Tensorflow系列二:入门
2017-05-12 11:56
281 查看
Tensorflow系列二:入门
一 Tensorflow计算模型——计算图
每个计算都是计算图中的一个节点,而节点之间边描述了计算之间的依赖关系。Tensorflow程序分为两个阶段:
第一阶段:定义计算图中的所有计算import tensorflow as tf a = tf.constant([1.0,2.0],name="a") b = tf.constant([2.0,3.0],name="b") result = a + b
第二阶段:执行计算
with tf.Session() as sess: sess.run(result)
默认计算图:
通过a.graph可以查看张量所属的计算图;通过tf.get_default_graph()可以获取当前默认的计算图。
当未指定计算图时,a.graph == tf.get_default_graph()。
tf.Graph()生成新的计算图:
import tensorflow as tf
g1 = tf.Graph()
with g1.as_default():
#指定g1为默认计算图,定义变量"v",初始化为0.
v = tf.get_variable("v",initializer=tf.zeros_initializer(),shape=[1]))
g2 = tf.Graph()
with g2.as_default():
#指定g2为默认计算图,定义变量"v",初始化为1.
v = tf.get_variable("v",initializer=tf.ones_initializer(),shape=[1])
#在计算图g1中读取变量"v"的取值
with tf.Session(grapth=g1) as sess:
tf.initialize_all_variables().run()#初始化所有变量
with tf.variable_scope("",reuse=True):
print(sess.run(tf.get_variable("v")))#输出[0.]
#在计算图g2中读取变量"v"的取值
with tf.Session(grapth=g2) as sess:
tf.initialize_all_variables().run()
with tf.variable_scope("",reuse=True):
print(sess.run(tf.get_variable("v")))#输出[1.]tf.Graph.device()指定运行计算图的设备:
g = tg.Grapg()
with g.device('/gpu:0'):
result = a + b集合(Collection)管理不同类别的资源
“资源”指张量,变量,或者运行Tensorflow程序所需的队列资源等等。tf.add_to_collections函数可将资源加入一个或多个集合;tf.get_collections函数可以获取一个集合的全部资源。
| 集合名称 | 集合内容 | 使用场景 |
|---|---|---|
| tf.Graph.VARIABLES | 所有变量 | 持久化Tensorflow模型 |
| tf.Graphkeys.TRAINABLE_VARIABLES | 可学习得变量(一般指神经网络中的参数) | 模型训练,生成模型可视化内容 |
| tf.Graphkeys.SUMMARIES | 日志生成相关的张量 | Tensorflow计算可视化 |
| tf.Graphkeys.QUEUE_RUNNERS | 处理输入的QueueRunner | 输入处理 |
| tf.Graphkeys.MOVING_AVERAGE_VARIABLES | 所有计算了滑动平均值的变量 | 计算变量的滑动平均值 |
Tensorflow数据模型——张量(tensor)
张量用于表示Tensorflow中的数据,保存的是如何得到数据的计算过程,是对计算结果的引用。import tensorflow as tf
#f.constant是一个计算,计算的结果是一个张量,保存着变量a中。
a = tf.constant([1.0,2.0],name="a")
b = tf.constant([2.0,3.0],name="b")
result = tf.add(a,b,name="add")
#result是一个张量Tensor("add:0",shape=(2,),dtype=float32)一个张量主要保存三个属性:名字(name),维度(shape),类型(dtype)。
名字是张量的唯一标识符,“node:src_output”:表明该张量是计算图的node节点的第src_output个输出。
Tensorflow支持14中类型:实数(tf.float32, tf.float64),整数(tf.int8, tf.int16, tf.int32, tf.int16, tf.uint8),布尔型(tf.bool),复数(tf.complex64)。变量.get_shape可以获取张量类型。
Tensorflow运行模型——会话
