Fork/Join框架及其性能介绍
2017-05-07 09:19
405 查看
Fork/Join框架介绍
Fork/Join框架是Java 7提供了的一个用于并行执行任务的框架, 大概是怎样子的呢,就是一个把大任务分割成若干个小任务,最终把每个小任务结果汇总起来得到大任务结果的框架。有点像是归并排序。下面的图就能很好地体现出来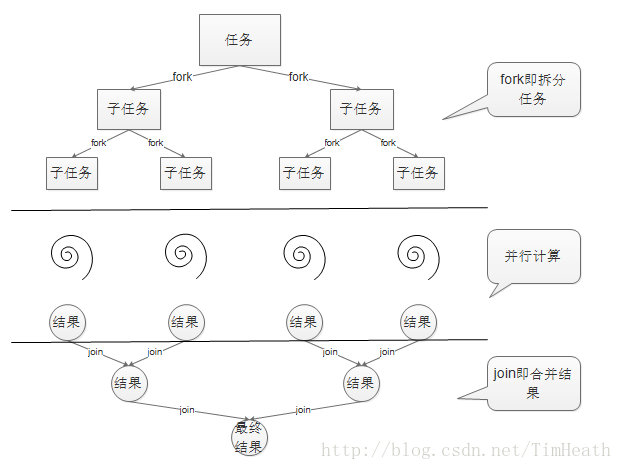
工作窃取模式(work-stealing)
在讲Fork/Join框架使用前,得先介绍一下它所使用的线程模式——工作窃取模式,何为工作窃取模式,其实就是指一个闲的发慌的线程没什么事干从其它线程的任务队列(一个双端队列)后面窃取一个任务来干。那么为什么需要这个鸟玩意呢?其实说起来也很容易理解,比如说我是资本家,招了四个员工(代表四个线程),然后把一些任务写在清单(任务队列)上,每个员工按照清单上写的从头到尾执行一个个任务,每执行一个任务就从清单上划掉(出队),有些员工比较牛逼,很快就做完了,而有些员工比较懵逼,清单上还有很多任务没完成,于是为了竟可能压榨员工(充分利用CPU),资本家让没什么事干的员工去把还有很多事没干的员工的任务拿过来干,具体是怎么拿呢,从清单的末尾拿。大概就是这个情况,下面弄张图加强理解一下

