机器学习-周志华-个人练习4.4
2017-04-28 22:21
369 查看
4.4 试编程实现基于基尼指数进行划分选择的决策树算法,为表4.2中数据生成预剪枝、后剪枝决策树,并与未剪枝决策树进行比较。
本题未剪枝决策树与4.3题基本一致,同时,由于表4.2数据没有连续属性,因此本题的代码不能处理具有连续属性的数据XD。事实上,在本题用基尼指数与用基于信息增益的效果是一样的,但由于多个变量可能同时达到最小基尼指数,因此我的代码结果和成图里面的“脐部=凹陷”这一节点采用的是根蒂进行划分(根蒂、色泽同时都是最优属性),这样一来,这个节点对应的验证集精度为1,无论预剪枝还是后剪枝都不能把它剪掉。
这道题的基尼指数我先进行了推导化简,在只有2类的情况下,Gini_ index(D,a)等价于
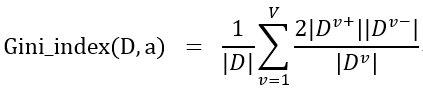
,因此可以其代替原公式。
本题的未剪枝、预剪枝、后剪枝和生成树状结构都较多使用了递归,具体代码与决策树效果如下:
# -*- coding: utf-8 -*-
# exercise 4.4: 基于基尼指数的决策树算法,采用未剪枝,预剪枝,后剪枝处理(无连续属性)
import numpy as np
import igraph as ig
from collections import Counter
import random, copy
def all_class(D): # 判断D中类的个数
return len(np.unique(D[:,-1])) # np.unique用以生成具有不重复元素的数组
def diff_in_attr(D,A_code): # 判断D中样本在当前A_code上是否存在属性取值不同,即各属性只有一个取值
cond = False
for i in A_code: # continuous args are excluded
if len(np.unique(D[:,i])) != 1:
cond = True
break
return cond
def major_class(D): # 票选出D中样本数最多的类
# 本书所给图4.6是利用信息增益划分得到的,在进行预剪枝时,将脐部=稍凹\
# 判定为好瓜和坏瓜具有同样验证集精度和泛化误差,但若直接用22行进行计算\
# 取第一项,则没有考虑到训练集含偶数个例子时,可能出现上述情况,为了和书\
# 上一致,强行让这种情况下的分类取为1,即好瓜
c = Counter(D[:,-1]).most_common()
if len(c) == 1:
return c[0][0]
elif c[0][1] == c[1][1]:
return 1
else:
return c[0][0]
def min_gini(D,A_code):
N = len(D) # 当前样本数
dict_class = {} # 用字典保存类及其所在样本,键为类型,值为类型所含样本
for i in range(N):
if D[i,-1] not in dict_class.keys(): # 为字典添加新类
dict_class[D[i,-1]] = []
dict_class[D[i,-1]].append(int(D[i,0]))
else:
dict_class[D[i,-1]].append(int(D[i,0]))
Gini_D_A = {} # 用字典保存在某一属性下的属性值及其所在样本,键为属性取值,值为对应样本
for a in A_code:
# A中的离散属性,在后期的迭代中,属性a可能会变得不连续
dict_attr = {}
for i in range(N):
if D[i,a] not in dict_attr.keys(): # 为字典添加新的属性取值
dict_attr[D[i,a]] = []
dict_attr[D[i,a]].append(int(D[i,0]))
else:
dict_attr[D[i,a]].append(int(D[i,0]))
# 对Gini_index(D,a)变形发现,在只有好瓜和坏瓜这两类时,基尼指数最小等价于
# sigma(v=1到V)求和:(|Dv+| * |Dv-|) / |Dv|最小
Gini_D_A[(a,)] = 0
for av,v in dict_attr.items():
m = len(v) # m为当前属性取值的样本总数,如A_a0包含的样本总数
x2 = len(set(v) & set(dict_class[1.0]))
x1 = m - x2
Gini_D_A[(a,)] += x1 * x2 / m
Gini_D_A_list = sorted(Gini_D_A.items(),key=lambda a: a[1])
best = Gini_D_A_list[0][0]
dict_attr = {}
best = int(best[0])
for i in range(N):
if D[i, best] not in dict_attr.keys():
dict_attr[D[i, best]] = []
