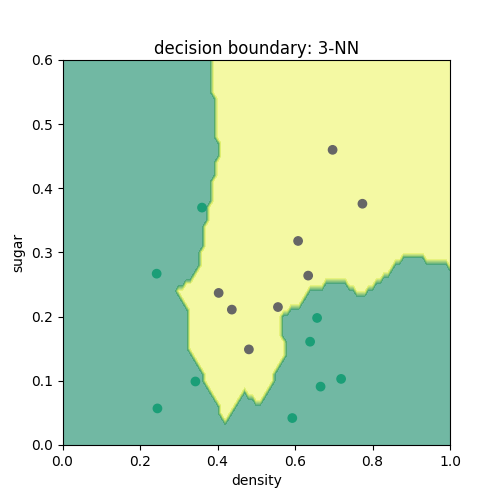
k=4时:
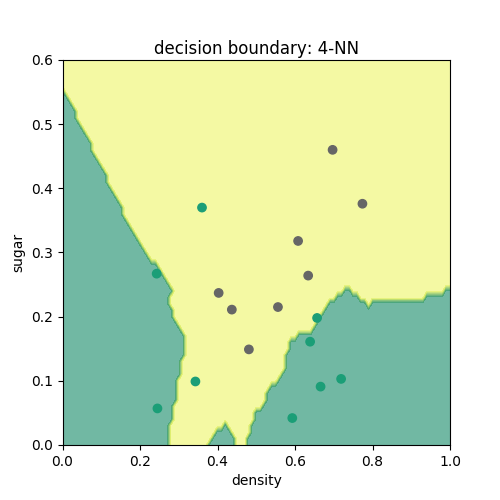
k=5时:
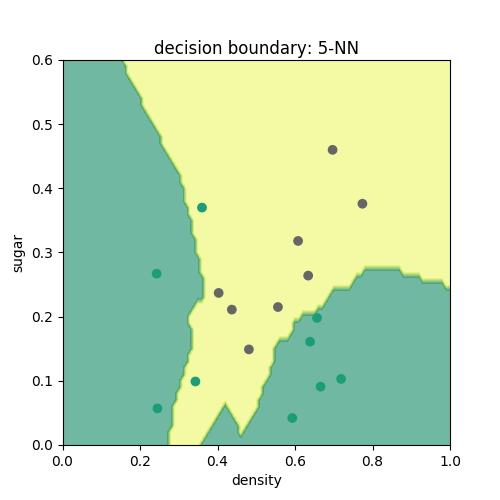

相关文章推荐
- 机器学习-周志华-个人练习10.6
- 机器学习-周志华-个人练习12.4
- 机器学习-周志华-个人练习4.4
- 机器学习-周志华-个人练习11.1
- 机器学习-周志华-个人练习13.1
- 机器学习-周志华-个人练习9.4
- 机器学习-周志华-个人练习4.3
- 机器学习-周志华-个人练习13.2
- 机器学习-周志华-个人练习8.3和8.5
- 机器学习-周志华-个人练习9.6
- 机器学习(周志华) 个人练习答案7.6
- 机器学习-周志华-个人练习13.10
- 机器学习(周志华) 习题7.3 个人笔记
- 机器学习-周志华-个人练习11.3
- 机器学习-周志华-个人练习13.4
- 机器学习(周志华版) 第一章习题1.1个人解答
- 《机器学习》周志华 习题答案 10.1
- 《机器学习(周志华)》习题10.1 答案
- 周志华《机器学习》课后习题解答系列(四):Ch3.4 - 交叉验证法练习
- 《机器学习》(周志华) 习题3.1-3.3个人笔记