Wav文件格式简要分析
2017-04-14 17:43
218 查看
WAVE文件格式是Microsoft的RIFF规范的一个子集,用于存储数字音频,整个文件就是一个RIFF大块,它的基本形式包括两种块:fmt块,用于描述压缩格式、采样率等基本信息;data块。包含实际样本数据。

RIFF标头结构定义
FMT块结构定义
先定义一个关于波形文件信息的结构体,再把这个结构体作为FMT块结构体的一个成员。
FMT块结构体
可选部分fact chunk
当wav文件由某些软件转成,会含有该chunk,结构定义如下:
Data chunk头结构定义
数据块的具体组织格式,在下面,8bit和16bit的区别中介绍。
QUESTION1: 8bit和16bit样值的二进制编码方式表示一样吗?
对于wFormatTag为WAVE_FORMAT_PCM格式时的非压缩数据,data chunk中紧跟着DataChunkSize后的PCM数据组成如下:
8bit(无符号0~255)
单声道

双声道

16bit:有符号 -32768~32767
单声道

双声道
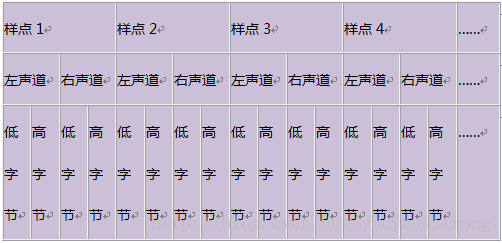
对于其他压缩形式,储存格式就更为复杂。比如wFormatTag为IMA-ADPCM时,数据从PCM16位采样压缩成4位,单声道是按采样次序写入,每字节2两个样点,低4位是第一个样点,高4位是第二个样点,双声道是先写左声道前8个样点,也就是4字节,作为一个DWORD,再写右声道8个样点,作为一个DWORD,写到最后如果不够8个样点就补0到8个样点。
QUESTION2: 上面提到了ADPCM的压缩格式,那么现有的WAV支持哪几种音频压缩方法?
wFormatTag有10个值对应10种编码算法:
QUESTION3: 广泛采用的WAV文件为16bit、 44.1kHz,那么采样率48khz的wav文件如何转换成44.1khz?
由于44.1khz与48khz不是整数倍的关系,所以要先插值再重新取样,48k和44.1k的公倍数为7056k,所以先插值为7056k(=48 k *147=44.1k*160),比如说有一秒钟的数据量,可以在每个样值后面复制146个该样值达到插值的目的,然后从第一个样值开始取,每隔159个样值取一个新样值,最后就取出了44.1k个样值,就完成了采样率的转换。
RIFF标头结构定义
struct RIFF_HEADER
{
char szRiffID[4]; // 四个字符'R','I','F','F',像这样的字符是低字节存高位,即地址从低到高依次读出'R','I','F','F'
DWORD dwRiffSize;//文件总数据量-8字节(即除去开头8字节),像这样的数字是低字节存低位,读数时应从高字节向低字节读,才能正确读出
char szRiffFormat[4]; //四个字符 'W','A','V','E'
};| 地址 | 字节数 | 数据类型 | 变量名 | 内容 |
|---|---|---|---|---|
| 00H~03H | 4 | char | szRiffID[4] | ‘R”I”F”F’标志 |
| 04H~07H | 4 | DWORD | dwRiffSize | 文件大小,不包括前8字节 |
| 08H~0BH | 4 | char | szRiffFormat[4] | ‘W”A”V”E’标志 |
先定义一个关于波形文件信息的结构体,再把这个结构体作为FMT块结构体的一个成员。
struct WAVE_FORMAT
{
WORD wFormatTag;// 编码方法,PCM编码时为1,其他压缩方法时参见下文中“wav格式支持的压缩方法”
WORD wChannels;//通道数,1为单声道,2为双声道
DWORD dwSamplesPerSec;//采样率,即每秒的样本数
DWORD dwAvgBytesPerSec; //传输速率,每秒字节数=采样率*每个样点字节数(即下面的wBlockAlign)
WORD wBlockAlign; //每个样点字节数=样本宽度*通道数/8
WORD wBitsPerSample; //样本宽度,即一个样值用多少位表示,通常为8或16
};FMT块结构体
struct FMT_BLOCK
{
char szFmtID[4]; // 'f','m','t',三个字符,最后一个字节为空格