dict_attr[D[i, best]].append(int(D[i,0]))
else:
dict_attr[D[i, best]].append(int(D[i,0]))
# 返回对应的属性序号(绝对序号),并返回此属性下对应的取值和所包含的实例的id
return best, dict_attr
def prim_Tree_Generate(D,A_code,full_D):
# 生成未剪枝决策树
if all_class(D) == 1: # case1
return D[0,-1]
if (not A_code) or (not diff_in_attr(D,A_code)): # case2
return major_class(D)
a, di = min_gini(D, A_code)
a_name = '%s%s' % (A[a], major_class(D))
np_tree = {a_name:{}}
all_a = np.unique(full_D[:, a])
new_A_code = A_code[:]
new_A_code.remove(a)
for item in all_a:
if item not in di.keys():
di[item] = []
for av, Dv in di.items():
if Dv:
np_tree[a_name][av] = prim_Tree_Generate(full_D[Dv, :], new_A_code,full_D)
else: # case3
np_tree[a_name][av] = major_class(D)
return np_tree
def pre_Tree_Generate(A_code,train_D,test_D,full_D,pre_correct):
# 生成预剪枝决策树
# pre_correct代表此节点对应的同父的子节点的划分前验证集精度
# 如脐部(heart)取值为1,2,3的节点都应该具有同样的pre_correct
# 对于根节点,其pre_correct需要在函数外提前用major_class()获得,作为参数传入
if all_class(train_D) == 1: # case1
return train_D[0,-1]
if (not A_code) or (not diff_in_attr(train_D,A_code)): # case2
return major_class(train_D)
a, di = min_gini(train_D,A_code)
all_a = np.unique(full_D[:, a])
for item in all_a:
if item not in di.keys():
di[item] = []
# 比较此节点划分前后的泛化能力
n, post_correct = len(test_D),0
node_label = major_class(train_D)
judge,test_D_v = {},{}
for av, Dv in di.items():
if not Dv:
judge[av] = major_class(train_D) # 节点的多数类
else:
judge[av] = major_class(full_D[Dv, :]) # 各子集的多数类
for i in range(n):
if judge[test_D[i,a]] == test_D[i,-1]:
post_correct += 1 # 划分节点后的正确率
if test_D[i, a] not in test_D_v.keys():
test_D_v[test_D[i, a]] = []
test_D_v[test_D[i, a]].append(int(test_D[i, 0]))
else:
test_D_v[test_D[i, a]].append(int(test_D[i, 0]))
post_correct /= n
if post_correct <= pre_correct: # 决定是否剪枝
return node_label
else:
a_name = '%s%s' % (A[a], major_class(train_D))
tree = {a_name: {}}
new_A_code = A_code[:]
new_A_code.remove(a)
for av, Dv in di.items():
if Dv:
tdv = test_D_v[av]
tree[a_name][av] = pre_Tree_Generate(new_A_code,full_D[Dv,:],full_D[tdv,:],full_D,post_correct)
else: # case3
tree[a_name][av] = major_class(train_D)
return tree
def d_tree(tree,test_D,anti_A,full_D):
