CAFFE源码学习笔记之batch_norm_layer
2017-04-13 16:35
323 查看
一、前言
网络训练的过程中参数不断的变化导致后续的每一层输入的分布也发生变化,而学习的过程使得每一层都需要适应输入的分布。所以就需要谨慎的选择初始化,使用小的学习率,这极大的降低了网络收敛的速度。
为了使每层的输入分布大致都在0均值和单位方差,需要对每层的输入进行归一化。
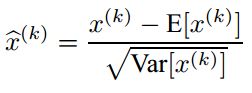
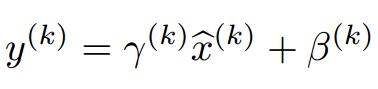
为了使
二、源码分析
1、layersetup函数
batch_norm参数:
卷积层这样具有权值共享的层,Wx+b的均值和方差是对整张map求得的,在batch_size * channel * height * width这么大的一层中,对总共batch_size*height*width个像素点统计得到一个均值和一个标准差,共得到channel组参数。
2、reshape
3、前向计算
训练的过程并不是一次前向计算就结束,而是从总样本中抽取mini-batch个样本,进行多次前向计算,这样的话需要考虑每次计算得到的mean和variance,caffe这里的算法并不是简简单单的将每次计算的mean和variance累加,而是把前一次计算的mean和variance的影响减小(乘以一个小于1的变量),再加上本次计算的结果。
所以,均值和方差采用的是滑动平均的更新方式
前一批次的均值:St−1
当前批次的均值:Yt
St=(1−β)Yt+β⋅St−1
设滑动系数 moving_average_fraction 为 λ
对于滑动系数有:snew=λsold+1
对于均值有:μnew=λμold+μ
对于方差有:σnew=λσold+mσif(m>1),m=(m−1)/m
通过源码可以看出,CAFFE没有加最后的两个参数。
4、反向计算
由于没有γ,β两个参数,所以反向计算就是算输入的梯度。
∂L∂var=∑m0∂L∂yi∂yi∂var=∑m0∂L∂yi(xi−mean)(−12)(var+eps)−32
∂L∂mean=∑m0∂L∂yi∂yi∂mean=∑m0∂L∂yi−1var+eps√
∂L∂xi=∂L∂yi1var+eps√+∂L∂var∂var∂xi+∂L∂mean∂mean∂xi=∂L∂yi1var+eps√+∂L∂var2m(xi−mean)+∂L∂mean1m=1var+eps√(∂L∂yi−1m∑m0∂L∂yi−(1m∑m0∂L∂yiyi)yi)=1var+eps√(∂L∂yi−1m(∂L∂yi)−1m(∂L∂yi.yi).yi)
实现就是按照公式进行计算而已
网络训练的过程中参数不断的变化导致后续的每一层输入的分布也发生变化,而学习的过程使得每一层都需要适应输入的分布。所以就需要谨慎的选择初始化,使用小的学习率,这极大的降低了网络收敛的速度。
为了使每层的输入分布大致都在0均值和单位方差,需要对每层的输入进行归一化。
为了使
二、源码分析
1、layersetup函数
batch_norm参数:
message BatchNormParameter {
// 当为真,使用保存的均值和方差,否则使用滑动平均计算新的方差和均值
optional bool use_global_stats = 1;
//滑动平均的系数
optional float moving_average_fraction = 2 [default = .999];
// 平滑,防止除以0
optional float eps = 3 [default = 1e-5];
}卷积层这样具有权值共享的层,Wx+b的均值和方差是对整张map求得的,在batch_size * channel * height * width这么大的一层中,对总共batch_size*height*width个像素点统计得到一个均值和一个标准差,共得到channel组参数。
template <typename Dtype>
void BatchNormLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
BatchNormParameter param = this->layer_param_.batch_norm_param();//batch_norm参数
moving_average_fraction_ = param.moving_average_fraction();
use_global_stats_ = this->phase_ == TEST;//训练时均值和方差是基于每个batch进行计算的,而测试的时候均值和方差是对整个数据集而言的。
if (param.has_use_global_stats())
use_global_stats_ = param.use_global_stats();
if (bottom[0]->num_axes() == 1)//一维的时候,通道数为1
channels_ = 1;
else
channels_ = bottom[0]->shape(1);//否则等于输入的通道数
eps_ = param.eps();//滑动平均系数
if (this->blobs_.size() > 0) {//存储学习参数
LOG(INFO) << "Skipping parameter initialization";
} else {
this->blobs_.resize(3);//存储学习参数
vector<int> sz;
sz.push_back(channels_);
this->blobs_[0].reset(new Blob<Dtype>(sz));//均值滑动和,元素个数为channels_的数组
this->blobs_[1].reset(new Blob<Dtype>(sz));//方差滑动和,元素个数为channels_的数组
sz[0] = 1;
this->blobs_[2].reset(new Blob<Dtype>(sz));//滑动系数和,元素个数为1的数组
for (int i = 0; i < 3; ++i) {
caffe_set(this->blobs_[i]->count(), Dtype(0),
this->blobs_[i]->mutable_cpu_data());//初始化学习参数,初始化为0.
