跨语言rpc框架的一种实现方案
2017-04-26 00:00
239 查看
一、前言
微服务架构已成为现在互联网架构的趋势,就国内互联网公司而言,用的比较多服务框架有dubbo/dubbox、motan等, 但是这些框架在语言层面只支持java,而很多互联网公司还存在一些业务使用其他语言开发的,比如笔者所在互联网公司就还存在php、c++甚至是go语言。它们或是想调用java暴露的服务(作为consumer),或是希望自己暴露一个服务被其它语言调用(作为provider)。因此,为诸如dubbo框架提供跨语言支持,就变成了一个具有业务需求和挑战的事情。注意:更改现有的dubbo实现是一种实现跨语言的方式,但是本文的出发点是,在不改变dubbo源码的前体下,实现其他语言的透明接入(比如现在线上已经有了大量的dubbo服务在运行,不可能因为要接入一个新的语言就要全部更新线上应用,这不现实)。
二、跨语言的本质
目前有很多的开源rpc框架都是跨语言的,首先,我们要搞清楚,一个rpc框架要想跨语言,本质是在解决序列化/反序列化的跨语言问题,也就是说,如果rpc框架使用的序列化/反序列化是支持跨语言的,那么这个rpc框架就是跨语言的。支持跨语言的序列化/反序列产品有很多,从序列化后的字节流类型可以分为文本类型序列化和二进制类型序列化,从序列化的使用方式层面可以分为自描述型和基于中间格式型。
下面我就分别以自描述型和基于中间格式型两种类型讨论这两种序列化的区别。
1、自描述型
所谓的自描述型,指的是在序列化的字节流(无论是文本类型还是二进制类型最终都是字节流)里,有着完整的对象类型信息(对象的类型全限定名)和属性信息(指的是属性的位置、类型和值),也就是在不依赖任何外界描述信息的前提下,只要拿到这个二进制流,就可以还原(反序列化)出原始对象。类似的序列化/反序列化产品还是比较多的,诸如:hessian(二进制型)、json(文本型)、xml(文本型)等。对于json和xml大家都不陌生,这里着重看一下hessian。
首先看一下hessian支持的数据类型:
raw binary data boolean 64-bit millisecond date 64-bit double 32-bit int 64-bit long null UTF8-encoded string list for lists and arrays map for maps and dictionaries object for objects
hessian在字节流中使用不同的字母表示不同的数据类型,比如要表示一个int,那么在序列化后的字节流中,该int会表示为:
'I' b3 b2 b1 b0
'I'表示这是一个int类型,后面为四个字节的int值。
比如现在有一个对象Person,java 定义如下:
public class Person{
private int age = 15;
private String name = "heike";
}使用hessian将其序列化后的字节流为(假设Person类全限定名为com.heikehuajia.test.Person):
M**com.heikehuajia.test.PersonS**nameS**heikeS**ageI**b3 b2 b1 b0 z
注:上面的*和b3 b2 b1 b0都表示不可打印的二进制。
从上面的字节流可以看出,字节流清晰的表达了Person类的类型和该类含有的属性信息,因此只要按照规定格式便可以将其反序列化出来。