会话拥有并管理Tensorflow程序运行时的全部资源,当所有计算完成后需要关闭会话帮助系统回首资源,以防资源泄露。'''使用会话''' #方式1: sess = tf.Session() sess.run(...) sess.close()#当程序异常退出时,使会话无法关闭从而导致资源泄露。 #方式2: with tf.Session as sess: sess.run(...) '''指定默认会话,tf.Tensor.eval函数可计算张量的取值''' sess = tf.Session() #方式1: with sess.as_default(): print(result.eval()) #方式2: print(sess.run(result)) #方式3: print(result.eval(session=sess)) '''交互式环境下,直接构建默认会话''' sess = tf.InteractiveSession() print(result.eval())#无需手动指定 sess.close() '''配置生成的会话''' config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True) sess1 = tf.InteractiveSession(config=config) sess2 = tf.Session(config=config) '''当allow_soft_placement=True时,以下任意条件成立,GPU上的运算可以放到CPU上进行: 1.运算无法在GPU上执行。 2.没有指定的GPU资源 3.运算输入包含对CPU计算结果的引用 当log_device_placement=True时,日志中将会记录每个节点被安排在哪个设备上以方便调试。 '''
Tensorflow实现神经网络
Tensorflow游乐场:http://playground.tensorflow.org使用神经网络解决问题步骤:
提取问题中实体的特征向量作为神经网络的输入;
定义神经网络的结构,并定义如何从输入得到输出;
通过训练数据调整神经网络参数;
预测未知数据。
前向传播算法
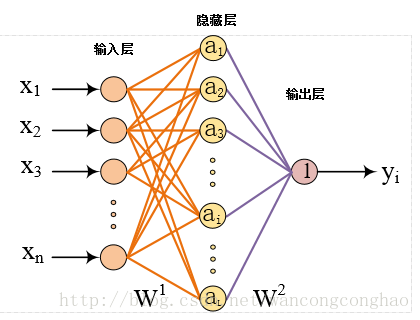
w1,w2是权重,x是神经网络输入矩阵,a是隐藏层输入矩阵,pre是神经网络输出矩阵
import tensorflow as tf ''' 假设神经网络是2个输入神经单元,3个隐藏层神经单元 输出由输入和权重的加权和得到 ''' a = tf.matmul(x,w1)#tf.matmul是矩阵乘法 pre = tf.matmul(a,w2) '''声明随机初始化的权重变量和偏置项''' weights = tf.Variable(tf.random_normal([2,3],stddev=2))#正太分布,方差为2,均值默认为0 bias = tf.Variable(tf.zeros([3])) #可通过其他变量初始新的变量 #w2 = tf.Variable(w1.initialized_value()) '''实际运行初始化所有变量''' init_op = tf.initialize_all_variables() with tf.Session as sess: sess.run(init_op) #赋值,将value赋给ref,两者必须为同类型,相同的shape tf.assign(ref,value)
Tensorflow随机数生成函数
| 函数 | 随机数分布 | 主要参数 |
|---|---|---|
| tf.random_normal | 正态分布 | 均值mean,标准差stddev,取值类型dtype |
| tf.truncated_normal | 正态分布,但如果随机值骗了均值超过2个标准差,这个数将会被重新随机 | 均值,标准差,取值类型 |
| tf.random_uniform | 平均分布 | 最小值minval,最大值maxval,取值类型 |
| tf.random_gamma | Gamma分布 | 形状参数alpha,尺度参数beta,取值类型 |
Tensorflowc常数生成函数
| 函数 | 功能 | 样例 |
|---|---|---|
| tf.zeros | 产生全0的数组 | tf.zeros([2,3],int32) |
| tf.ones | 产生全1的数组 | tf.ones([2,3],int32) |
| tf.fill | 产生一个全部为给定数字的数组 | tf.fill([2,3],9) |
| tf.constant | 产生一个给定数字的常量 | tf,constant([1,2,3]) |
神经网络训练
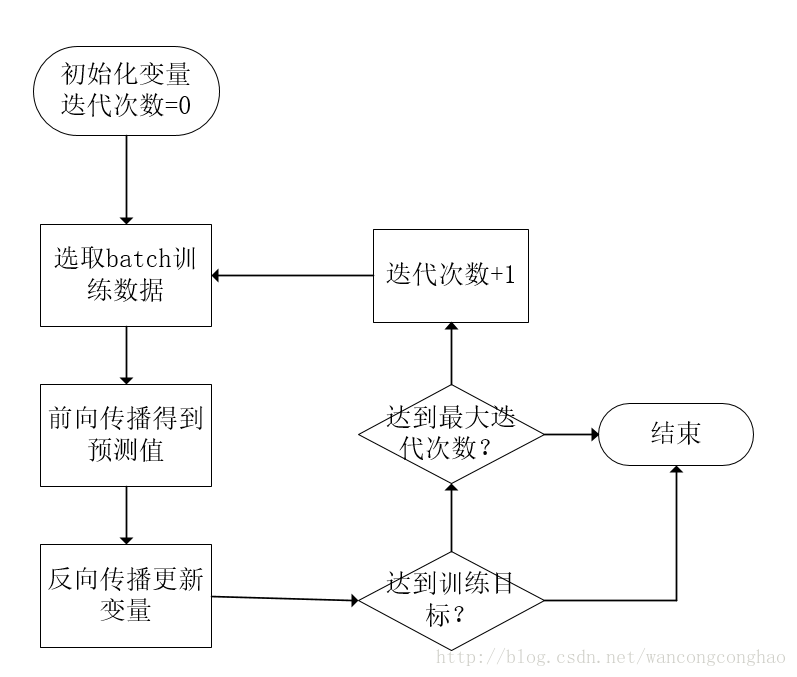
'''因为每生成一个常量,计算图中会增加一个节点,为避免迭代过程中,计算图节点数持续增加,采用placeholder机制用于提供输入数据'''
x = tf.placeholder(tf.float32,shape=(m,n),name="input")#创建占位符,m,n需要具体指定
#运行得到y
with tf.Session as sess:
sess.tun(pre,feed_dict={x:[m*n维数组]})损失函数
