R语言聚类算法之k均值聚类(K-means)
2017-05-08 00:00
489 查看
1.原理解析:
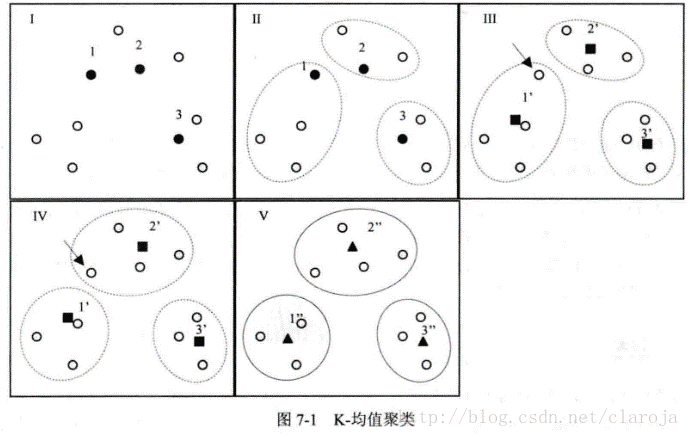
随机选取k(预设类别数)个样本作为起始中心点,将其余样本归入相似度最高中心点所在簇(cluster),再确立当前簇中样本坐标的均值为新的中心点,一次循环迭代下去,直至所有样本所属类别不再变动.
2.在R语言中的应用
在k均值聚类中我们应用到了stats包(R语言内置包)中的kmeans函数。
kmeans(x,centers,iter.max = 10,nstart = 1,algorithm = c(“Hartigan-Wong”,”Loyd”,”For-gy”,”MacQueen”))
3.以iris数据集为例进行判别分析
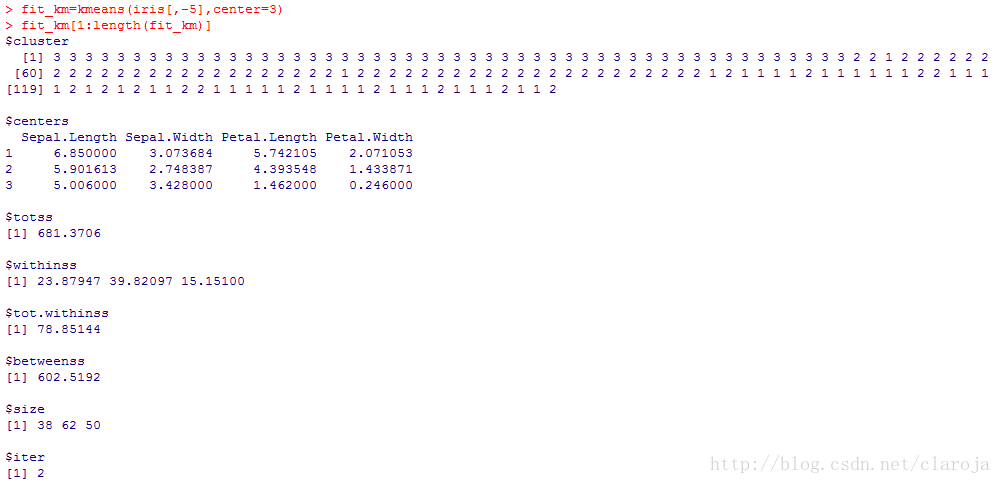
1)应用模型并查看模型的相应参数
fit_km=kmeans(iris[,-5],center=3)
fit_km[1:length(fit_km)]
随机选取k(预设类别数)个样本作为起始中心点,将其余样本归入相似度最高中心点所在簇(cluster),再确立当前簇中样本坐标的均值为新的中心点,一次循环迭代下去,直至所有样本所属类别不再变动.
2.在R语言中的应用
在k均值聚类中我们应用到了stats包(R语言内置包)中的kmeans函数。
kmeans(x,centers,iter.max = 10,nstart = 1,algorithm = c(“Hartigan-Wong”,”Loyd”,”For-gy”,”MacQueen”))
3.以iris数据集为例进行判别分析
1)应用模型并查看模型的相应参数
fit_km=kmeans(iris[,-5],center=3)
fit_km[1:length(fit_km)]

相关文章推荐
- 算法杂货铺——k均值聚类(K-means)
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
- 算法杂货铺——k均值聚类(K-means)
- k-means(k均值聚类)算法介绍及实现(c++)
- Python机器学习算法之k均值聚类(k-means)
- R语言聚类算法之k中心聚类(K-medoids)
- 面试:机器学习--k均值聚类(K-means)
- 算法杂货铺——k均值聚类(K-means)
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
- 机器学习算法与Python实践之k均值聚类(k-means)
- 机器学习教程之10-聚类(Clustering)-K均值聚类(K-means)的sklearn实现
- 机器学习(二)——K-均值聚类(K-means)算法
- k均值聚类(K-means)
- k均值聚类(K-means)
- k均值聚类(K-means)相异度计算
- 【转】算法杂货铺——k均值聚类(K-means)
- R语言聚类算法之k中心聚类(K-medoids)
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
- 全面了解R语言中的k-means如何聚类?
- k均值聚类(K-means)