2、基于中间格式型
基于中间格式是目前比较流行的序列化方式,比如google的protocolbuf、facebook的thrift等等,它们在使用时都需要事先定义一个中间格式文件,然后使用不同语言的生成工具生成相应语言的可序列化类。比如在protocolbuf中,要序列化上述的Person对象,需要定义一个.proto文件,文件内容如下:message Person {
required string name = 1;
required int32 age = 2;
}使用相应语言的生成工具生成可序列化类之后,便可以调用SerializeToString、ParseFromString、SerializeToOstream、ParseFromIstream进行对象的序列化和反序列化。
可以看到,基于中间格式的序列化在跨语言方面有着天然的优势和方便性,但是它的缺点就是格式的每一次变更(不兼容的变更)都需要重新生成所有传输实体,而且会对框架和上层的业务代码造成侵入(业务方)。
三、跨语言解决方案
1、序列化和反序列化
无论是使用自描述型还是基于中间格式型的跨语言序列化,最终目的都是将要传输的实体序列化和还原,但是有些情况下就不适合使用中间格式的序列化方式,比如,在dubbo中,最终被序列化的传输实体其实就是RpcInvocation对象(以dubbo协议而言),该对象定义如下:public class RpcInvocation implements Invocation, Serializable {
private static final long serialVersionUID = -4355285085441097045L;
private String methodName;
private Class<?>[] parameterTypes;
private Object[] arguments;
private Map<String, String> attachments;
private transient Invoker<?> invoker;
}可以看到,要想使用诸如protocol buf,必须使用message来定义RpcInvocation的格式,但是RpcInvocation中的arguments又是和业务相关的(业务来定义),类型是不确定的,也就是说,框架层无法预先定义RpcInvocation的格式,这也是导致dubbo无法使用protocolbuf的原因之一。而诸如grpc之类的框架,它的参数和返回值(都只有一个)本身就是作为最外层对象使用protocol buf生成的(http的request和response),因此比较适合使用protocol buf。
因此,对于诸如dubbo之类的SOA框架而言,可选的只有自描述型的跨语言序列化方案,比如json、hessian等。
2、泛化与非泛化
用过dubbo的人都知道,java consumer要想调用一个dubbo服务,必须拿到该服务对应的接口jar包,该jar包里面包含了接口定义(consumer端会动态代理生成proxy)以及各种传输实体(比如参数类型、返回值类型等),而如果consumer端使用其他语言,比如c++,那么接口jar包肯定不能直接使用了,此时可以模仿java动态代理的行为,自己写一套java转c++的工具,将jar包转为c++中的传输实体,原理大致如下: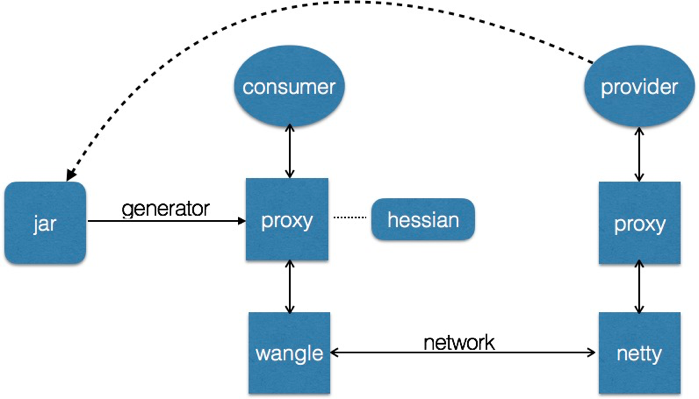
图1 proxy调用模式
