聚类算法1-------K-均值(KMeans)算法原理和Python实现
2017-04-28 16:04
423 查看
聚类是一种无监督学习,他将相似对象归到统一族中,将不同对象归到不同族中,相似概念取决于所选择的相似度计算方法。
K-均值算法是最常用的一种聚类算法之一,一下主要介绍K-均值算法的原理和Python实现,参考机器学习实战

计算一下计算距离的公式为欧式距离
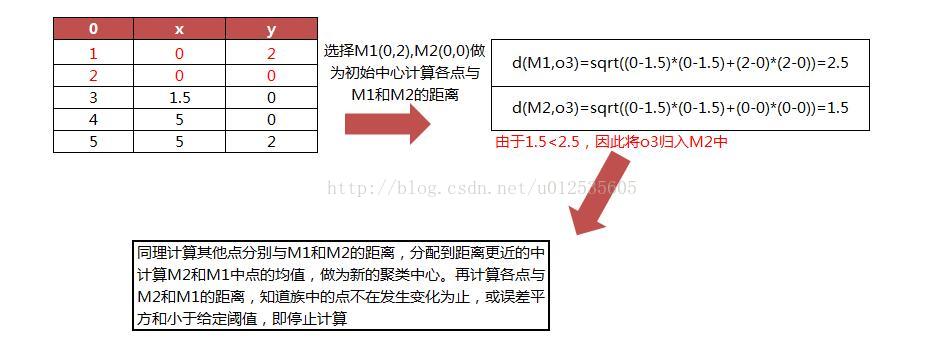
2 K-均值算法实现
输出结果如下,分别为在训练集和测试集上进行的聚类分布
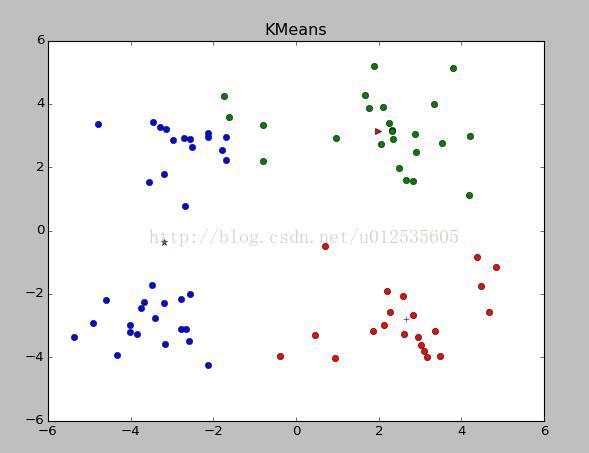
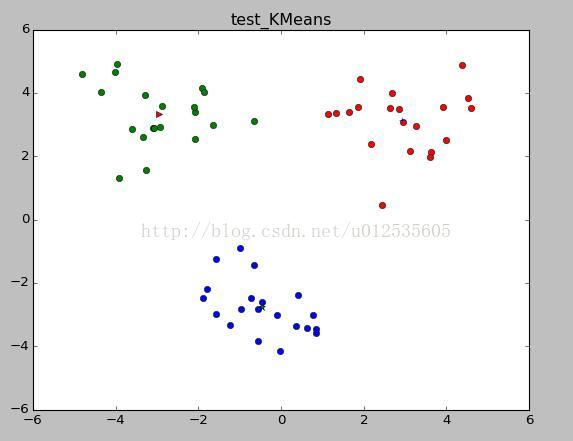
当不知道K值为多少合适,可以先看看原始数据集的分布,根据分布可以大致选择K的数值
改进的聚类算法有二分K-均值
K-均值算法是最常用的一种聚类算法之一,一下主要介绍K-均值算法的原理和Python实现,参考机器学习实战
1 K-均值算法的计算步骤
计算一下计算距离的公式为欧式距离
2 K-均值算法实现
from numpy import *
import matplotlib.pyplot as plt
def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)#文件类型
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float,curLine) #map all elements to float()
dataMat.append(fltLine)
return dataMat
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB)
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))#create centroid mat生成一个k行n列的矩阵
for j in range(n):#create random cluster centers, within bounds of each dimension
minJ = min(dataSet[:,j])#每一列的最小值
rangeJ = float(max(dataSet[:,j]) - minJ)#每一列的最大值
centroids[:,j] = minJ + rangeJ * random.rand(k,1)#生成K行1列的数据大小为0到1
return centroids
#kMeans模型中心
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))#
#create mat to assign data points,目的是存储所属类和距离类中心的距离
#to a centroid, also holds SE of each point
centroids = createCent(dataSet, k)#生成聚类中心
clusterChanged = True#聚类改变标识,族索引和存储误差
while clusterChanged:#当聚类中心为True时,
clusterChanged = False
for i in range(m):#for each data point assign it to the closest centroid
minDist = 100000#赋初值
minIndex = 0#赋初值
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i,0] != minIndex:
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2#存储所属类别和距离列别的距离