# 提供给tree_update()函数进行调用,为后剪枝函数1
# 返回未剪枝决策树tree中,各节点包含的测试集test_D内实例形成的字典,形式与决策树类似,具体如下:
# {'脐部1': {1: {'根蒂1': {1: [3, 4], 2: [12], 3: []}}, 2: {'根蒂1': {1: [], \
# 2: {'色泽1': {1: [], 2: {'纹理1': {1: [7], 2: [8], 3: []}}, 3: []}}, 3: []}}, 3: [10, 11]}}
dimension = len(test_D.shape)
if type(tree).__name__ != 'dict':
id = []
if dimension == 1:
id.append(test_D[0])
for i in range(len(test_D)):
id.append(test_D[i,0])
return id
a, di = list(tree.items())[0]
data_tree = {a:{}}
acode = anti_A[a[:-1]]
for av, dv in di.items():
if type(dv).__name__ == 'int':
data_tree[a][av] = []
if dimension == 1:
if test_D[acode] == av:
data_tree[a][av].append(test_D[0])
else:
for row in range(len(test_D)):
if test_D[row, acode] == av:
data_tree[a][av].append(test_D[row, 0])
else:
DV = []
if dimension == 1:
if test_D[acode] == av:
DV.append(test_D[0])
else:
for row in range(len(test_D)):
if test_D[row, acode] == av:
DV.append(test_D[row, 0])
data_tree[a][av] = d_tree(dv,full_D[DV,:],anti_A,full_D)
return data_tree
def tree_update(data_tree, edit_tree, full_D, pa_tree=None, pa_d_tree=None, pa_a=None):
# 提供给post_tree()函数进行调用,为后剪枝函数2
# 利用当前决策树和各节点所含测试例进行后剪枝,具体就是对当前树中所有叶节点判断是否剪枝,若是,则\
# 一次性将所有满足剪枝条件的叶节点进行剪枝处理,就像剥洋葱一样,一次剥掉一层而不管这一层的面积
# data_tree为测试集在节点中分布的字典,edit_tree为要进行单次剪枝的决策树
# pa_tree代表包含当前edit_tree的父节点的字典,pa_d_tree代表包含\
# 当前data_tree的父节点的字典,pa_a为指向当前edit_tree的键,\
# 例如:edit_tree={'色泽1': {1: 1, 2: 1, 3: 1}},\
# 则对应的pa_tree={'根蒂1': {1: 0, 2: {'色泽1': {1: 1, 2: 1, 3: 1}}, 3: 1}}, \
# pa_a=2, pa_d_tree同理
a = list(edit_tree.keys())[0]
d = data_tree[a]
# print(d)
flag,node_data = [],[]
for datum in list(d.values()):
if type(datum).__name__ == 'dict':
flag.append(datum)
break
if not flag:
pre, post = 0, 0
for av, dv in d.items():
if dv:
for i in dv:
node_data.append(i)
if full_D[i,-1] == edit_tree[a][av]:
pre += 1
if full_D[i,-1] == int(a[-1]):
post += 1
if post > pre and pa_tree:
# 取>=时,根据奥卡姆剃刀准则,性能不下降就剪枝
# 剪枝最后的决策树为{'脐部1': {1: {'根蒂1': {1: 1, 2: 0, 3: 1}}, 2: 1, 3: 0}}
# 相应地,各节点包含的测试集实例为\
# {'脐部1': {1: {'根蒂1': {1: [3, 4], 2: [12], 3: []}}, 2: [7, 8], 3: [10, 11]}}
# 取>时,与书上的例子一致,性能提升才剪枝
# 最终决策树为{'脐部1': {1: {'根蒂1': {1: 1, 2: 0, 3: 1}}, \
# 2: {'根蒂1': {1: 0, 2: {'色泽1': {1: 1, 2: 1, 3: 1}}, 3: 1}}, 3: 0}}
# 各节点包含的测试集实例\
# {'脐部1': {1: {'根蒂1': {1: [3, 4], 2: [12], 3: []}}, 2: {'根蒂1': {1: [], \
# 2: {'色泽1': {1: [], 2: [7, 8], 3: []}}, 3: []}}, 3: [10, 11]}}
pa_tree[pa_a] = int(a[-1])
