工程中常用的特征选择方法
2017-04-24 19:27
387 查看
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。
为什么?
(1)降低维度,选择重要的特征,避免维度灾难,降低计算成本
(2)去除不相关的冗余特征(噪声)来降低学习的难度,去除噪声的干扰,留下关键因素,提高预测精度
(3)获得更多有物理意义的,有价值的特征
不同模型有不同的特征适用类型?
(1)lr模型适用于拟合离散特征(见附录)
(2)gbdt模型适用于拟合连续数值特征
(3)一般说来,特征具有较大的方差说明蕴含较多信息,也是比较有价值的特征
通常来说,从两个方面考虑来选择特征:
特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
根据特征选择的形式又可以将特征选择方法分为3种:
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。通过该方法选出来的特征与具体的预测模型没有关系,因此具有更好的泛化能力。
Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。围绕一定的预测模型,预测模型的估计误差一定程度上反映了特征的有用性。
Embedded:集成法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。

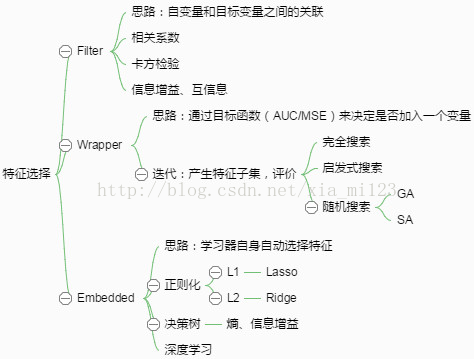
Filter
方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值,选择top N。
互信息法
经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下:
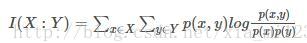
同理,选择互信息排列靠前的特征作为最终的选取特征。
皮尔逊相关系数法(只衡量特征和目标变量之间的线性关系)
卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
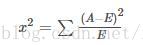
这个统计量的含义简而言之就是自变量对因变量的相关性。选择卡方值排在前面的K个特征作为最终的特征选择。
Wrapper
递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
Embedded
基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。由于L1范数有筛选特征的作用,因此,训练的过程中,如果使用了L1范数作为惩罚项,可以起到特征筛选的效果。
基于树模型的特征选择法
训练能够对特征打分的预选模型:GBDT、RandomForest和Logistic Regression等都能对模型的特征打分,通过打分获得相关性后再训练最终模型。
不管是scikit-learn还是mllib,其中的随机森林和gbdt算法都是基于决策树算法,一般的,都是使用了cart树算法,通过gini指数来计算特征的重要性的。
比如scikit-learn的sklearn.feature_selection.SelectFromModel可以实现根据特征重要性分支进行特征的转换。在spark
2.0之后,mllib的决策树算法都引入了计算特征重要性的方法featureImportances,而随机森林算法(RandomForestRegressionModel和RandomForestClassificationModel类)和gbdt算法(GBTClassificationModel和GBTRegressionModel类)均利用决策树算法中计算特征不纯度和特征重要性的方法来得到所使用模型的特征重要性。
为什么?
(1)降低维度,选择重要的特征,避免维度灾难,降低计算成本
(2)去除不相关的冗余特征(噪声)来降低学习的难度,去除噪声的干扰,留下关键因素,提高预测精度
(3)获得更多有物理意义的,有价值的特征
不同模型有不同的特征适用类型?
(1)lr模型适用于拟合离散特征(见附录)
(2)gbdt模型适用于拟合连续数值特征
(3)一般说来,特征具有较大的方差说明蕴含较多信息,也是比较有价值的特征
通常来说,从两个方面考虑来选择特征:
特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
根据特征选择的形式又可以将特征选择方法分为3种:
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。通过该方法选出来的特征与具体的预测模型没有关系,因此具有更好的泛化能力。
Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。围绕一定的预测模型,预测模型的估计误差一定程度上反映了特征的有用性。
Embedded:集成法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。
Filter
方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值,选择top N。
互信息法
经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下:
同理,选择互信息排列靠前的特征作为最终的选取特征。
皮尔逊相关系数法(只衡量特征和目标变量之间的线性关系)
卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
这个统计量的含义简而言之就是自变量对因变量的相关性。选择卡方值排在前面的K个特征作为最终的特征选择。
Wrapper
递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
Embedded
基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。由于L1范数有筛选特征的作用,因此,训练的过程中,如果使用了L1范数作为惩罚项,可以起到特征筛选的效果。
基于树模型的特征选择法
训练能够对特征打分的预选模型:GBDT、RandomForest和Logistic Regression等都能对模型的特征打分,通过打分获得相关性后再训练最终模型。
不管是scikit-learn还是mllib,其中的随机森林和gbdt算法都是基于决策树算法,一般的,都是使用了cart树算法,通过gini指数来计算特征的重要性的。
比如scikit-learn的sklearn.feature_selection.SelectFromModel可以实现根据特征重要性分支进行特征的转换。在spark
2.0之后,mllib的决策树算法都引入了计算特征重要性的方法featureImportances,而随机森林算法(RandomForestRegressionModel和RandomForestClassificationModel类)和gbdt算法(GBTClassificationModel和GBTRegressionModel类)均利用决策树算法中计算特征不纯度和特征重要性的方法来得到所使用模型的特征重要性。

相关文章推荐
- 干货:结合Scikit-learn介绍几种常用的特征选择方法
- 干货:结合Scikit-learn介绍几种常用的特征选择方法
- 结合Scikit-learn介绍几种常用的特征选择方法
- 干货:结合Scikit-learn介绍几种常用的特征选择方法
- 医学图像常用特征选择方法
- 结合Scikit-learn介绍几种常用的特征选择方法
- 二分类问题特征选择的常用两个方法
- 机器学习之(四)特征工程以及特征选择的工程方法
- 结合Scikit-learn介绍几种常用的特征选择方法
- 干货:结合Scikit-learn介绍几种常用的特征选择方法
- 结合Scikit-learn介绍几种常用的特征选择方法
- 结合Scikit-learn介绍几种常用的特征选择方法
- [转]干货:结合Scikit-learn介绍几种常用的特征选择方法
- Scikit-learn介绍几种常用的特征选择方法
- 文本建模常用的预处理方法——特征选择方法(CHI和IG)
- 机器学习中,有哪些特征选择的工程方法?
- 结合Scikit-learn介绍几种常用的特征选择方法
- 干货:结合Scikit-learn介绍几种常用的特征选择方法
- 医学图像常用特征选择方法
- 机器学习中,有哪些特征选择的工程方法?