此种方式虽然可以实现最终功能,但是它存在以下几个缺陷:
如果接口jar包中包含了Object类型(包括直接定义成Object或者泛型擦除之后为Object),那么生成器无法将其转换为对应的c++类型。
需要为每一种新接入的语言开发相应的生成器,这是一个非常繁重的工作。
上面的这种模式我将其称之为代理模式(proxy),也就是consumer端需要有完整的和provider端对应的类型定义(stub),那么有没有办法可以不需要具体的类型类型信息就可以完成调用呢?这就是下面要引出的泛化方式。
泛化分为两个概念:泛化调用和泛化实现,先看泛化调用。
概念:泛化调用方式主要用于客户端没有API接口及模型类元的情况,参数及返回值中的所有POJO均用Map表示,通常用于框架集成,比如:实现一个通用的服务测试框架。
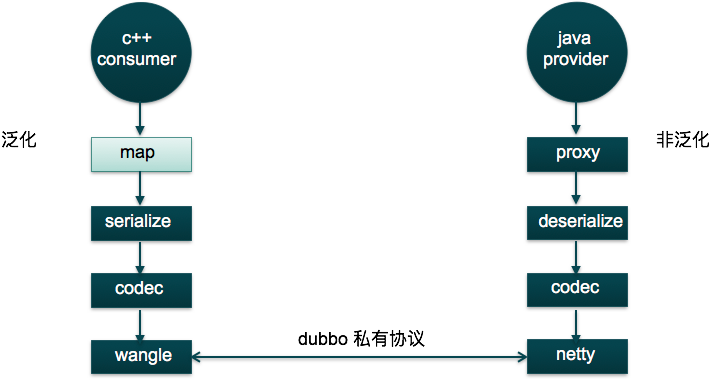
图2 c++泛化调用java
可以看到,采用泛化调用形式之后,consumer端所有的传输实体统一使用map结构表示(一个map和表示一个对象),这具有以下几个优点:
consumer端的序列化和反序列化都是针对map进行,大大的降低了序列化和反序列化的开发难度。
无需单独开发代码生成工具,开发成本低,对原有java框架、业务方都是透明的,没有侵入。
但是此种方式也具有一定的缺点,比如:
需要上层业务自己组装和解析map结构,这对于类型复杂的对象而言比较麻烦。
上层业务需要自己保证参数和返回值的类型检查,因为此时底层的序列化和反序列化是不完全序列化。
上面都是在讲如何使用非java语言的consumer去调用java的provider,那么如何暴露一个非java的provider呢,比如现在要暴露一个兼容dubbo协议的c++ provider(实现java、c++或go来调用c++暴露的服务)。其实方案也可以分为两种,一种是使用proxy模式(proxy模式的缺点上文已经论述了),另一种就是下面要引出的泛化实现。
下面直接看泛化实现的概念。
概念:泛化实现方式主要用于服务器端没有API接口及模型类元的情况,参数及返回值中的所有POJO均用Map表示,通常用于框架集成,比如:实现一个通用的远程服务Mock框架,可通过实现GenericService接口处理所有服务请求。
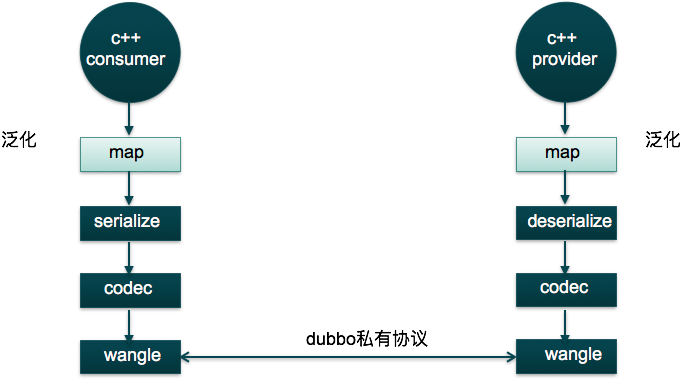
图3 c++泛化调用c++泛化服务
在dubbo中本身也是支持泛化调用和泛化实现,如果想要暴露一个泛化服务,只需要试一下泛化接口即可:
public interface GenericService {
/**
* 泛化调用
*
* @param method 方法名,如:findPerson,如果有重载方法,需带上参数列表,如:findPerson(java.lang.String)
* @param parameterTypes 参数类型
* @param args 参数列表
* @return 返回值
* @throws Throwable 方法抛出的异常
*/
Object $invoke(String method, String[] parameterTypes, Object[] args) throws GenericException;
}同理,比如在c++中要暴露一个泛化服务,也只需要实现一个泛化接口:
class GenericService {
public:
GenericService() = default;