pa_d_tree[pa_a] = node_data
else:
for av, dv in edit_tree[a].items():
new_d_tree = data_tree[a][av]
if type(dv).__name__ == 'dict' and new_d_tree:
tree_update(new_d_tree, dv, full_D, pa_tree=edit_tree[a], pa_d_tree=data_tree[a], pa_a=av)
return data_tree, edit_tree
def post_tree(data_tree, edit_tree, D):
# 返回最终的后剪枝处理完成的决策树,为后剪枝函数3
# 之所以要多次调用tree_update(),是因为tree_update()剪枝后形成的新叶节点仍然满足剪枝条件
old_l = copy.deepcopy(edit_tree)
dd,ll = tree_update(data_tree, edit_tree, D)
if old_l != ll:
return post_tree(dd, ll, D)
else:
return ll
def Tree_draw(tree_item, g, node=0):
# 获取树节点的拓扑关系并绘图
rand = random.randint(100,999)
attr, cond = tree_item
u_attr = '%s_%s' % (attr, rand) # 保证各节点name的独特性,在后面用来查找此节点
g.add_vertex(u_attr)
new_node = g.vs.find(name=u_attr).index
this_label = str(attr)
if len(this_label) > 1: # 如果节点名长度大于1,则类似“根蒂1”,应该将其显示为“根蒂”
this_label = this_label[:-1]
g.vs[new_node]['label'] = this_label
g.add_edge(node, new_node)
if type(cond).__name__ == 'dict':
for item in list(cond.items()):
Tree_draw(item, g, new_node)
else:
u_cond = '%s_%s' % (rand, cond)
g.add_vertex(u_cond)
end_node = g.vs.find(name=u_cond).index
g.vs[end_node]['label'] = str(int(cond))
g.add_edge(new_node, end_node)
return g
# ###数据准备及预处理###
D = np.array([
[0, 1, 1, 1, 1, 1, 1, 1],
[1, 2, 1, 2, 1, 1, 1, 1],
[2, 2, 1, 1, 1, 1, 1, 1],
[3, 1, 1, 2, 1, 1, 1, 1],
[4, 3, 1, 1, 1, 1, 1, 1],
[5, 1, 2, 1, 1, 2, 2, 1],
[6, 2, 2, 1, 2, 2, 2, 1],
[7, 2, 2, 1, 1, 2, 1, 1],
[8, 2, 2, 2, 2, 2, 1, 0],
[9, 1, 3, 3, 1, 3, 2, 0],
[10, 3, 3, 3, 3, 3, 1, 0],
[11, 3, 1, 1, 3, 3, 2, 0],
[12, 1, 2, 1, 2, 1, 1, 0],
[13, 3, 2, 2, 2, 1, 1, 0],
[14, 2, 2, 1, 1, 2, 2, 0],
[15, 3, 1, 1, 3, 3, 1, 0],
[16, 1, 1, 2, 2, 2, 1, 0]])
train_D = D[[0, 1, 2, 5, 6, 9, 13, 14, 15, 16], :]
test_D = D[[3, 4, 7, 8, 10, 11, 12], :]
A = {0:'id',1:'色泽',2:'根蒂',3:'敲声',4:'纹理',5:'脐部',6:'触感',7:'好瓜'}
A_code = list(range(1,len(A)-1)) # A_code = [1, 2, 3, 4, 5, 6]
anti_A = {'id':0,'色泽':1,'根蒂':2,'敲声':3,'纹理':4,'脐部':5,'触感':6,'好瓜':7}
# ###################
# ########未剪枝#######
tree = prim_Tree_Generate(train_D,A_code,D)
