XML文件解析—System.Xml的一些方法
2017-05-05 21:37
489 查看
最近想使用XML文档作配置文件,在Unity Editor中批量处理一些东西。对于相同的问题见过有使用txt作为配置文件的案例,不过之前简单学过使用C++的TinyXml库解析XML配置文档,并且XML文档具有结构化的优点,觉得使用起来会比较方便。然而,在Unity中选择使用C#进行开发,那么.NET库的方法就必须要学了。
.NET有两种模型来操作XML文档:一种是基于文档对象模型(DOM),使用XmlDocument等类型,将XML一次性读取到内存,采用树结构来描述,支持对节点的随机访问;另一种是基于流模型,使用XmlReader等类型,这样的优点是节约内存空间(特别是当XML文件很大的时候),缺点是不支持随机访问。由于开发需求并不要求特别大的XML文件,故选择采用较为直观的DOM模型。
XML简介:基本概念包括元素、属性。元素表示从一个标签开始到该标签结束的所有部分,可以包括:文本、属性、其它元素。XML语言使用标签来区分各个元素,使用缩进在形式上区分父元素和子元素,每个XML文档都有一个根元素。当XML文档被描述成一个树结构时,每个元素就成为了树的节点,并且节点之间的父子关系与元素保持一致。比如,根元素对应于一个根节点。属性用来描述元素的一些特性,它的使用应该和子元素数据区分开。
下面我们来看.NET类库中基于DOM模型的API。关键的类型有三个:XmlNode,XmlDocument,XmlElement。首先XmlNode是另外两个的基类,并且是一个抽象类,它描述了XML树的节点。XmlDocument用来表示XML文档,它相当于整个文档的“入口”,由它可以获取包括根节点在内的,整个XML树的所有节点。XmlElement表示XML元素,它与XmlNode的区别就像元素与节点概念上的区别一样,从XmlElement的一些方法上就可以看出(比如它可以访问属性,而XmlNode不能)。从继承关系上看,它们之间必有功能相同的方法,实际使用中最常用的是XmlElement,这里列举一些该类型成员和方法的使用方式进行探究。
1. 一些数据成员:
FirstChild:子节点,父节点,体现了树的结构。
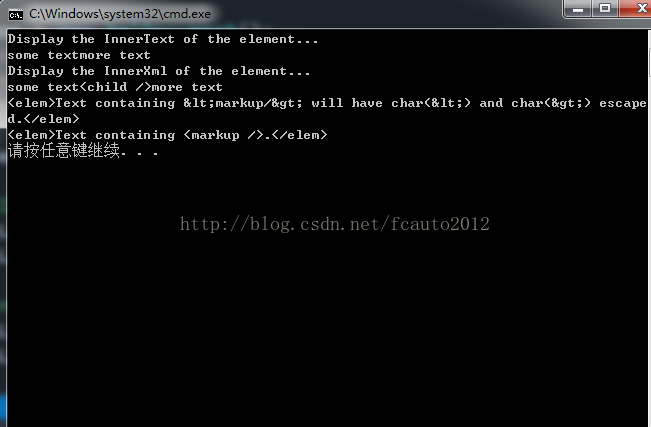
InnerText/InnerXml/OuterXml:带Xml的方法会保留内容中的<xxx>标记符号,而InnerText只返回其中的文本,应该是最常用的。示例:
Item:通过标签名称来获取子元素,返回XmlElement类型,感觉是非常好用的方法。示例:

Name:返回标签名称。
HasAttribute:在get之前,先调用一下这个函数确认是否有叫这个名称的属性。示例:
GetElementsByTagName:通过标签名称来获取一个列表(XmlNodeList类型),存储所有同名的元素节点。这个方法继承自XmlNode。示例:

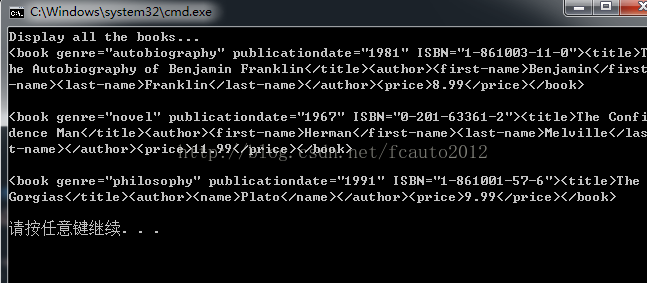
GetEnumerator:获取循环访问当前节点中子节点的枚举。(相当准确的定义!之前一直不太明白枚举的含义,这么看来十分像迭代器。)示例:文件输入为books.xml,同上
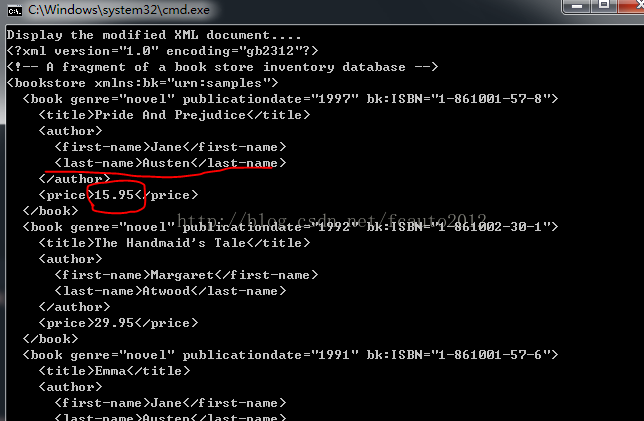
SelectSingleNode:一个获取节点的函数,参数是一个XPath表达式。XPath是一种查询语言,可以从XML文档中选择特定的节点或元素,以进行处理。这个函数也可以用成和Item一样的效果,事实上,它比Item的功能要强很多。这一系列的函数还有返回节点列表的SelectNodes,并且XmlDocument也有这个方法。示例:
