好玩的API调用之---天气预报的API调用与爬虫
2017-04-26 08:53
218 查看
更多技术文章请访问我的个人博客http://www.rain1024.com



更多技术文章请访问我的个人博客http://www.rain1024.com
好玩的API调用之—天气预报的API调用与爬虫
平时写程序经常需要用到一些服务,像翻译,天气预报,星座什么的,我一般都是用Python写个爬虫去提供这些服务的网站爬数据,但是有些网站对爬虫有很多限制,一些关键字会定时更改,就像中国天气网经常变更HTML标签的class值,这就需要时常维护爬虫,而聚合数据API只对普通用户提供一个免费API接口,简直垃圾,而网上的一些网站其实有开放的API供开发者调用,所以我想着把自己发现的好玩的API和自己写的爬虫写个博客专题供大家参考,我会继续补充和维护。
第四个专题是关于天气预报的API调用与爬虫,聚合数据里的天气预报接口还收费,真是lj,我一开始用爬虫爬中国天气网里的数据进行分析,后来发现了和风天气这个良心网站,不仅提供免费的接口,而且天气预报数据也很多很丰富。今天就写中国天气网的爬虫和和风天气的api调用。
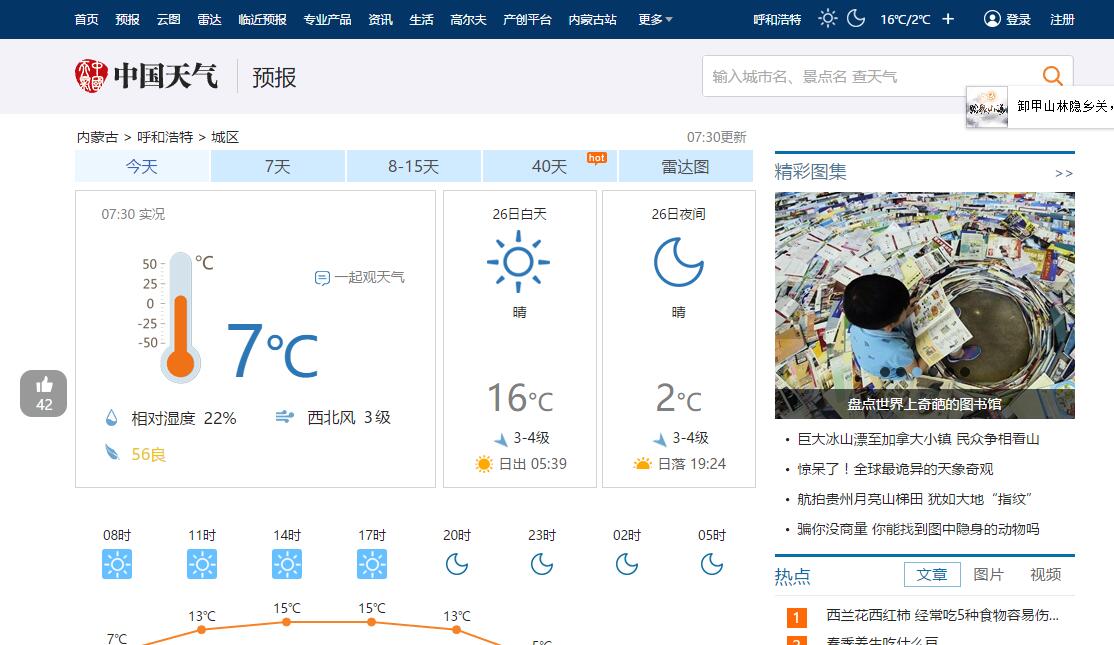
1.中国天气网的网址http://www.weather.com.cn/,先在里面找到自己的城市,然后把网址复制下来,就像我的是呼和浩特市http://www.weather.com.cn/weather1d/101080101.shtml,就是下图这样的。
下面是我爬虫的代码,就不做详细解释。
#-*- coding=utf8 -*-
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import urllib2
from bs4 import BeautifulSoup
import time
def download(url,headers):
try:
request = urllib2.Request(url,headers=headers)
html = urllib2.urlopen(request).read()
# html = urllib2.urlopen(url).read()
except urllib2.URLError as e:
print "error"
print e.code #可以打印出来错误代号如404。
print e.reason #可以捕获异常
html = None
return html
def save(html):
f = open('thefile.txt', 'w')
f.write(html)
f.close()
def read_file():
f = open('thefile.txt', 'r')
html = f.read()
f.close()
return html
def get_html(url):
User_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0'
headers = {'User_agent': User_agent}
html = download(url, headers)
save(html)
def weather():
url = 'http://www.weather.com.cn/weather/101080101.shtml'
get_html(url)
html = read_file()
soup = BeautifulSoup(html)
text = ""
text = text + "明天的天气是:" + soup.find('li', class_='sky skyid lv1').p.string + "\n"
text = text + "最高温度:" + soup.find('li', class_='sky skyid lv1').span.string + "最低温度:" + soup.find('li',
class_='sky skyid lv1').i.string + "\n"