for cent in range(k):#更新聚类中心
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#首先通过数组过滤来获得给定族的所有点,,
centroids[cent,:] = mean(ptsInClust, axis=0) #assign centroid to mean然后计算所有点的均值
return centroids, clusterAssment
#显示分类效果,目测评估
def show(dataSet,k,centroids,clusterAssment):
numSamples,dim=dataSet.shape
mark=['or','ob','og','ok']
for i in xrange(numSamples):
markIndex=int(clusterAssment[i,0])
plt.plot(dataSet[i,0],dataSet[i,1],mark[markIndex])#不同类显示不同颜色
mark=['+','*','>','o']
for i in range(k):
plt.plot(centroids[i,0],centroids[i,1], mark[i])#聚类中心显示不同标示
plt.show()
plt.title("test_KMeans")
#测试分类结果
def test_Kmeans(filename,k):
dataSet=[]
fileIn=open(filename)
for line in fileIn:
lineArr=line.strip().split('\t')
dataSet.append([float(lineArr[0]),float(lineArr[1])])
dataSet=mat(dataSet)
centrios,clusterAssment=kMeans(dataSet,k)
show(dataSet,k,centrios,clusterAssment)
#主函数
def main():
test_Kmeans('testSet2.txt',3)
if __name__=='__main__':
main()输出结果如下,分别为在训练集和测试集上进行的聚类分布
当不知道K值为多少合适,可以先看看原始数据集的分布,根据分布可以大致选择K的数值
改进的聚类算法有二分K-均值
| 将所有点看成一个族, |
| 当族数目小于K时, |
| 对于每一个族 |
| 计算总误差 |
| 在给定的族上进行K-均值聚类 |
| 选择使得误差最小的那个族进行划分操作 |

相关文章推荐
- 机器学习经典算法详解及Python实现--聚类及K均值、二分K-均值聚类算法
- 机器学习经典算法详解及Python实现--聚类及K均值、二分K-均值聚类算法
- Python实现kMeans(k均值聚类)
- 用户地理位置的聚类算法实现—基于DBSCAN和Kmeans的混合算法
- 理解Logistic回归算法原理与Python实现
- 利用python的KMeans和PCA包实现聚类算法
- 决策树之CART算法原理及python实现
- 《机器学习实战》之二分K-均值聚类算法的python实现
- bandit算法原理及Python实现
- 分类算法-----朴素贝叶斯原理和python实现
- 神经网络中 BP 算法的原理与 PYTHON 实现源码解析
- 聚类分析的K均值算法(Python实现)
- KNN算法原理(python代码实现)
- bandit算法原理及Python实现
- ID3决策树的算法原理与python实现
- python实现k均值算法示例(k均值聚类算法)
- 《机器学习实战》之K-均值聚类算法的python实现
- 二分K均值算法原理及Spark MLlib调用实例(Scala/Java/Python)
- 感知机算法原理(PLA原理)及 Python 实现
- 聚类之均值聚类(k-means)算法的python实现