视觉学习中对象检测到的概率(1)(Probabilistic Visual Learning for Object Representation)
2017-04-04 06:06
706 查看
最近遇到的项目作业是人脸识别,从IEEE上找到了Baback Moghaddam大牛97年发表的经典论文———Probabilistic Visual Learning for
Object Representation。读完收货很多,故而写下这篇博客。一是为了与大家分享,二来也是为了留下点东西,日后可以翻阅。本文将翻译一部分论文内容,并会加上自己的见解。
1.介绍
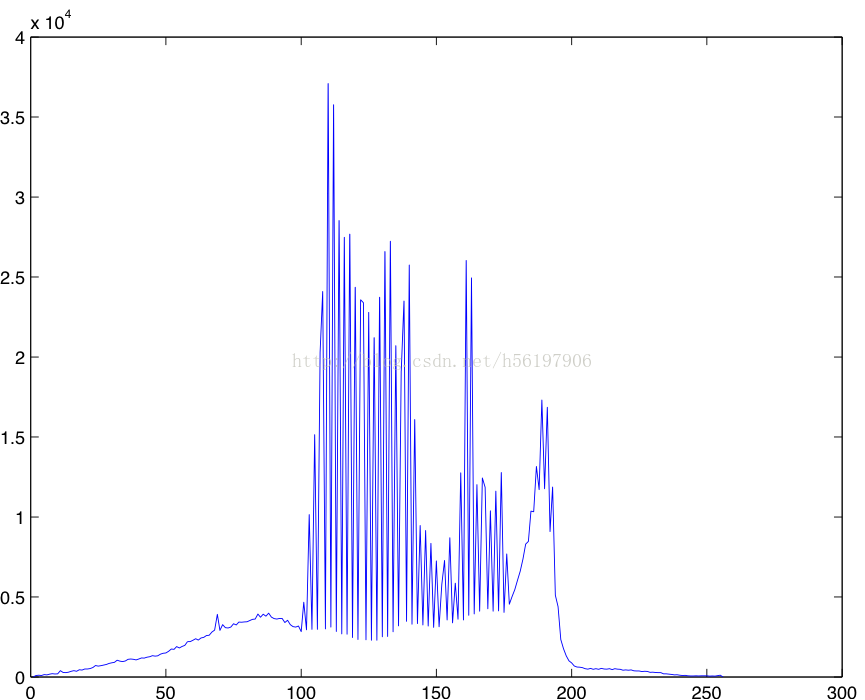
本文提供了一种方法,用于在一副图像中寻找某一个物体,并定位该物体在图像中的位置。例如,在一幅图像中寻找指定的建筑物,或者在一幅合照中找到某一个人,并定位该人脸的位置。本文还是基于PCA的,即将高阶的图像在特征空间上解耦,将其转化到低阶的空间中,便于计算。文中有两种图像值分布的假设:(1)单一的高斯分布(单一的高斯分布)(2)混合的高斯分布(多模型的分布)[这里解释下图像值分布,就是将一副完整的图像上每一点的像素值映射到0到255,观察是否符合高斯,我下面的例子就是一个混合的高斯分布,因为有多个波峰,所以可以想象成是多个高斯分布的叠加]。
因此,识别和定位问题就变成了我们找到这样的(i , j)使得以i,j为中心的子图像和需要寻找的物品匹配。
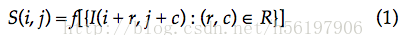
[S(i,j) 就是图像I中左上角坐标为(i , j),r*c大小的一个子图像]
作者计算了每个候选点的匹配的概率P(x | Ω)[x 是每一个子图像,Ω是目标物体class中的实例],并找出最大的概率(maximum likelihood),则该位置就是匹配的位置。
2.关于PCA
关于PCA的描述,网上的文章很多,在这里不再多说很多细节,需要主要的是,PCA 将高阶的矩阵解耦到低阶的矩阵是通过:
(1)将原矩阵映射到对应的特征空间[Φ,N*N]中[这时候是不发生降阶,即每个值都是one to one maping的,特征空间由每个与特征值相对应的特征向量组成,每个特征向量都正交,可以把每个特征向量想象成空间中的一根坐标轴,而特征值就是在这根坐标轴上的值,也就是说原矩阵被映射到了一个新的坐标空间中,而特征值就是每根坐标轴上的点]。
(2)这一步中,我们将特征向量按照特征值的大小进行排列,然后我们选取前top M个特征值对应的特征向量,降阶是发生在这一步中的,因为我们选了前top M个,也就选择在对应特征向量分量最大的前M个,而剩下的 因为在该特征向量上的分量比较小,所以可以被忽略,但是这部分产生的误差是不可避免的,在下文的方法中,这部分的误差有所体现。我们用F
= {Φi, i from 1 to M} 来表示被选择的特征空间,F~ = {Φi, i from M+1 to N} 来表示被忽略的特征空间。