# print soup.find('li',class_='sky skyid lv2').p.string
# print soup.find('li',class_='sky skyid lv2').span.string
# print soup.find('li',class_='sky skyid lv2').i.string
html = soup.find('li', class_='sky skyid lv1')
html2 = soup.find_all('div', class_='hide')[1]
soup = BeautifulSoup(str(html))
text = text + "明天的风是:" + soup.find_all('i')[1].string + '\n'
# print soup.find_all('i')[1].string
soup = BeautifulSoup(str(html2))
text = text + "而紫外线指数是:" + soup.find_all('span')[0].string + " 建议:" + soup.find_all('p')[0].string + '\n'
text = text + "当然还有感冒指数:" + soup.find_all('span')[1].string + " 建议:" + soup.find_all('p')[1].string + '\n'
text = text + "最后是穿衣指数:" + soup.find_all('span')[2].string + " " + soup.find_all('p')[2].string + '\n'
# print soup.find_all('span')[1].string
# print soup.find_all('span')[0].string
# print soup.find_all('p')[0].string
return text
if __name__=='__main__':
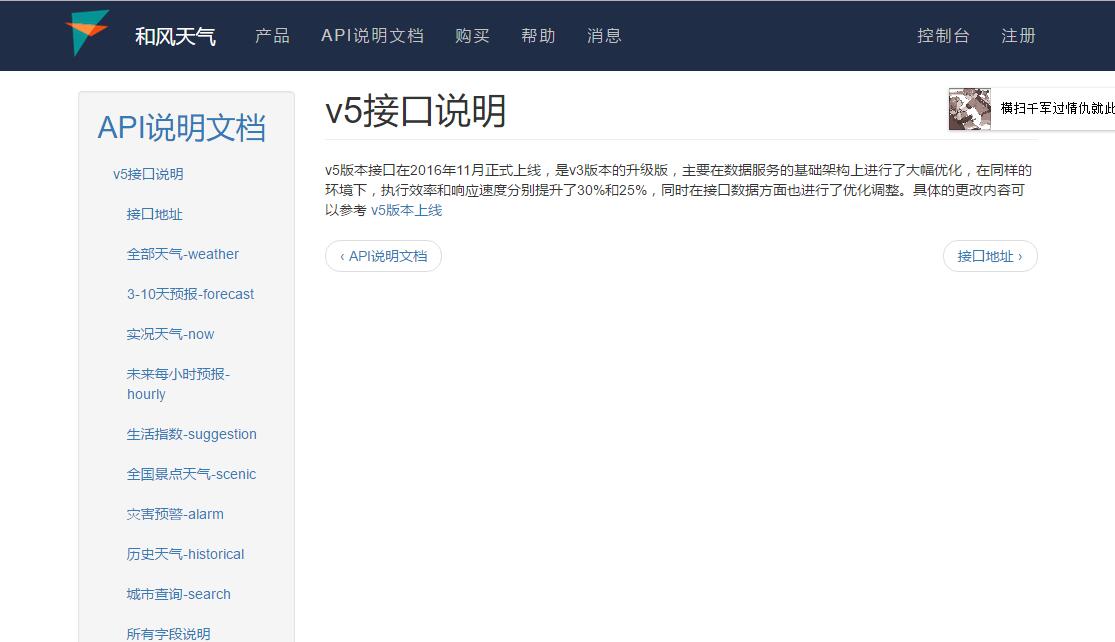
weather_text = weather()2.打开和风网站,网址是这个https://www.heweather.com,然后注册账号,找到自己的KEY,再打开这个API说明。
可以自己参考API这几种数据,我只使用的3-10天气预报和生活指数,还有天气图片。因为和风网站返回的是json格式数据,如下图。
我是使用Python做数据的解析,各种数据已经提取出来,后面都有注释,下面是代码
#-*- coding=utf8 -*-
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import urllib2
import json
import re
def download(url):
html = urllib2.urlopen(url)
return html.read()
def weather():
# all全部的天气数据
all_url = 'https://free-api.heweather.com/v5/weather?city=CN101080101&key=5c043b56de9f4371b0c7f8bee8f5b75e'
# 3天预报
forecast_url = 'https://free-api.heweather.com/v5/forecast?city=CN101080101&key=5c043b56de9f4371b0c7f8bee8f5b75e'
#生活指数
sugg_url = 'https://free-api.heweather.com/v5/suggestion?city=CN101080101&key=5c043b56de9f4371b0c7f8bee8f5b75e'
# 天气图标
photo_url = 'https://cdn.heweather.com/cond_icon/100.png'
#天气情况的内容提取------------开始
html = download(forecast_url)
max_tmp = re.findall('max":"(.*?)"', html)[0] #最高温度
min_tmp = re.findall('min":"(.*?)"', html)[0] #最低温度