crossentropy=−∑yy∗log(pre),y是实际标签'''损失函数''' cross_entropy = -tf.reduce_mean(y*tf.log(tf.clip_by_value(pre,1e-10,1.0))) #tf.clip_by_value(val,minval,maxval)若val小于minval返回minval;若大于maxval返回maxval;否则返回val. '''学习率''' learning_rate = 0.001 '''定义反向传播算法优化神经网络参数''' train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy) #优化tf.GraphKeys.TRAINABLE_VARIABLES集合中变量 #常用的还有tf.train.GradientDescentOptimizer,tf.train.MomentumOptimizer
完整神经网络样例程序for二分类问题
#coding=utf-8
import tensorflow as tf
from numpy.random import RandomState#用于随机生成模拟数据集
batch_size = 8
#设定随机种子seed=1,可保证每次运行得到的结果一样
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
x = tf.placeholder(tf.float32,shape=(None,2),name="input")
y = tf.placeholder(tf.float32,shape=(None,1),name="label")
a = tf.matmul(x,w1)
pre = tf.matmul(a,w2)
cross_entropy = -tf.reduce_mean(y*tf.log(tf.clip_by_value(pre,1e-10,1.0)))
learning_rate = 0.001
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
#随机生成模拟数据集
rdm = RandomState(1)
dataset_size = 128
X = rdm.rand(dataset_size,2)
Y = [[int(x1+x2<1)] for (x1,x2) in X]
with tf.Session as sess:
init_op = tf.initialize_all_variables()
sees.run(init_op)
print("训练前的权重参数值:")
print(sess.run(w1),sess.run(w2))
STEPS = 5000 #最大迭代次数
for i in range(STEPS):
start = (i*batch_size) % dataset_size
end = min(start+batch_size,dataset_size)
sess.run(train_step,feed_dict={x:X[start:end],y:Y[start:end]})
if i%1000==0:
total_cross_entropy = sess.run(cross_entropy,feed_dict={x:X,y:Y})
print("After %d steps, cross entropy on all data is %g"%(i,total_cross_entropy))
print("训练后的权重参数值:")
print(sess.run(w1),sess.run(w2))
print("训练结束!")

相关文章推荐
- 第一阶段-入门详细图文讲解tensorflow1.4 -(八)tf.estimator构建数据预处理bostonHouse
- Windows Server入门系列19 ARP欺骗原理
- Enterprise Library Step By Step系列(七):日志和监测应用程序块——入门篇
- android opengl es入门系列
- Spark入门实战系列--4.Spark运行架构
- JAVA通信系列二:mina入门总结
- Hadoop系列修炼---入门笔记16
- NHibernate ORM介绍及优缺点-NHibernate入门到精通系列1
- 福利 | Intel发布AI免费系列课程3部曲:机器学习基础、深度学习基础以及TensorFlow基础
- NHibernate生命周期:临时态、持久态、游离态-NHibernate入门到精通系列4
- SUMO仿真快速入门系列二:使用XML生成自定义地图
- AR入门系列-02-Vuforia在Unity3d编辑器的使用
- Enterprise Library Step By Step系列(十三):加密应用程序块——入门篇
- 深度学习入门实战(二)-用TensorFlow训练线性回归
- 一入侯门“深”似海,深度学习深几许(深度学习入门系列之一)
- tensorflow入门全目录
- Jenkins入门系列之——02第二章 Jenkins安装与配置
- Python入门系列教程(三)列表和元组
- TensorFlow实战系列5--梯度下降算法
- mybatis入门系列(一)