以上示例全部是MSDN上的,我觉得MSDN虽然给出了示例代码和少许解释,但如果不自己运行并尝试修改,无法完全理解一些方法的使用。此外,本文列出的方法都是访问器,修改器的语法与访问器很相似,在此基础上并不难掌握。
参考文献:
1. MSDN:https://msdn.microsoft.com/zh-cn/library/system.xml(v=vs.110).aspx
2. 内格尔李铭. C#高级编程[M]. 清华大学出版社, 2013.
3. W3Cschool:
http://www.w3cschool.cn/xml/ http://www.w3cschool.cn/xmldom/
4. http://blog.csdn.net/tiemufeng1122/article/details/6723764/
.NET有两种模型来操作XML文档:一种是基于文档对象模型(DOM),使用XmlDocument等类型,将XML一次性读取到内存,采用树结构来描述,支持对节点的随机访问;另一种是基于流模型,使用XmlReader等类型,这样的优点是节约内存空间(特别是当XML文件很大的时候),缺点是不支持随机访问。由于开发需求并不要求特别大的XML文件,故选择采用较为直观的DOM模型。
XML简介:基本概念包括元素、属性。元素表示从一个标签开始到该标签结束的所有部分,可以包括:文本、属性、其它元素。XML语言使用标签来区分各个元素,使用缩进在形式上区分父元素和子元素,每个XML文档都有一个根元素。当XML文档被描述成一个树结构时,每个元素就成为了树的节点,并且节点之间的父子关系与元素保持一致。比如,根元素对应于一个根节点。属性用来描述元素的一些特性,它的使用应该和子元素数据区分开。
下面我们来看.NET类库中基于DOM模型的API。关键的类型有三个:XmlNode,XmlDocument,XmlElement。首先XmlNode是另外两个的基类,并且是一个抽象类,它描述了XML树的节点。XmlDocument用来表示XML文档,它相当于整个文档的“入口”,由它可以获取包括根节点在内的,整个XML树的所有节点。XmlElement表示XML元素,它与XmlNode的区别就像元素与节点概念上的区别一样,从XmlElement的一些方法上就可以看出(比如它可以访问属性,而XmlNode不能)。从继承关系上看,它们之间必有功能相同的方法,实际使用中最常用的是XmlElement,这里列举一些该类型成员和方法的使用方式进行探究。
FirstChild:子节点,父节点,体现了树的结构。
InnerText/InnerXml/OuterXml:带Xml的方法会保留内容中的<xxx>标记符号,而InnerText只返回其中的文本,应该是最常用的。示例:
using System;
using System.Xml;
public class Test {
public static void Main() {
XmlDocument doc = new XmlDocument();
doc.LoadXml("<root>"+
"<elem>some text<child/>more text</elem>" +
"</root>");
XmlElement elem = (XmlElement)doc.DocumentElement.FirstChild;
// Note that InnerText does not include the markup.