使用Fork/Join框架
现在我要用Fork/Join框架实现一个功能,计算从1加到1000000000的总和。这个功能就可以看做是一个大任务了,那我们怎么把这个大任务体现在Java中呢。我们可以定义一个类,去继承
RecursiveAction或者是
RecursiveTask,这个两个都是抽象类,有一个抽象方法
compute(),他们之间的区别在于,前者是没有返回值的,后者是有返回值的,有点像是
Runnable和
Callable的关系。
现在我就定义了一个类
ForkJoinCalculator继承了
RecursiveTask,因为我们需要返回值,要返回任务的计算结果。
下面我直接贴上
ForkJoinCalculator类的代码,有着前面的概念,应该不难理解
import java.util.concurrent.RecursiveTask;
public class ForkJoinCalculator extends RecursiveTask<Long> {
private long start;
private long end;
private static final long THRESHOLD = 10000;// 临界值
public ForkJoinCalculator(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
if (end - start <= 1000) {
// 不大于临界值直接计算和
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
// 大于临界值继续进行拆分子任务
long mid = (start + end) / 2;
// 拆分子任务
ForkJoinCalculator calculator1 = new ForkJoinCalculator(start, mid);
calculator1.fork();
// 拆分子任务
ForkJoinCalculator calculator2 = new ForkJoinCalculator(mid + 1, end);
calculator2.fork();
//合并子任务结果
return calculator1.join() + calculator2.join();
}
}
}任务定义好了,现在就可以来测试一下了。要执行一个
ForkJoin任务,得先有一个线程池,能够执行
ForkJoin任务的线程池就是
ForkJoinPool,这个跟我们的普通的线程池使用上很像,因为它们的祖先都是
ExecutorService~
测试代码
@Test
public void test() {
ForkJoinPool forkJoinPool = new ForkJoinPool();
Long sum = forkJoinPool.invoke(new ForkJoinCalculator(1, 1000000000L));
System.out.println(sum);
}输出结果
500000000500000000
Fork/Join框架的性能
只要牵扯到并发的,无一例外都会谈到性能,因为并发编程的目的就是为了压榨CPU资源,提高程序运行速度。值得一提的是,有时候同样完成一个任务,多线程还不如单线程快,比如说在单核的CPU上,多线程的上下文切换也是一笔不小的开销,所以在单核的CPU上多线程还不如单线程速度快。
除此之外,Fork/Join框架还应该注意到另外一个问题,我直接用例子先演示一下这个问题
import java.util.concurrent.ForkJoinPool;
import org.junit.Test;
public class ForkJoinTest {
@Test
public void test() {
long start = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
Long sum = forkJoinPool.invoke(new ForkJoinCalculator(1, 1000000000L));
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println(end - start);
}
@Test
public void test1() {
long start = System.currentTimeMillis();
long sum = 0;
for (long i = 1; i <= 1000000000L; i++) {
sum += i;
}
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}上面那段代码,
test()方法使用的是Fork/Join框架完成功能,
test1()方法使用的是传统方法单线程完成功能。执行时间上
test()都在600毫秒左右,而
test1()方法在370毫秒左右,可以看见使用Fork/Join方式还比单线程的方式慢。而我的电脑环境是Win10操作系统,CPU是双核的,所以不是单核CPU的锅。
其实这个原因也是很好理解的,因为Fork/Join框架执行的时候,需要不断地拆分任务,又不断地合并任务结果,这些也是需要消耗一点时间的,而任务不大可以很快就能执行完的情况下,它的fork和join操作无疑占据整个程序运行时间比例比较大。
那么,如果任务很大呢?比如说我把1000000000L改成50000000000L(结果是负数,超出了Long的范围,不过我们不关心结果只关心执行时间),
test()方法耗时18246毫秒,而
test1()方法耗时17236毫秒,虽然
test()还是落后于
test1(),但已经没有一开始那样落后太多,其实可以再加大一点数的,让
test()把
test1()比下去。不过我心痛CPU (T_T),也不想等这么久。不过这已经可以说明问题了,可想而知当任务越大时,Fork/Join框架的优势就越明显。
在其中还要提到的一点是CPU的利用率,在
test()方法执行时,我的CPU的利用率如下图,可知四个核都用上了,知道我为什么心痛CPU了吧

而
test1()方法执行时是这样子的,说明并没有充分利用到CPU

还需要注意的一点是,拆分的临界值的设定对Fork/Join框架执行的速度也很关键,不能太大,也不能太小,太大了没有充分拆分任务压榨CPU,太小了就会拆分过度,浪费太多时间在拆分上,还是以
1000000000L为例,我把
ForkJoinCalculator的临界值
THRESHOLD从
10000改成
1000000,
test()方法执行时间是380毫秒左右,比上面的测试要快,说明临界
10000是太小了。具体取哪个临界值,得自己慢慢测了,反正我不会数学推演(- _ -)

相关文章推荐
- 多线程(五) Fork/Join框架介绍及实例讲解
- java ForkJoin框架实现统计词频性能比较
- Fork/Join框架介绍 II 【在文档中查找一个词并返回文档或行中所出现这个词的次数】
- 多线程(十一)Fork/Join框架介绍
- JDK7并行计算框架介绍二 Fork/Join开发实例
- java Fork/Join框架介绍
- 特殊的线程池---Fork/Join框架介绍及实例讲解
- JDK7并行计算框架介绍二 Fork/Join开发实例
- 并行编程框架 ForkJoin(介绍了一点原理,可扩展)
- 多线程(五) Fork/Join框架介绍及实例讲解
- Fork/Join框架介绍
- Fork/Join框架之双端队列
- Java 7 Fork/Join 框架
- Fork/Join框架之Fork、Join操作
- Fork/Join框架之双端队列
- Java线程之fork/join框架
- java7 、Fork/Join 框架原理
- JDK7新特性之fork/join框架
- Java 7 Fork/Join 框架
- Java 7 Fork/Join 并行计算框架概览