}
}
// Mask statistics from optimization by setting local learning rates
// for mean, variance, and the bias correction to zero.
for (int i = 0; i < this->blobs_.size(); ++i) {
if (this->layer_param_.param_size() == i) {
ParamSpec* fixed_param_spec = this->layer_param_.add_param();
fixed_param_spec->set_lr_mult(0.f);
} else {
CHECK_EQ(this->layer_param_.param(i).lr_mult(), 0.f)
<< "Cannot configure batch normalization statistics as layer "
<< "parameters.";
}
}
}2、reshape
template <typename Dtype>
void BatchNormLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
if (bottom[0]->num_axes() >= 1)//输入维度大于1,检查channels
CHECK_EQ(bottom[0]->shape(1), channels_);
top[0]->ReshapeLike(*bottom[0]);//复制输入的形状给输出
vector<int> sz;
sz.push_back(channels_);
mean_.Reshape(sz);
variance_.Reshape(sz);//shape[0] = channels_
temp_.ReshapeLike(*bottom[0]);//n*c*h*w
x_norm_.ReshapeLike(*bottom[0]);//x的归一化缓存
sz[0] = bottom[0]->shape(0);//sz = {batch_size}
batch_sum_multiplier_.Reshape(sz);//shape[0] = batch_size,元素个数为n的数组,在计算mean_时,将所要图像的相应的通道值相加。
int spatial_dim = bottom[0]->count()/(channels_*bottom[0]->shape(0));//h*w
if (spatial_sum_multiplier_.num_axes() == 0 ||
spatial_sum_multiplier_.shape(0) != spatial_dim) {
sz[0] = spatial_dim;//sz[0] =h*w
spatial_sum_multiplier_.Reshape(sz);//{h*w}
Dtype* multiplier_data = spatial_sum_multiplier_.mutable_cpu_data();//在计算mean_时通过乘的方式将一副图像的值相加,结果是一个数值
caffe_set(spatial_sum_multiplier_.count(), Dtype(1), multiplier_data);
}
int numbychans = channels_*bottom[0]->shape(0);//channels_*batch_size
if (num_by_chans_.num_axes() == 0 ||
num_by_chans_.shape(0) != numbychans) {
sz[0] = numbychans;
num_by_chans_.Reshape(sz);//元素个数为c*n
caffe_set(batch_sum_multiplier_.count(), Dtype(1),
batch_sum_multiplier_.mutable_cpu_data());
}
}3、前向计算
训练的过程并不是一次前向计算就结束,而是从总样本中抽取mini-batch个样本,进行多次前向计算,这样的话需要考虑每次计算得到的mean和variance,caffe这里的算法并不是简简单单的将每次计算的mean和variance累加,而是把前一次计算的mean和variance的影响减小(乘以一个小于1的变量),再加上本次计算的结果。
所以,均值和方差采用的是滑动平均的更新方式
前一批次的均值:St−1
当前批次的均值:Yt
St=(1−β)Yt+β⋅St−1
设滑动系数 moving_average_fraction 为 λ
对于滑动系数有:snew=λsold+1
this->blobs_[2]->mutable_cpu_data()[0] *= moving_average_fraction_; this->blobs_[2]->mutable_cpu_data()[0] += 1;
对于均值有:μnew=λμold+μ
caffe_cpu_axpby(mean_.count(), Dtype(1), mean_.cpu_data(), moving_average_fraction_, this->blobs_[0]->mutable_cpu_data());
对于方差有:σnew=λσold+mσif(m>1),m=(m−1)/m
caffe_cpu_axpby(variance_.count(), bias_correction_factor, variance_.cpu_data(), moving_average_fraction_, this->blobs_[1]->mutable_cpu_data());
通过源码可以看出,CAFFE没有加最后的两个参数。
template <typename Dtype>
void BatchNormLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();//输入数据
Dtype* top_data = top[0]->mutable_cpu_data();//输出数据
int num = bottom[0]->shape(0);//n
int spatial_dim = bottom[0]->count()/(bottom[0]->shape(0)*channels_);//spatial_dim = h*w
if (bottom[0] != top[0]) {
caffe_copy(bottom[0]->count(), bottom_data, top_data);//将输入数据复制到输出上
}
if (use_global_stats_) {
// 直接用保存的方差和均值、滑动平均系数
const Dtype scale_factor = this->blobs_[2]->cpu_data()[0] == 0 ?
