堆排序
2017-05-11 21:34
141 查看
堆排序采用的数据结构是完全二叉树,所以在介绍堆排序之前,我们先看看完全二叉树的定义及性质。
完全二叉树是由满二叉树而引出来的。对于深度为 k 的,有 n 个结点的二叉树,当且仅当其每一个结点都与深度为 k 的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
(满二叉树定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为 k,且结点总数是 2k−1 ,则它就是满二叉树。)
二叉堆满足二个特性:
1. 父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2. 每个结点的左子树和右子树都是一个二叉堆(都是大顶堆或小顶堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为大顶堆。当父结点的键值总是小于或等于任何一个子节点的键值时为小顶堆。
一般都用数组来表示堆,i 结点的父结点下标就为 (i–1)/2 。它的左右子结点下标分别为 2∗i+1 和 2∗i+2 。
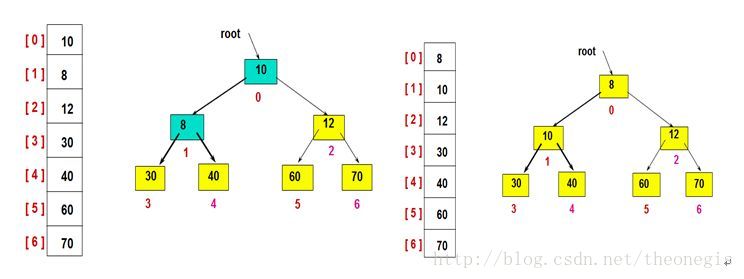
如图,左边是一个大顶堆,右边是一个小顶堆。(图片来自网络,侵权删)
1. 对数据构建大顶堆。这样最大的元素位于堆顶,即数组的第一个元素。
2. 交换数组第一个元素和最后一个元素。
3. 对第一个元素到除倒数第一个元素之外的数据序列再构建大顶堆。其实这就是重复第一步了。
4. 然后再重复第二步,交换第一个元素和倒数第二个元素。
5. 以此类推,直到堆中只有一个元素。
这个过程中,每次取出最大的元素,然后对剩下的元素再进行建堆。
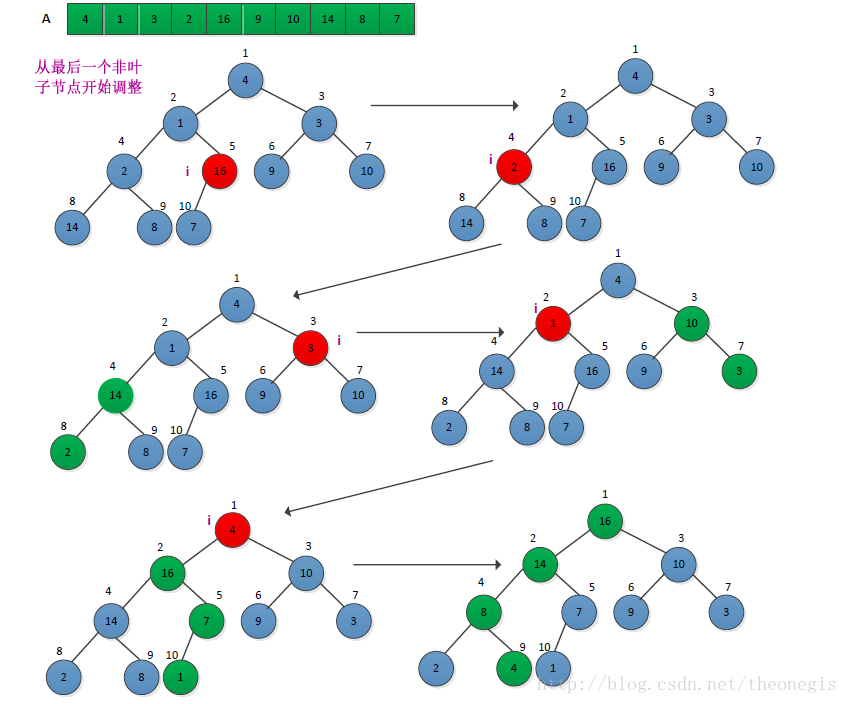
下图给出了构建大顶堆的过程(图片来自网络,侵权删):
Java实现:
注意:为什么在initHeap()函数最外层的循环是从(maxIndex - 1) / 2开始的?
