数据挖掘算法之Apriori和FP-growth
2017-04-25 17:15
302 查看
1、基本概念
支持度(support):数据集中包含该项集的记录所占比例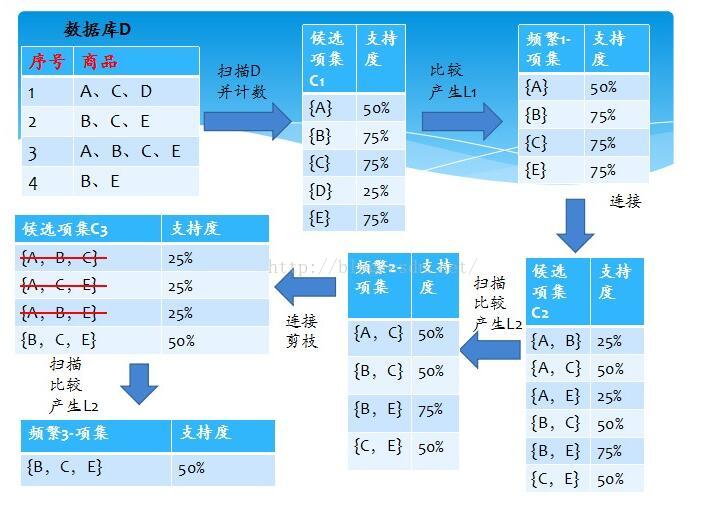
置信度或可信度(confidence):主要是针对莫以具体的关联规则进行定义的,如:{尿布}->{啤酒}的可信度可以被定义为:支持度{尿布、葡萄酒}/支持度{尿布}
2、Apriori算法
主要思路就是找到数据集合中的频繁项集和关联规则(1)发现频繁项集
频繁项集的确定主要是依靠支持度。我们预设一个最小支持度阈值,用以过滤掉不满足条件的项集,将满足最小支持度的项集进行保留;(2)抽取关联规则
关联规则的确定主要是依靠置信度。同样的设置一个最小置信度阈值,用于删除掉不满足条件的项集,保留下来的就是具有一定关联规则的项集。3、FP-growth算法
该算法是在Apriori算法的基础上,只是针对频繁项集发现算法进行了改进,提高了算法处理速度,同时该算法需要对数据集合进行两次扫描。算法思路:
(1)发现频繁项集
a、构建FP树(需要重点理解)b、从FP树中挖掘频繁项集
(2)抽取关联规则
a、从FP树中获得条件模式基(是以所查找元素项为结尾的路径集合)b、利用条件模式基,构建一个条件FP树(需要重点理解)
c、迭代重复步骤a和b,直到树包含一个元素项为止
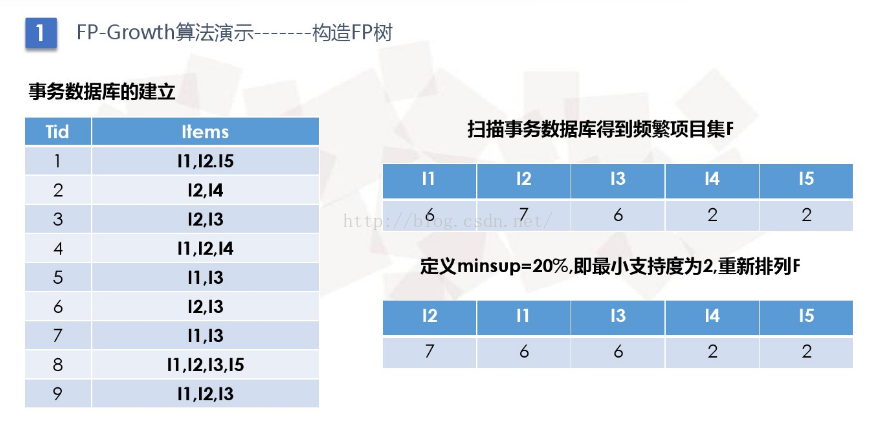
4、算法示例
(1)求出各个项集的支持度
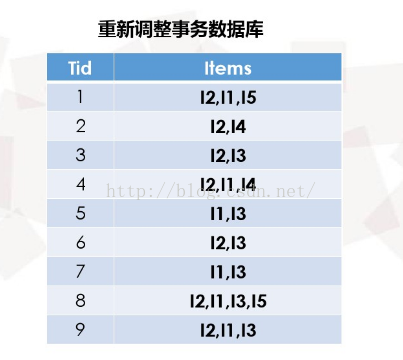
(2)过滤部分项集后的数据集合
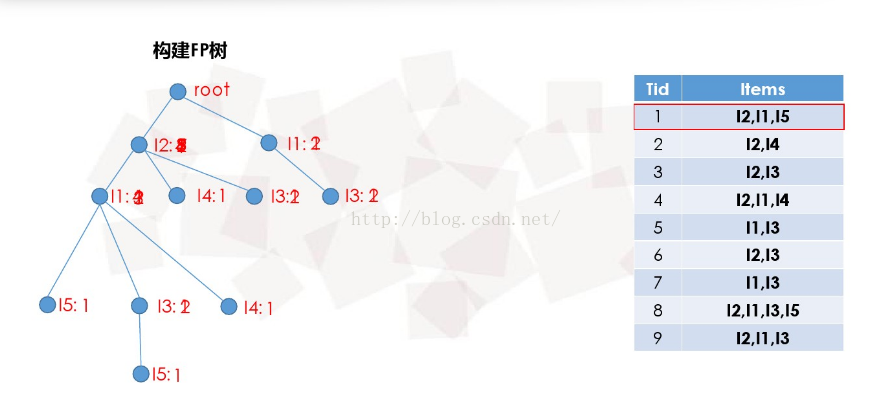
(3)构建FP树
(4)条件模式基和条件FP树
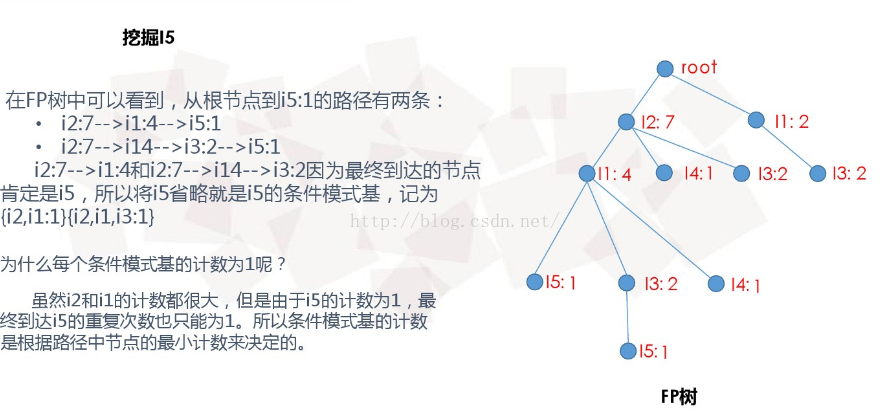