DWORD dwFmtSize;//fmt块的字节数(编码方式为pcm时为16,即下面结构体成员的字节数,不为pcm时,为),不包括前8个字节
WAVE_FORMAT wavFormat;// 上面那个结构体
};| 地址 | 字节数 | 数据类型 | 变量名 | 内容 |
|---|---|---|---|---|
| 0CH~0FH | 4 | char | szFmtID[4] | ‘f”m”t’标志 |
| 10H~13H | 4 | DWORD | dwFmtSize | fmt块大小,不包括前8字节(一般为16) |
| 14H~15H | 2 | WORD | wFormatTag | 标识文件采用的编码方法 |
| 16H~17H | 2 | WORD | wChannels | 标识单/双(1/2)声道 |
| 18H~1BH | 4 | DWORD | dwSamplesPerSec | 采样率 |
| 1CH~1FH | 4 | DWORD | dwAvgBytesPerSec | 传输速率 |
| 20H~21H | 2 | WORD | wBlockAlign | 每个样点字节数 |
| 22H~23H | 2 | WORD | wBitsPerSample | 样本宽度 |
| 附加信息(24H~25H) | 2 | WORD | 额外的字节数,即下面2字节的WORD ,当wFormatTag不是pcm时会有这最后两项 | |
| 附加信息(26H~27H) | 2 | WORD | 每一个data block的采样点数,因为在采用IMA-ADPCM压缩算法data chuck中的数据是以block形式来组织的 |
当wav文件由某些软件转成,会含有该chunk,结构定义如下:
struct FACT_BLOCK
{
char szFactID[4]; //四个字符 'f','a','c','t'
DWORD dwFactSize;
};Data chunk头结构定义
struct DATA_BLOCK
{
char szDataID[4]; // 四个字符'd','a','t','a'
DWORD dwDataSize;//数据块字节数,不含前8个字节
};数据块的具体组织格式,在下面,8bit和16bit的区别中介绍。
QUESTION1: 8bit和16bit样值的二进制编码方式表示一样吗?
对于wFormatTag为WAVE_FORMAT_PCM格式时的非压缩数据,data chunk中紧跟着DataChunkSize后的PCM数据组成如下:
8bit(无符号0~255)
单声道
双声道
16bit:有符号 -32768~32767
单声道
双声道
对于其他压缩形式,储存格式就更为复杂。比如wFormatTag为IMA-ADPCM时,数据从PCM16位采样压缩成4位,单声道是按采样次序写入,每字节2两个样点,低4位是第一个样点,高4位是第二个样点,双声道是先写左声道前8个样点,也就是4字节,作为一个DWORD,再写右声道8个样点,作为一个DWORD,写到最后如果不够8个样点就补0到8个样点。
QUESTION2: 上面提到了ADPCM的压缩格式,那么现有的WAV支持哪几种音频压缩方法?
wFormatTag有10个值对应10种编码算法:
| wFormatTag值 | 编码算法 |
|---|---|
| 0001H | PCM/uncompressed |
| 0002H | Microsoft ADPCM |
| 0006H | ITU G.711 a-law |
| 0007H | ITU G.711 µ-law |
| 0011H | IMA ADPCM |
| 0016H | ITU G.723 ADPCM (Yamaha) |
| 0031H | GSM 6.10 |
| 0040H | ITU G.721 ADPCM |
| 0050H | MPEG |
| FFFFH | Experimental |
由于44.1khz与48khz不是整数倍的关系,所以要先插值再重新取样,48k和44.1k的公倍数为7056k,所以先插值为7056k(=48 k *147=44.1k*160),比如说有一秒钟的数据量,可以在每个样值后面复制146个该样值达到插值的目的,然后从第一个样值开始取,每隔159个样值取一个新样值,最后就取出了44.1k个样值,就完成了采样率的转换。