Console.WriteLine("Display the InnerText of the element...");
Console.WriteLine( elem.InnerText );
// InnerXml includes the markup of the element.
Console.WriteLine("Display the InnerXml of the element...");
Console.WriteLine(elem.InnerXml);
// Set InnerText to a string that includes markup.
// The markup is escaped.
elem.InnerText = "Text containing <markup/> will have char(<) and char(>) escaped.";
Console.WriteLine( elem.OuterXml );
// Set InnerXml to a string that includes markup.
// The markup is not escaped.
elem.InnerXml = "Text containing <markup/>.";
Console.WriteLine( elem.OuterXml );
}
}Item:通过标签名称来获取子元素,返回XmlElement类型,感觉是非常好用的方法。示例:
using System;
using System.IO;
using System.Xml;
public class Sample {
public static void Main() {
XmlDocument doc = new XmlDocument();
doc.LoadXml("<book ISBN='1-861001-57-5'>" +
"<title>Pride And Prejudice</title>" +
"<price>19.95</price>" +
"</book>");
XmlNode root = doc.FirstChild;
Console.WriteLine("Display the title element...");
Console.WriteLine(root["title"].OuterXml);
}
}Name:返回标签名称。
2. 常用成员函数
GetAttribute:通过属性名称来获取属性,直接返回属性内容。HasAttribute:在get之前,先调用一下这个函数确认是否有叫这个名称的属性。示例:
using System;
using System.IO;
using System.Xml;
public class Sample
{
public static void Main()
{
XmlDocument doc = new XmlDocument();
doc.LoadXml("<book genre='novel' ISBN='1-861001-57-5'>" +
"<title>Pride And Prejudice</title>" +
"</book>");
XmlElement root = doc.DocumentElement;
// Check to see if the element has a genre attribute.
if (root.HasAttribute("genre")){
String genre = root.GetAttribute("genre");
Console.WriteLine(genre);
}
}
}GetElementsByTagName:通过标签名称来获取一个列表(XmlNodeList类型),存储所有同名的元素节点。这个方法继承自XmlNode。示例:
using System;
using System.IO;
using System.Xml;
public class Sample
{
public static void Main()
{
XmlDocument doc = new XmlDocument();
doc.Load("2books.xml");
// Get and display all the book titles.
XmlElement root = doc.DocumentElement;
XmlNodeList elemList = root.GetElementsByTagName("title");
for (int i=0; i < elemList.Count; i++)
{
Console.WriteLine(elemList[i].InnerXml);
}
}
}示例使用文件books.xml<?xml version='1.0'?> <!-- This file represents a fragment of a book store inventory dat 4000 abase --> <bookstore> <book genre="autobiography" publicationdate="1981" ISBN="1-861003-11-0"> <title>The Autobiography of Benjamin Franklin</title> <author> <first-name>Benjamin</first-name> <last-name>Franklin</last-name> </author> <price>8.99</price> </book> <book genre="novel" publicationdate="1967" ISBN="0-201-63361-2"> <title>The Confidence Man</title> <author> <first-name>Herman</first-name> <last-name>Melville</last-name> </author> <price>11.99</price> </book> <book genre="philosophy" publicationdate="1991" ISBN="1-861001-57-6"> <title>The Gorgias</title> <author> <name>Plato</name> </author> <price>9.99</price> </book> </bookstore>
GetEnumerator:获取循环访问当前节点中子节点的枚举。(相当准确的定义!之前一直不太明白枚举的含义,这么看来十分像迭代器。)示例:文件输入为books.xml,同上
using System;
using System.Collections;
using System.Xml;
public class Sample {
public static void Main() {
XmlDocument doc = new XmlDocument();
doc.Load("books.xml");
Console.WriteLine("Display all the books...");
XmlNode root = doc.DocumentElement;
IEnumerator ienum = root.GetEnumerator();
XmlNode book;
while (ienum.MoveNext())
{
book = (XmlNode) ienum.Current;
Console.WriteLine(book.OuterXml);
Console.WriteLine();
}
}
}SelectSingleNode:一个获取节点的函数,参数是一个XPath表达式。XPath是一种查询语言,可以从XML文档中选择特定的节点或元素,以进行处理。这个函数也可以用成和Item一样的效果,事实上,它比Item的功能要强很多。这一系列的函数还有返回节点列表的SelectNodes,并且XmlDocument也有这个方法。示例:
using System;
using System.IO;
using System.Xml;
public class Sample {
public static void Main() {
XmlDocument doc = new XmlDocument();
doc.Load("booksort.xml");
XmlNode book;
XmlNode root = doc.DocumentElement;
book=root.SelectSingleNode("descendant::book[author/last-name='Austen']");
//Change the price on the book.