# ####################
# ########预剪枝#######
# n,node_label,init_correct = len(test_D),major_class(train_D),0
# for i in range(n):
# if test_D[i, -1] == node_label:
# init_correct += 1 # 划分节点前的正确个数
# init_correct /= n # 初始验证集精度
# tree = pre_Tree_Generate(A_code,train_D,test_D,D,init_correct)
# ###################
# #######后剪枝#######
# edit_tree = prim_Tree_Generate(train_D,A_code,D)
# data_tree = d_tree(edit_tree,test_D,anti_A,D)
# tree = post_tree(data_tree, edit_tree, D)
# ###################
print(tree)
# #########生成决策树图#########
init_items = list(tree.items())[0]
g = ig.Graph()
g.add_vertex('Source')
g.vs[0]['label'] = '*'
s = Tree_draw(init_items, g, node=0)
# ###########################
# ########修饰决策树图表########
def dyer(x):
if x == 2:
return 'white'
elif x == 1:
return 'powderblue'
else:
return 'pink'
dye = list(map(dyer, s.vs.degree()))
label_size_map = {'white':15, 'pink':18, 'powderblue':24}
v_size_map = {'white':16, 'pink':30, 'powderblue':26}
label_size = [label_size_map[i] for i in dye]
v_size = [v_size_map[i] for i in dye]
edge_width = [2]*(len(dye)-1)
edge_width[0] = 4
my_lay = g.layout_reingold_tilford(root=[0])
style = {"vertex_size":v_size, "vertex_shape":'circle', "vertex_color":dye,
"vertex_label_size":label_size, "edge_width": edge_width,
"layout":my_lay, "bbox":(600,500), "margin":25}
# ###########################
ig.plot(s,'prim_tree.png', **style) # 决策树可视化及保存
未剪枝决策树:
{'脐部1': {1: {'根蒂1': {1: 1, 2: 0, 3: 1}}, 2: {'根蒂1': {1: 0, 2: {'色泽1': {1: 1, 2: {'纹理1': {1: 0, 2: 1, 3: 1}}, 3: 1}}, 3: 1}}, 3: 0}}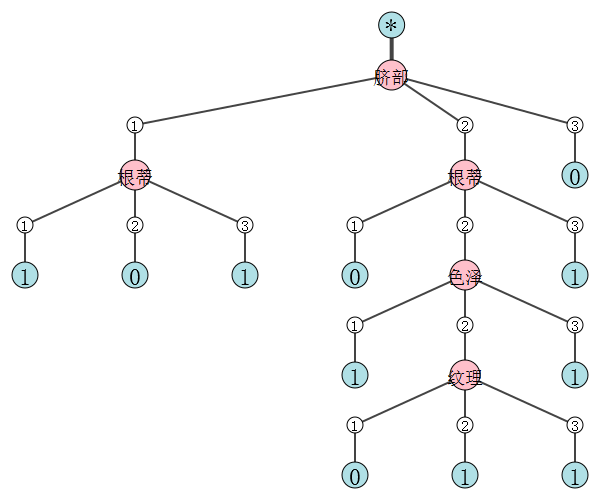
预剪枝决策树:
{'脐部': {1: {'根蒂': {1: 1, 2: 0, 3: 1}}, 2: 1, 3: 0}}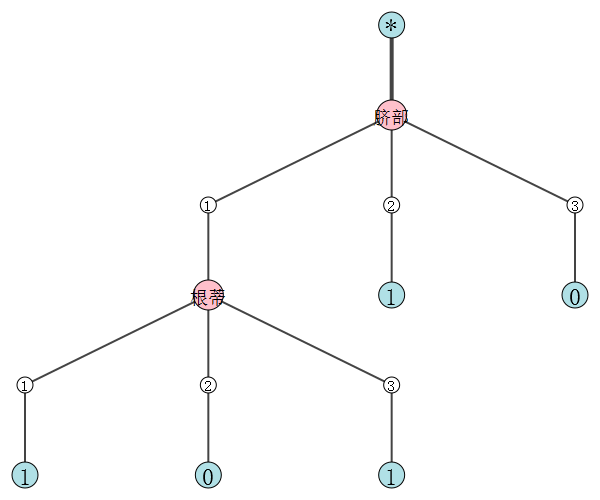
后剪枝决策树:
{'脐部1': {1: {'根蒂1': {1: 1, 2: 0, 3: 1}}, 2: {'根蒂1': {1: 0, 2: {'色泽1': {1: 1, 2: 1, 3: 1}}, 3: 1}}, 3: 0}}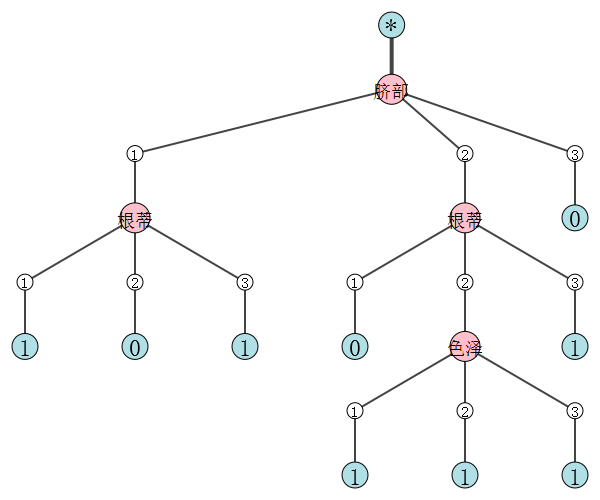

相关文章推荐
- 机器学习(周志华) 个人练习答案7.6
- 机器学习-周志华-个人练习12.4
- 机器学习-周志华-个人练习9.4
- 机器学习-周志华-个人练习9.6
- 机器学习-周志华-个人练习11.1
- 机器学习-周志华-个人练习13.10
- 机器学习-周志华-个人练习8.3和8.5
- 机器学习-周志华-个人练习4.3
- 机器学习-周志华-个人练习13.1
- 机器学习-周志华-个人练习10.1
- 机器学习-周志华-个人练习13.2
- 机器学习-周志华-个人练习10.6
- 周志华《机器学习》课后习题解答系列(四):Ch3.4 - 交叉验证法练习
- 机器学习(周志华版) 第一章习题1.1个人解答
- 机器学习-周志华-个人练习11.3
- 《机器学习》(周志华) 习题3.1-3.3个人笔记
- 机器学习(周志华) 习题3.5 个人笔记
- 决策树ID3基本代码,周志华《机器学习》练习
- 机器学习(周志华) 习题7.3 个人笔记
- 《机器学习》周志华习题4.4答案