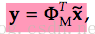
x~ = x - x_,
x_ 是所有的实例的平均,而 x~是所有object-class中的实例的减去平均之后剩余的部分[如果是人脸检测的话,那么此值代表每个人脸减去平均脸之后的矩阵], y就是降阶之后新的矩阵向量。
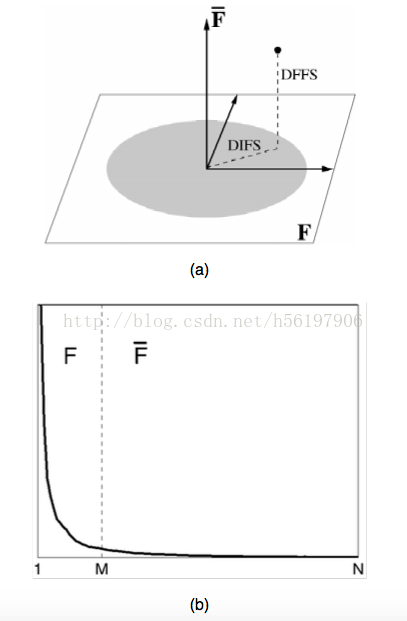
图(a)表示解耦后的空间,以及解耦后原矩阵位于两个F 和F~中的分量。我们用DFFS(distance from feature space 来表征被忽略的部分,DIFS(distance in feature space)来表征被提取的部分)
图(b)是特征值的值谱,我们可以看到最大的前M个 被分到F 中,之后的被分到F~中,并且我们可以看到特征值得下降是非常迅速的,这也是为什么我们可以选择前M个来表示原矩阵。
在KL展开式中,剩余部分造成的误差用
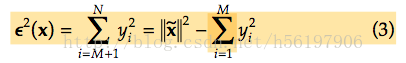
来表示,yi表示降阶矩阵中的每一个向量。而DFFS的欧式长度应该等于这部分误差。
3.概率定义部分
由于我们是从高斯分布开始,那么认为P(x | Ω)应该如(4)所示,而Mahalanobis
距离[对于一个均值为μ,协方差矩阵为Σ的多变量向量,其马氏距离为sqrt( (x-μ)'Σ^(-1)(x-μ) )。]应该如(6)
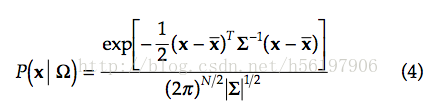
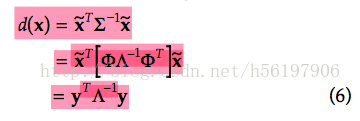

∑是协方差,因为Λ是特征值矩阵,所以马氏距离d(x)变成了(7)。
如果我们把(7)分成两部分,一部分位于F中,一部分位于F~中,则(7)就变成了如下所示:

在工程中,M 是一个较小的数,因为我们降阶了,而d(x)的第二部分,由于N 是比较大的,所以第二部分的和还是很难计算。此时对照(3)来看,我们发现第二部分的和应该和ε^2(x)有关,而由特征值λi产生的系数我们用ρ来表示,因此(8)变成了如下所示。
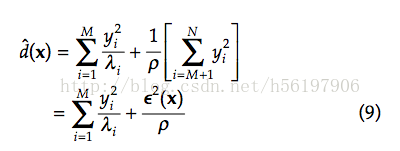
将d^(x) 带入到(4)中,我们得到了:
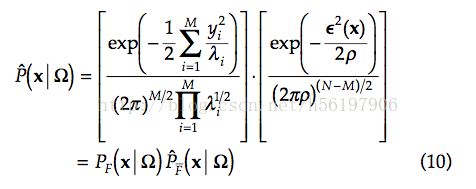
在这里我们看到,乘积第一部分是x在F空间中的相似程度,而第二部分是x在F~空间中的相似程度。而接下来我们只要找到一个对应的ρ 来表示这个式子即可。由于篇幅问题,之后的部分放在(2)中继续讨论。
Object Representation。读完收货很多,故而写下这篇博客。一是为了与大家分享,二来也是为了留下点东西,日后可以翻阅。本文将翻译一部分论文内容,并会加上自己的见解。
1.介绍
