js正则表达式
2017-05-06 12:07
239 查看
存在即必要
在了解正则表达式之前,我们有必要了解一下传统js操作字符串的方法,包括search(),substring(),charAt()以及split()等等,具体使用方法可查阅参考文档,而传统方法针对某些特定要求对字符串进行处理时比较繁琐,下面看一个例子:
要求将字符串:ds,4r dh6y 77 r8 jds 339t中的数字取出,传统方法操作如下:

而如果使用正则表达式,获得相同的结果会是怎样的呢
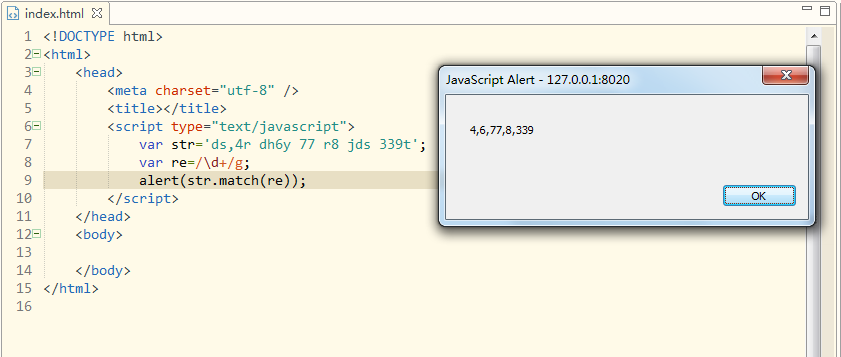
三条代码,仅仅需要三条代码!我想正则表达式的作用和价值已经不言而喻了,正则表达式通俗点理解就是人为定义的一种操作字符串的规范,w3cshool提供的参考文档中有详细介绍。
值得注意的是,并不是js中所有操作字符串的方法都支持正则表达式,而支持正则表达式的方法只有四个——search(),match(),replace(),split()

使用到match()方法的小例子——敏感词过滤:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title></title>
<script type="text/javascript">
window.onload=function(){
var txt1=document.getElementById("txt1");
var txt2=document.getElementById("txt2");
var btn=document.getElementById("btn");
btn.onclick=function(){
var re=/苍老师/g;
txt2.value=txt1.value.replace(re,"***");
}
}
</script>
</head>
<body>
转换前:<textarea rows="10" cols="30" id="txt1"></textarea><br>
<input type="button" id="btn" value="过滤" /><br>
转换后:<textarea rows="10" cols="30" id="txt2"></textarea>
</body>
</html>
注意程序中的re=/苍老师/g,//是正则表达式的特有标志,中间输入内容,g是修饰符代表全局匹配。与g同类的修饰符还有两个:

“[ ]”
[abc]这是一个简单的字符类示例,代表a或者b或者cvar re=/1[abc]2/代表1和2之间出现的只能是a或者b或者c,等同于var re=/1a2|1b2|1b3/同样,[a-c],[1-9],[a-z1-9],[1-9a-z]都是字符类

注意“^”在中括号中代表“非”的意思,而在中括号外则代表正则开始匹配的位置,正则匹配从“^”开始到“$”结束。
转义
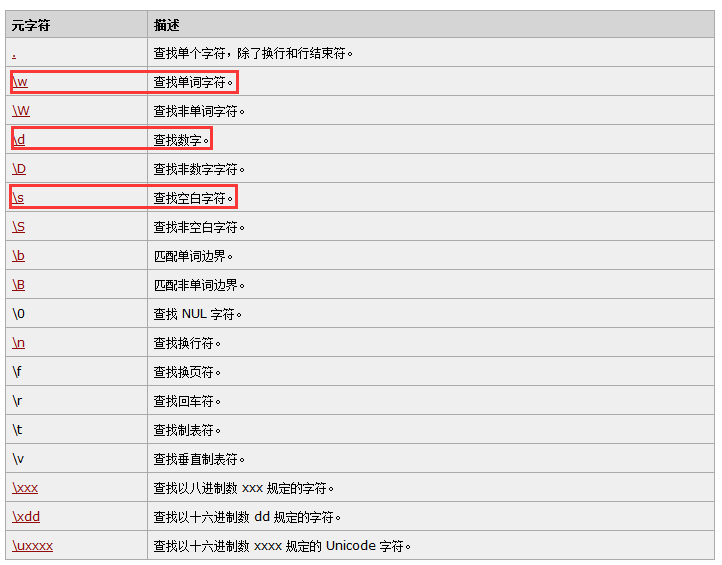
最常用的转义字符就是上图标注出来的三个
\w 英文、数字、下划线 [a-z0-9]
\d 数字 [0-9]
\s 空白字符(不可打印不可显示的东西)
量词
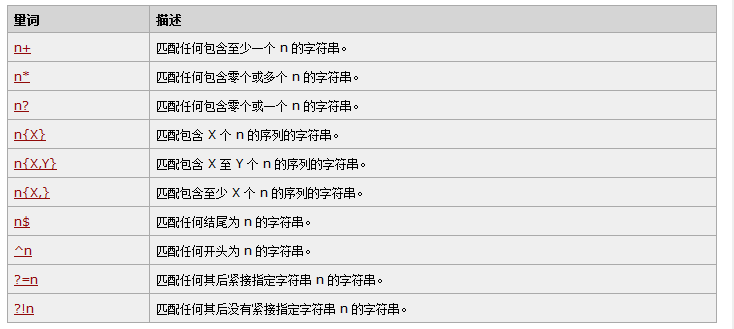
实例
电话号码,8位为例(第一位不能为0)
——/[1-9]\d{7}/
qq号,5到11位,第一位不能为0
——/[1-9]\d{4,10}/
固定电话
假设010-66668888-86
当然也可以写成66668888,区号和分机号非必需
——/(0\d{2,3}-)?[1-9]\d{7}(-\d{1,5})?/
邮箱匹配
一串英文、数字、下划线 @ 一串英文、数字 . 一串英文\w+ @ [a-z0-9]+ . [a-z]+
好了,我们初步得到了表达式——/\w+@[a-z0-9]+.[a-z]+/
是不是这样就可以了呢
假如我们想匹配“啦啦nihaoa@163.com”,很明显这是一个错误的邮箱格式,不应该出现汉字,可是匹配结果还是返回了true
好,只需稍作修改——/^\w+@[a-z0-9]+.[a-z]+$/,我们指定了匹配的开始和结束,上面出现的问题则迎刃而解。

相关文章推荐
- JS正则表达式详解[收藏]
- JS正则表达式
- js正则表达式文本框输入限制
- js正则表达式验证各类需求(整数,实数,小数,时间,URL等)
- JS正则表达式怎样实现Java中String.replaceAll的效果
- js正则表达式
- JS正则表达式验证账号、手机号、电话和邮箱 验证帐号是否合法 验证规则:字母、数字、下划线组成,字母开头,4-16位。 复制代码 function checkUser(str){ var
- JS正则表达式的RegExp对象和括号的使用
- JS正则表达式的简单使用
- js正则表达式
- JS正则表达式速查
- js正则表达式校验非负浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
- js正则表达式
- JS正则表达式
- JS正则表达式元字符
- JS正则表达式详解
- js正则表达式
- js正则表达式
- [转]js正则表达式
- js正则表达式判断ip格式