0 : 1 / this->blobs_[2]->cpu_data()[0];
caffe_cpu_scale(variance_.count(), scale_factor,
this->blobs_[0]->cpu_data(), mean_.mutable_cpu_data());
caffe_cpu_scale(variance_.count(), scale_factor,
this->blobs_[1]->cpu_data(), variance_.mutable_cpu_data());
} else {
// compute mean
//bottom_data是(n*c)*(h*w)的矩阵,spatial_sun_multiplier_是元素个数为1*1*h*w的向量,那么num_by_chans_就是n*c*1*1的向量。
//num_by_chans_=(1/N*H*W)*bottom_data*spatial_sum_multiplier_.cpu_data()
caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim,
1. / (num * spatial_dim), bottom_data,
spatial_sum_multiplier_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
//num_by_chans_转换为n行c列的矩阵,batch_sum_multiplier_是元素个数为n*1*1*1的向量,
//mean_其元素个数为c。
//mean_=num_by_chans_*batch_sum_multiplier_
//计算得到对应channels的平均值,这也解释了为什么之前要除以1./(num*spatial_dim)
//而不是仅除以1./spatial_dim,这样减少了计算量
caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1.,
num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0.,
mean_.mutable_cpu_data());// mean_=bottom_data*(1/N*H*W),按通道计算其均值
}
// 减去均值x-u
//top_data = top_data-num_by_chans_*spatial_sum_multiplier_
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1,
batch_sum_multiplier_.cpu_data(), mean_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num,
spatial_dim, 1, -1, num_by_chans_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 1., top_data);
if (!use_global_stats_) {
// 计算方差:var(X) = E((X-EX)^2)
caffe_powx(top[0]->count(), top_data, Dtype(2),
temp_.mutable_cpu_data()); // (X-EX)^2
caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim,
1. / (num * spatial_dim), temp_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1.,
num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0.,
variance_.mutable_cpu_data()); // E((X_EX)^2)
// 计算滑动平均,blob_[0] = mean_ + moving_average_fraction_* blob_[0];
this->blobs_[2]->mutable_cpu_data()[0] *= moving_average_fraction_;
this->blobs_[2]->mutable_cpu_data()[0] += 1;
caffe_cpu_axpby(mean_.count(), Dtype(1), mean_.cpu_data(), moving_average_fraction_, this->blobs_[0]->mutable_cpu_data());
int m = bottom[0]->count()/channels_;//n*h*w
Dtype bias_correction_factor = m > 1 ? Dtype(m)/(m-1) : 1;//算整个数据集的方差
//blob_[1] = bias_correction_factor * variance_ + moving_average_fraction_ * blob_[1]
caffe_cpu_axpby(variance_.count(), bias_correction_factor,
variance_.cpu_data(), moving_average_fraction_,
this->blobs_[1]->mutable_cpu_data());
}
// 将方差的每个值平滑一下
caffe_add_scalar(variance_.count(), eps_, variance_.mutable_cpu_data());
//开平方
caffe_powx(variance_.count(), variance_.cpu_data(), Dtype(0.5),
variance_.mutable_cpu_data());
// 将channels_个值的方差variance_矩阵扩展到num_*channels_*height*width
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1,
batch_sum_multiplier_.cpu_data(), variance_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num,
spatial_dim, 1, 1., num_by_chans_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 0., temp_.mutable_cpu_data());
caffe_div(temp_.count(), top_data, temp_.cpu_data(), top_data);
// TODO(cdoersch): The caching is only needed because later in-place layers
// might clobber the data. Can we skip this if they won't?