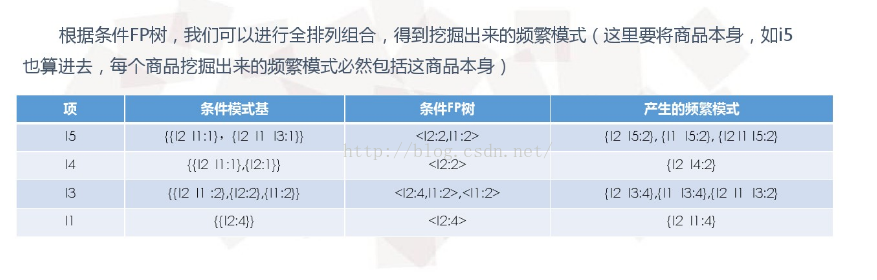
(5)得到相应的频繁模式
5、Apriori算法和FP-growth算法特点比较

6、参考文献
https://wenku.baidu.com/view/c32bbada27d3240c8547ef1b.htmlhttp://blog.csdn.net/lizhengnanhua/article/details/9061755
《机器学习实战》Peter Harrington著 李锐 李鹏 曲亚东 王斌 译
有什么错误之处和改进之处请指点!!!

相关文章推荐
- Spark下的FP-Growth和Apriori(频繁项集挖掘并行化算法)
- 挖掘DBLP作者合作关系,FP-Growth算法实践(2):从DBLP数据集中提取信息,三种源码(dom,sax,string)
- 数据挖掘回顾十二:关联规则挖掘之 FP-Growth 算法
- 数据挖掘-关联分析频繁模式挖掘Apriori、FP-Growth及Eclat算法的JAVA及C++实现
- 数据挖掘-关联分析频繁模式挖掘Apriori、FP-Growth及Eclat算法的JAVA及C++实现
- 挖掘DBLP作者合作关系,FP-Growth算法实践(1):从DBLP数据集中提取目标信息(会议、作者等)
- 数据挖掘-关联分析频繁模式挖掘Apriori、FP-Growth及Eclat算法的JAVA及C++实现
- 数据挖掘之Apriori算法详解和Python实现代码分享
- 数据挖掘之关联规则挖掘之Apriori算法实现
- 数据挖掘方面的一个算法——FP-Tree
- 利用mahout自带的fpgrowth程序以及自己的原始数据挖掘频繁模式
- 数据挖掘算法——Apriori
- FP-Growth算法之频繁项集的挖掘(python)
- 常用数据挖掘算法 - 决策树ID3&关联推荐Apriori &朴素贝叶斯NBC
- 数据挖掘之Apriori算法详解
- 使用 FP-growth 算法高效挖掘海量数据中的频繁项集
- 数据挖掘笔记-关联规则-FPGrowth-简单实现
- 数据挖掘之模式挖掘(频繁模式挖掘与Apriori算法)
- 数据挖掘笔记-关联规则-FPGrowth-MapReduce实现