Hadoop集群模式下运行Mapreduce任务
2017-04-19 17:18
651 查看
写了一个Hadoop权威指南中MapReduce处理天气数据的Demo

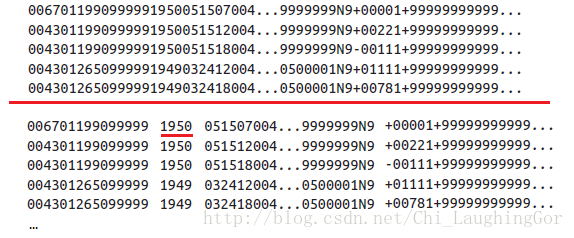
map前

map后
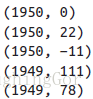
mapreduce流程图

MaxTemperatureReducer
编写App类
创建hdfs目录ncdc_data存放待处理数据
将待处理数据拷贝到ncdc_da目录下ta
查看HDFS目录结构 ,看到数据拷贝成功
最后运行程序(其中out目录用于存放输出结果)
此时再次查看HDFS目录结构,可以看到out目录下的输出文件
查看输出文件 part-r-00000**
一.MapReduce执行过程
map前
map后
mapreduce流程图
二.编写Mapper和Reducer类
MaxTemperatureMapperMaxTemperatureReducer
//mapper
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+')
{ // parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
//Reducer
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text keyin, Iterable<IntWritable> valuein, Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : valuein) {
maxValue = Math.max(maxValue, value.get());
}
context.write(keyin, new IntWritable(maxValue));
}
}编写App类
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MaxTemperature {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.out.println(job.waitForCompletion(true));
}
}三.在HDFS集群上执行程序
将写好的hadoopDemo打成jar包上传到ubuntu主机root@s0:/mnt/hgfs/Host2VMmare# cp hadoopDemo.jar ~/Downloads/
创建hdfs目录ncdc_data存放待处理数据
root@s0:/mnt/hgfs/Host2VMmare# hadoop fs -mkdir -p /user/root/ncdc_data/
将待处理数据拷贝到ncdc_da目录下ta
root@s0:/mnt/hgfs/Host2VMmare# hadoop fs -put 19*.gz /user/root/ncdc_data/
查看HDFS目录结构 ,看到数据拷贝成功
root@s0:/mnt/hgfs/Host2VMmare# hadoop fs -ls -R / drwxr-xr-x - root supergroup 0 2017-04-18 11:56 /d drwxr-xr-x - root supergroup 0 2017-04-19 00:42 /user drwxr-xr-x - root supergroup 0 2017-04-19 00:44 /user/root drwxr-xr-x - root supergroup 0 2017-04-19 00:46 /user/root/ncdc_data -rw-r--r-- 2 root supergroup 73867 2017-04-19 00:46 /user/root/ncdc_data/1901.gz -rw-r--r-- 2 root supergroup 74105 2017-04-19 00:46 /user/root/ncdc_data/1902.gz
最后运行程序(其中out目录用于存放输出结果)
root@s0:~/Downloads# hadoop jar hadoopDemo.jar /user/root/ncdc_data/ /user/root/out 17/04/19 01:00:01 INFO client.RMProxy: Connecting to ResourceManager at s0/192.168.190.131:8032 17/04/19 01:00:03 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 17/04/19 01:00:07 INFO input.FileInputFormat: Total input paths to process : 2 17/04/19 01:00:07 INFO mapreduce.JobSubmitter: number of splits:2 17/04/19 01:00:07 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1492587464114_0001 17/04/19 01:00:09 INFO impl.YarnClientImpl: Submitted application application_1492587464114_0001 17/04/19 01:00:09 INFO mapreduce.Job: The url to track the job: http://s0:8088/proxy/application_1492587464114_0001/ 17/04/19 01:00:09 INFO mapreduce.Job: Running job: job_1492587464114_0001 17/04/19 01:00:28 INFO mapreduce.Job: Job job_1492587464114_0001 running in uber mode : false 17/04/19 01:00:28 INFO mapreduce.Job: map 0% reduce 0% 17/04/19 01:00:53 INFO mapreduce.Job: map 100% reduce 0% 17/04/19 01:01:11 INFO mapreduce.Job: map 100% reduce 100% 17/04/19 01:01:13 INFO mapreduce.Job: Job job_1492587464114_0001 completed successfully 17/04/19 01:01:13 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=144425 FILE: Number of bytes written=643530 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=148176 HDFS: Number of bytes written=18 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=45494 Total time spent by all reduces in occupied slots (ms)=13941 Total time spent by all map tasks (ms)=45494 Total time spent by all reduce tasks (ms)=13941 Total vcore-milliseconds taken by all map tasks=45494 Total vcore-milliseconds taken by all reduce tasks=13941 Total megabyte-milliseconds taken by all map tasks=46585856 Total megabyte-milliseconds taken by all reduce tasks=14275584 Map-Reduce Framework Map input records=13130 Map output records=13129 Map output bytes=118161 Map output materialized bytes=144431 Input split bytes=204 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=144431 Reduce input records=13129 Reduce output records=2 Spilled Records=26258 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=969 CPU time spent (ms)=4670 Physical memory (bytes) snapshot=292323328 Virtual memory (bytes) snapshot=5676564480 Total committed heap usage (bytes)=259633152 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=147972 File Output Format Counters Bytes Written=18 true
此时再次查看HDFS目录结构,可以看到out目录下的输出文件
root@s0:~/Downloads# hadoop fs -ls -R / drwxr-xr-x - root supergroup 0 2017-04-18 11:56 /d drwx------ - root supergroup 0 2017 ecdb -04-19 01:00 /tmp drwx------ - root supergroup 0 2017-04-19 01:00 /tmp/hadoop-yarn drwx------ - root supergroup 0 2017-04-19 01:00 /tmp/hadoop-yarn/staging drwxr-xr-x - root supergroup 0 2017-04-19 01:00 /tmp/hadoop-yarn/staging/history drwxrwxrwt - root supergroup 0 2017-04-19 01:00 /tmp/hadoop-yarn/staging/history/done_intermediate drwxrwx--- - root supergroup 0 2017-04-19 01:01 /tmp/hadoop-yarn/staging/history/done_intermediate/root -rwxrwx--- 2 root supergroup 39928 2017-04-19 01:01 /tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1492587464114_0001-1492588808404-root-Max+temperature-1492588870701-2-1-SUCCEEDED-default-1492588827238.jhist -rwxrwx--- 2 root supergroup 354 2017-04-19 01:01 /tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1492587464114_0001.summary -rwxrwx--- 2 root supergroup 116606 2017-04-19 01:01 /tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1492587464114_0001_conf.xml drwx------ - root supergroup 0 2017-04-19 01:00 /tmp/hadoop-yarn/staging/root drwx------ - root supergroup 0 2017-04-19 01:01 /tmp/hadoop-yarn/staging/root/.staging drwxr-xr-x - root supergroup 0 2017-04-19 00:42 /user drwxr-xr-x - root supergroup 0 2017-04-19 01:00 /user/root drwxr-xr-x - root supergroup 0 2017-04-19 00:46 /user/root/ncdc_data -rw-r--r-- 2 root supergroup 73867 2017-04-19 00:46 /user/root/ncdc_data/1901.gz -rw-r--r-- 2 root supergroup 74105 2017-04-19 00:46 /user/root/ncdc_data/1902.gz drwxr-xr-x - root supergroup 0 2017-04-19 01:01 /user/root/out **-rw-r--r-- 2 root supergroup 0 2017-04-19 01:01 /user/root/out/_SUCCESS -rw-r--r-- 2 root supergroup 18 2017-04-19 01:01 /user/root/out/part-r-00000**
查看输出文件 part-r-00000**
root@s0:~/Downloads# hadoop fs -cat /user/root/out/part-r* 1901 317 1902 244