其实,你从maxIndex开始也没错,相等于我们从最后一层最后一个元素开始进行比较。这样只不过是做了无用功而已。
initHeap()函数是用来构建大顶堆的我们需要从倒数第二层节点开始依次进行比较。而我们需要计算倒数第二层元素在数组中的索引位置。
比如我们的堆有 k 层,则对于满二叉树来说,总共有 2k−1个结点,而第 k 层有 2k−1 个结点,则前面 k−1 层有 2k−1−2k−1=2k−1 个结点。就是说前面 k−1 层和第 k 层有相同的结点。如果我们总共有 n 个数据(或者说结点),那么我们应该从 n2−1 开始比较(为什么减一,因为我们数组下标是从0开始的)。initHeap()传进来的是最大下标值,则我们应该从maxInde+12−1=maxInde−12 开始进行比较。
这是对于满二叉树的数学推到,我们的是完全二叉树,相同深度的完全二叉树的结点肯定小于等于满二叉树。就是说最后层次结点数量肯定会比总数的一半少,我们从(maxIndex-1)/2开始进行比较肯定是没问题的。
定义一:
只有最下面的两层结点度能够小于 2,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。定义二:
若设二叉树的深度为 h,除第 h 层外,其它各层 (1~h−1) 的结点数都达到最大个数,h 层所有的结点都连续集中在最左边,这就是完全二叉树。完全二叉树是由满二叉树而引出来的。对于深度为 k 的,有 n 个结点的二叉树,当且仅当其每一个结点都与深度为 k 的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
(满二叉树定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为 k,且结点总数是 2k−1 ,则它就是满二叉树。)
特点:
堆排序采用的二叉堆是完全二叉树结构。二叉堆满足二个特性:
1. 父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2. 每个结点的左子树和右子树都是一个二叉堆(都是大顶堆或小顶堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为大顶堆。当父结点的键值总是小于或等于任何一个子节点的键值时为小顶堆。
存储结构:
堆是在计算机中是如何进行存储的呢?一般都用数组来表示堆,i 结点的父结点下标就为 (i–1)/2 。它的左右子结点下标分别为 2∗i+1 和 2∗i+2 。
如图,左边是一个大顶堆,右边是一个小顶堆。(图片来自网络,侵权删)
堆排序
堆排序时如何进行的呢(以大顶堆为例)?1. 对数据构建大顶堆。这样最大的元素位于堆顶,即数组的第一个元素。
2. 交换数组第一个元素和最后一个元素。
3. 对第一个元素到除倒数第一个元素之外的数据序列再构建大顶堆。其实这就是重复第一步了。
4. 然后再重复第二步,交换第一个元素和倒数第二个元素。
5. 以此类推,直到堆中只有一个元素。
这个过程中,每次取出最大的元素,然后对剩下的元素再进行建堆。
下图给出了构建大顶堆的过程(图片来自网络,侵权删):
Java实现:
public static void heapSort(int[] numbers) {
for (int i = 0; i < numbers.length; i++) {
initHeap(numbers, numbers.length - 1 - i); // 构建大顶堆
swap(numbers, 0, numbers.length - 1 - i); // 交换最后位置元素和堆订元素的位置
}
}
/**
* 调整数据元素,构建大顶堆(构建从0索引位置到maxIndex索引位置的大顶堆)
* @param numbers 需要排序的数据元素
* @param maxIndex 当前的最大位置指针
*/
private static void initHeap(int[] numbers, int maxIndex) {
// 请注意这里为什么需要进行(maxIndex-1)/2次循环比较
for (int i = (maxIndex - 1) / 2; i >=0; i--) {
int parent = i; // 记录当前结点(父结点)
// 如果当前结点存在子结点,则进行比较
while (parent * 2 + 1 <= maxIndex) {
int bigger = parent * 2 + 1; // 记录较大元素结点,初始值为左结点
// 判断右结点是否比左结点大,选取较大的元素
int right = parent * 2 + 2;
if(right <= maxIndex && numbers[bigger] < numbers[right]) bigger = right;
// 如果父结点小于子结点,则进行交换
if (numbers[parent] < numbers[bigger]) {
swap(numbers, parent, bigger);
parent = bigger; // 因为parent位置的元素发生了改变,所以需要重新判断以parent为根的左右元素是否满足大顶堆的条件
} else break;
}
}
}
public static void swap(int[] numbers, int i, int j) {
if (numbers[i] == numbers[j]) return;
numbers[i] = numbers[i] ^ numbers[j];
numbers[j] = numbers[i] ^ numbers[j];
numbers[i] = numbers[i] ^ numbers[j];
}注意:为什么在initHeap()函数最外层的循环是从(maxIndex - 1) / 2开始的?
其实,你从maxIndex开始也没错,相等于我们从最后一层最后一个元素开始进行比较。这样只不过是做了无用功而已。
initHeap()函数是用来构建大顶堆的我们需要从倒数第二层节点开始依次进行比较。而我们需要计算倒数第二层元素在数组中的索引位置。
比如我们的堆有 k 层,则对于满二叉树来说,总共有 2k−1个结点,而第 k 层有 2k−1 个结点,则前面 k−1 层有 2k−1−2k−1=2k−1 个结点。就是说前面 k−1 层和第 k 层有相同的结点。如果我们总共有 n 个数据(或者说结点),那么我们应该从 n2−1 开始比较(为什么减一,因为我们数组下标是从0开始的)。initHeap()传进来的是最大下标值,则我们应该从maxInde+12−1=maxInde−12 开始进行比较。
这是对于满二叉树的数学推到,我们的是完全二叉树,相同深度的完全二叉树的结点肯定小于等于满二叉树。就是说最后层次结点数量肯定会比总数的一半少,我们从(maxIndex-1)/2开始进行比较肯定是没问题的。