photo = re.findall('code_d":"(.*?)"', html)[0] #天气图片
txt_d = re.findall('txt_d":"(.*?)"', html)[0] #天气情况
dir = re.findall('dir":"(.*?)"', html)[0] # 风向
sc = re.findall('sc":"(.*?)"', html)[0] # 风力
print max_tmp,min_tmp,photo,txt_d,dir,sc
#生活指数等内容的提取-----------开始
html = download(sugg_url)
brf = re.findall('brf":"(.*?)"', html)
txt = re.findall('txt":"(.*?)"', html)
comf_brf = brf[0]#舒适度指数
comf_txt = txt[0]
cw_brf = brf[1]#洗车指数
cw_txt = txt[1]
drsg_brf = brf[2]#穿衣指数
drsg_txt = txt[2]
flu_brf = brf[3]#感冒指数
flu_txt = txt[3]
sport_brf = brf[4]#运动指数
sport_txt = txt[4]
trav_brf = brf[5]#旅游指数
trav_txt = txt[5]
uv_brf = brf[6]# 紫外线指数
uv_txt = txt[6]
print comf_brf,comf_txt
print cw_brf,cw_txt
print drsg_brf,drsg_txt
print flu_brf,flu_txt
print sport_brf,sport_txt
print trav_brf,trav_txt
print uv_brf,uv_txt
# brf = brf[0].decode('utf-8')
# dict_html = dict(result)
# print dict_html
#json格式无法提取
# json_html = json.loads(html)
# print json_html
# html = str(json_html['HeWeather5'])
# json_html = json.loads(html)
# print json_html['basic']
def main():
weather()
if __name__ == "__main__":
main()数据处理以后的效果
最后还有webServer也提供服务,但需要注册,返回的数据也没有和风天气返回的数据丰富,所以我没使用,有兴趣的可以参考。这是网址http://webservice.36wu.com/weatherService.asmx
更多技术文章请访问我的个人博客http://www.rain1024.com

相关文章推荐
- 好玩的API调用之---星座运势的API与爬虫爬取
- 调用天气预报api
- 爬虫-python调用百度API/requests
- Python爬虫之百度API调用
- Android——调用百度天气API实现天气预报
- python爬虫之百度API调用方法
- 好玩的API调用之---IP地址查询API
- java调用中国天气网api获得天气预报信息的方法
- python调用新浪API爬虫
- 好玩的API调用之---三种翻译API调用
- baiduAPI 免费调用天气预报
- 天气预报调用API
- c# webapi调用友盟u-push接口推送消息
- 通过Jersey客户端API调用REST风格的Web服务
- CSharp Tips:调用API注册和注销Windows Service
- SOCKET API和TCP STATE的对应关系_三次握手(listen,accept,connect)_四次挥手close及TCP延迟确认(调用一次setsockopt函数,设置TCP_QUICK
- 【Tesseract-OCR】在VS2012环境下调用API方法---注意避免名字冲突
- 怎样用Google APIs和Google的应用系统进行集成(3)----调用Google 发现(Discovery)API的RESTful服务
- JPush极光推送 Java调用服务器端API开发