virtual ~GenericService() {};
public:
virtual folly::dynamic $invoke(const std::string &methodName, const folly::dynamic &args) = 0;
};实现一个泛化服务:
class myGenericService : public GenericService {
public:
myGenericService2() {}
~myGenericService2() {}
public:
folly::dynamic $invoke(const std::string &methodName, const folly::dynamic &args) override {
if (methodName == "echoString") {
std::string str = args[0].asString();
/* do something */
return str;
} else if (methodName == "echoPerson") {
folly::dynamic person = args[0];
/* do something */
return person;
}
return args;
}
};四、框架
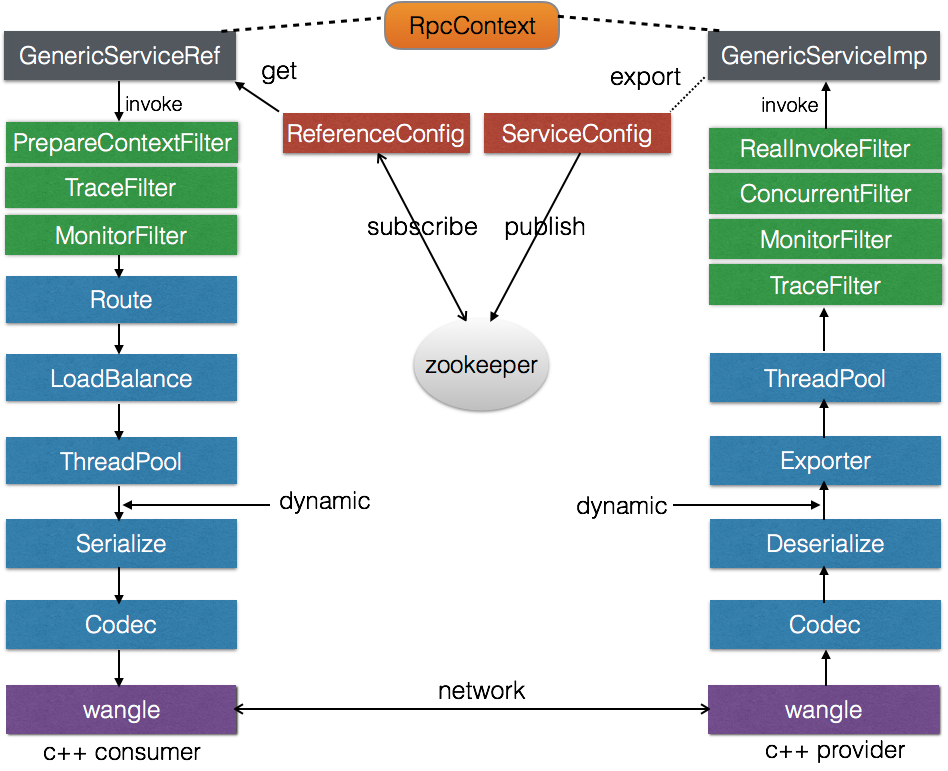
图4 泛化调用和泛化实现架构图
图4虽然是c++ consumer调用c++ provider,但是针对java consumer也是透明支持的,比如可以使用dubbo的泛化调用,此种方式的优点是,不需要c++ provider提供任何接口定义。当然,c++ provider依然可以编写一份单独java接口定义提供给java consumer,这样java consumer就可以用非泛化的方式进行调用了。
实现中,map可以使用folly的dynamic来代替,这样可以极大的提高接口的灵活性。对dynamic感兴趣的可以看我的另一篇文章。

相关文章推荐
- 一个分布式rpc框架的实现方案(二)
- 一种基于 SOA 的应用程序的动态实现框架方案
- dwz框架实现关闭navTab刷新指定navTab的一种方案
- 设计模式是软件的灵魂, 开发语言是多种实现的一种
- 一种常见(粒度,统计值)报表的实现方案
- 一个多语言实现方案(Koala1.0.0.0 ,采用Mustang1.0.0.0)
- 介绍一种免xml配置的持久层实现快速开发的框架
- 一个多语言实现方案(Koala1.0.0.0 ,采用Mustang1.0.0.0)
- 一种蓝牙打印机的实现方案
- Undo/Redo框架的一种实现
- Struts,MVC 的一种开放源码实现用这种servlet和JSP框架管理复杂的大型网站
- 一种密码实验平台的设计方案的关键实现思路
- Struts,MVC 的一种开放源码实现用这种servlet和JSP框架管理复杂的大型网站
- 多语言网站实现方案
- 抛砖引玉-使用Acegi实现多种用户登录的一种方案
- 一种高性能Hierarchical RBAC实现方案
- Struts,MVC 的一种开放源码实现用这种servlet和JSP框架管理复杂的大型网站
- Struts,MVC 的一种开放源码实现用这种servlet和JSP框架管理复杂的大型网站
- uip(一种MVC模式的实现)模式的理解 -微软提供的框架
- 多语言网站实现方案