book.LastChild.InnerText="15.95";
Console.WriteLine("Display the modified XML document....");
doc.Save(Console.Out);
}
}文件输入为booksort.xml<?xml version="1.0"?> <!-- A fragment of a book store inventory database --> <bookstore xmlns:bk="urn:samples"> <book genre="novel" publicationdate="1997" bk:ISBN="1-861001-57-8"> <title>Pride And Prejudice</title> <author> <first-name>Jane</first-name> <last-name>Austen</last-name> </author> <price>24.95</price> </book> <book genre="novel" publicationdate="1992" bk:ISBN="1-861002-30-1"> <title>The Handmaid's Tale</title> <author> <first-name>Margaret</first-name> <last-name>Atwood</last-name> </author> <price>29.95</price> </book> <book genre="novel" publicationdate="1991" bk:ISBN="1-861001-57-6"> <title>Emma</title> <author> <first-name>Jane</first-name> <last-name>Austen</last-name> </author> <price>19.95</price> </book> <book genre="novel" publicationdate="1982" bk:ISBN="1-861001-45-3"> <title>Sense and Sensibility</title> <author> <first-name>Jane</first-name> <last-name>Austen</last-name> </author> <price>19.95</price> </book> </bookstore> 更改了第一个的 Jane Austen 本书的价格:
以上示例全部是MSDN上的,我觉得MSDN虽然给出了示例代码和少许解释,但如果不自己运行并尝试修改,无法完全理解一些方法的使用。此外,本文列出的方法都是访问器,修改器的语法与访问器很相似,在此基础上并不难掌握。
参考文献:
1. MSDN:https://msdn.microsoft.com/zh-cn/library/system.xml(v=vs.110).aspx
2. 内格尔李铭. C#高级编程[M]. 清华大学出版社, 2013.
3. W3Cschool:
http://www.w3cschool.cn/xml/ http://www.w3cschool.cn/xmldom/
4. http://blog.csdn.net/tiemufeng1122/article/details/6723764/

相关文章推荐
- 大XML文件解析入库的一个方法
- Android开发之XML文件的解析的三种方法
- 在config配置文件添加iis的Mime类型,检测文件中是否存在添加语句,使用xml解析方法
- jQuery解析XML文件同时动态增加js文件的方法
- php的SimpleXML方法读写XML接口文件实例解析
- PHP解析XML的一些方法
- Android开发之XML文件的解析的三种方法
- php的SimpleXML方法读写XML接口文件实例解析
- php的SimpleXML方法读写XML接口文件实例解析
- c#中XML解析文件出错解决方法
- 复习struts2之基于XML配置文件实现指定方法的输入校验以及基于XML校验的一些特点
- PHP解析XML的一些方法
- Symbian OS下解析XML文档的一些方法
- Android开发之XML文件的解析的三种方法
- c#中XML解析文件出错解决方法
- 复习struts2之基于XML配置文件实现指定方法的输入校验以及基于XML校验的一些特点
- cocos2d-x 当中访问WebServer服务器的方法,以及解析XML文件.
- Spring ClassPathXmlApplicationContext和FileSystemXmlApplicationContext读取配置文件的方法
- Android开发之XML文件的解析的三种方法
- Android开发之XML文件的解析的三种方法