相关文章推荐
- Hadoop 伪分布式模式 MapReduce 任务不能继续运行 解决方案
- 在hadoop集群上运行mapreduce程序时报错“org.apache.hadoop.util.Shell$ExitCodeException:***not found”
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop单机模式并运行Wordcount(2)
- Hadoop之MapReduce的两种任务模式
- 攻城狮在路上(陆)-- 提交运行MapReduce程序到hadoop集群运行
- 解决Hadoop运行jar包时MapReduce任务启动前OutOfMemoryError:Java heap space问题
- Hadoop集群_WordCount运行详解--MapReduce编程模型
- 创建MapReduce程序,并在hadoop集群中运行
- win7使用eclipse连接hadoop集群,运行mapreduce报错之Failed to set permissions of path
- hadoop mapreduce的job的几种运行模式
- Hadoop集群链接_Eclipse开发环境:成功运行mapreduce所遇问题
- Spark教程-构建Spark集群-配置Hadoop单机模式并运行Wordcount(1)
- 【Hadoop】MapReduce笔记(一):MapReduce作业运行过程、任务执行
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop伪分布模式并运行Wordcount示例(1)
- win7使用eclipse连接hadoop集群,运行mapreduce报错之:org.apache.hadoop.security.AccessControlException
- Hadoop web项目使用Ajax监控MapReduce任务运行情况
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop单机模式并运行Wordcount(1)
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop伪分布模式并运行Wordcount(2)
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop-伪分布模式并运行Wordcount(2)
- Hadoop运行mapreduce任务过程中报错:Error: Java heap space问题解决