caffe_copy(x_norm_.count(), top_data,
x_norm_.mutable_cpu_data());
}
4、反向计算
由于没有γ,β两个参数,所以反向计算就是算输入的梯度。
∂L∂var=∑m0∂L∂yi∂yi∂var=∑m0∂L∂yi(xi−mean)(−12)(var+eps)−32
∂L∂mean=∑m0∂L∂yi∂yi∂mean=∑m0∂L∂yi−1var+eps√
∂L∂xi=∂L∂yi1var+eps√+∂L∂var∂var∂xi+∂L∂mean∂mean∂xi=∂L∂yi1var+eps√+∂L∂var2m(xi−mean)+∂L∂mean1m=1var+eps√(∂L∂yi−1m∑m0∂L∂yi−(1m∑m0∂L∂yiyi)yi)=1var+eps√(∂L∂yi−1m(∂L∂yi)−1m(∂L∂yi.yi).yi)
实现就是按照公式进行计算而已
template <typename Dtype>
void BatchNormLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
const Dtype* top_diff;//梯度
if (bottom[0] != top[0]) {
top_diff = top[0]->cpu_diff();//将输出的值赋给top_diff
} else {
caffe_copy(x_norm_.count(), top[0]->cpu_diff(), x_norm_.mutable_cpu_diff());
top_diff = x_norm_.cpu_diff();
}
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
if (use_global_stats_) {
caffe_div(temp_.count(), top_diff, temp_.cpu_data(), bottom_diff);
return;
}
const Dtype* top_data = x_norm_.cpu_data();
int num = bottom[0]->shape()[0];
int spatial_dim = bottom[0]->count()/(bottom[0]->shape(0)*channels_);
// if Y = (X-mean(X))/(sqrt(var(X)+eps)), then
//
// dE(Y)/dX =
// (dE/dY - mean(dE/dY) - mean(dE/dY \cdot Y) \cdot Y)
// ./ sqrt(var(X) + eps)
//
// where \cdot and ./ are hadamard product and elementwise division,
// respectively, dE/dY is the top diff, and mean/var/sum are all computed
// along all dimensions except the channels dimension. In the above
// equation, the operations allow for expansion (i.e. broadcast) along all
// dimensions except the channels dimension where required.
// sum(dE/dY \cdot Y)
caffe_mul(temp_.count(), top_data, top_diff, bottom_diff);
caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim, 1.,
bottom_diff, spatial_sum_multiplier_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1.,
num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0.,
mean_.mutable_cpu_data());
// reshape (broadcast) the above
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1,
batch_sum_multiplier_.cpu_data(), mean_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels_ * num,
spatial_dim, 1, 1., num_by_chans_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 0., bottom_diff);
// sum(dE/dY \cdot Y) \cdot Y
caffe_mul(temp_.count(), top_data, bottom_diff, bottom_diff);
// sum(dE/dY)-sum(dE/dY \cdot Y) \cdot Y
caffe_cpu_gemv<Dtype>(CblasNoTrans, channels_ * num, spatial_dim, 1.,
top_diff, spatial_sum_multiplier_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemv<Dtype>(CblasTrans, num, channels_, 1.,
num_by_chans_.cpu_data(), batch_sum_multiplier_.cpu_data(), 0.,
mean_.mutable_cpu_data());
// reshape (broadcast) the above to make
// sum(dE/dY)-sum(dE/dY \cdot Y) \cdot Y
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, channels_, 1, 1,
batch_sum_multiplier_.cpu_data(), mean_.cpu_data(), 0.,
num_by_chans_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num * channels_,
spatial_dim, 1, 1., num_by_chans_.cpu_data(),
spatial_sum_multiplier_.cpu_data(), 1., bottom_diff);
// dE/dY - mean(dE/dY)-mean(dE/dY \cdot Y) \cdot Y
caffe_cpu_axpby(temp_.count(), Dtype(1), top_diff,
Dtype(-1. / (num * spatial_dim)), bottom_diff);
// note: temp_ still contains sqrt(var(X)+eps), computed during the forward
// pass.
caffe_div(temp_.count(), bottom_diff, temp_.cpu_data(), bottom_diff);
}

相关文章推荐
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之batch_norm_layer
- CAFFE源码学习笔记之七-layer_factory以及layer基类
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之七-layer_factory以及layer基类
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之内积层-inner_product_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer
- CAFFE源码学习笔记之十一-卷积层conv_layer