推荐系统之基于用户的协调过滤
2017-05-04 18:17
393 查看
在如何海量的数据时代,如何从海量的商品中选择相关产品?在1100万首iTunes曲目中,肯定有一部分音乐是你特别喜爱的,那么该如何找到它们呢?
- 专家点评推荐(影评家)
- 通过商品本身寻找(我喜欢披头士的一张专辑,所以会认为他们的另一张专辑也不错)
数据挖掘不仅仅是用来推荐商品,或是单单给商人增加销量,同时也能扩展我们的能力,让我们能够处理海量的数据,如让潘多拉音乐站提供个性化的音乐列表。数据挖掘的重点在于找到数据中的模式。
协调过滤的实现的三步骤:收集数据——找到相似用户和物品——进行推荐
其他浏览过该商品的用户的浏览记录
计算距离的算法有以下几种:
曼哈顿距离

欧几里得距离(利用勾股定理计算两点间的直线距离)
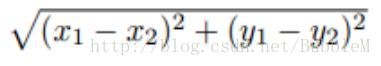
闵可夫斯基(将曼哈顿和欧几里得距离归纳成一个公式)
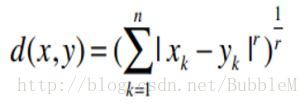
以上三种方式实现代码请访问: https://github.com/BubbleM/Python-Recommended/blob/master/recommend1.py
皮尔逊相关系数(描述两个变量之间的线性相关程度 评价标准之间的差异)
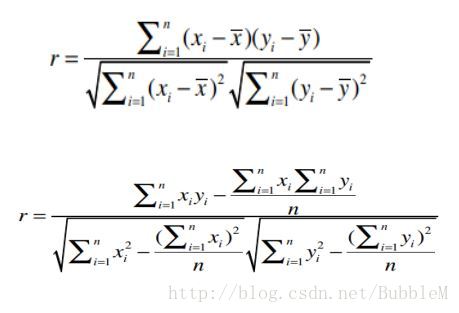
实现:
https://github.com/BubbleM/Python-Recommended/blob/master/recommend2.py
余弦相似度(不足在于并没有很好的解决分数贬值问题)
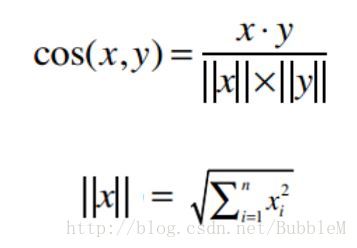
区别:
在数据完整“密集”的情况下使用曼哈顿和欧几里得距离效果最好。
当数据存在“分数膨胀”问题,使用皮尔逊相关系数效果最好。
在数据稀疏,非零值较总体要少得多的情况下使用余弦相似度效果最好。
K最邻近算法
如果只依靠最相似的一个用户来做推荐,这个用户有些特殊的偏好,会直接反映在推荐内容里。解决之一就是找寻多个相似的用户。
实现代码:
https://github.com/BubbleM/Python-Recommended/blob/master/recommend.py
原文请访问:https://github.com/BubbleM/blog/issues/4
- 专家点评推荐(影评家)
- 通过商品本身寻找(我喜欢披头士的一张专辑,所以会认为他们的另一张专辑也不错)
数据挖掘不仅仅是用来推荐商品,或是单单给商人增加销量,同时也能扩展我们的能力,让我们能够处理海量的数据,如让潘多拉音乐站提供个性化的音乐列表。数据挖掘的重点在于找到数据中的模式。
协调过滤
利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。协调过滤的实现的三步骤:收集数据——找到相似用户和物品——进行推荐
数据集来源:
用户的浏览记录其他浏览过该商品的用户的浏览记录
找到相似用户
这里可以用距离表示,即找到距离最近的两个用户。计算距离的算法有以下几种:
曼哈顿距离
欧几里得距离(利用勾股定理计算两点间的直线距离)
闵可夫斯基(将曼哈顿和欧几里得距离归纳成一个公式)
以上三种方式实现代码请访问: https://github.com/BubbleM/Python-Recommended/blob/master/recommend1.py
皮尔逊相关系数(描述两个变量之间的线性相关程度 评价标准之间的差异)
实现:
https://github.com/BubbleM/Python-Recommended/blob/master/recommend2.py
余弦相似度(不足在于并没有很好的解决分数贬值问题)
区别:
在数据完整“密集”的情况下使用曼哈顿和欧几里得距离效果最好。
当数据存在“分数膨胀”问题,使用皮尔逊相关系数效果最好。
在数据稀疏,非零值较总体要少得多的情况下使用余弦相似度效果最好。
K最邻近算法
如果只依靠最相似的一个用户来做推荐,这个用户有些特殊的偏好,会直接反映在推荐内容里。解决之一就是找寻多个相似的用户。
实现代码:
https://github.com/BubbleM/Python-Recommended/blob/master/recommend.py
原文请访问:https://github.com/BubbleM/blog/issues/4

相关文章推荐
- 基于物品的协作性过滤推荐系统(为用户推荐影片)
- 【推荐系统】协同过滤之基于用户的最近邻推荐
- 推荐系统-通过数据挖掘算法协同过滤讨论基于内容和用户的区别
- 基于用户的协作性过滤推荐系统(为用户推荐影片)
- 《推荐系统实战》-基于用户的系统过滤推荐
- 基于用户协同过滤的推荐系统算法,python 实现
- 基于用户的协作性过滤推荐系统(找出相似的电影)
- 推荐系统——协调过滤
- 推荐系统-基于用户的最近邻协同过滤算法(MovieLens数据集)
- 推荐系统实践--基于用户的协同过滤算法
- 数据挖掘笔记-基于用户协同过滤推荐的简单实现
- 基于用户行为的推荐系统
- 基于用户的deviantArt推荐系统(SVD因子分解)
- 基于用户且带有偏好值的推荐系统
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
- 一个简单的基于用户的推荐系统+缓存机制
- 推荐系统-基于用户的最近邻协同过滤算法(MovieLens数据集)
- Postfix-2.11+Dovecot-2.0.9+MySQL+Cyrus-sasl+Extmail-1.2实现基于虚拟用户的邮件系统架构 推荐
- 推荐系统(二) —— 利用用户行为数据 —— 基于领域的算法
- 在RHEL5下构建基于系统用户的Postfix邮件系统 推荐