本文提供了一种方法,用于在一副图像中寻找某一个物体,并定位该物体在图像中的位置。例如,在一幅图像中寻找指定的建筑物,或者在一幅合照中找到某一个人,并定位该人脸的位置。本文还是基于PCA的,即将高阶的图像在特征空间上解耦,将其转化到低阶的空间中,便于计算。文中有两种图像值分布的假设:(1)单一的高斯分布(单一的高斯分布)(2)混合的高斯分布(多模型的分布)[这里解释下图像值分布,就是将一副完整的图像上每一点的像素值映射到0到255,观察是否符合高斯,我下面的例子就是一个混合的高斯分布,因为有多个波峰,所以可以想象成是多个高斯分布的叠加]。
raw_image = imread('/Users/apple/Desktop/test.jpeg');
gray_image = rgb2gray(raw_image);
[row,col] = size(gray_image);
range = zeros(1,256);
for i = 1:row
for j = 1:col
range(1,gray_image(i,j)+1) = range(1,gray_image(i,j)+1)+1;
end
end
plot(range);因此,识别和定位问题就变成了我们找到这样的(i , j)使得以i,j为中心的子图像和需要寻找的物品匹配。
[S(i,j) 就是图像I中左上角坐标为(i , j),r*c大小的一个子图像]
作者计算了每个候选点的匹配的概率P(x | Ω)[x 是每一个子图像,Ω是目标物体class中的实例],并找出最大的概率(maximum likelihood),则该位置就是匹配的位置。
2.关于PCA
关于PCA的描述,网上的文章很多,在这里不再多说很多细节,需要主要的是,PCA 将高阶的矩阵解耦到低阶的矩阵是通过:
(1)将原矩阵映射到对应的特征空间[Φ,N*N]中[这时候是不发生降阶,即每个值都是one to one maping的,特征空间由每个与特征值相对应的特征向量组成,每个特征向量都正交,可以把每个特征向量想象成空间中的一根坐标轴,而特征值就是在这根坐标轴上的值,也就是说原矩阵被映射到了一个新的坐标空间中,而特征值就是每根坐标轴上的点]。
(2)这一步中,我们将特征向量按照特征值的大小进行排列,然后我们选取前top M个特征值对应的特征向量,降阶是发生在这一步中的,因为我们选了前top M个,也就选择在对应特征向量分量最大的前M个,而剩下的 因为在该特征向量上的分量比较小,所以可以被忽略,但是这部分产生的误差是不可避免的,在下文的方法中,这部分的误差有所体现。我们用F
= {Φi, i from 1 to M} 来表示被选择的特征空间,F~ = {Φi, i from M+1 to N} 来表示被忽略的特征空间。
x~ = x - x_,
x_ 是所有的实例的平均,而 x~是所有object-class中的实例的减去平均之后剩余的部分[如果是人脸检测的话,那么此值代表每个人脸减去平均脸之后的矩阵], y就是降阶之后新的矩阵向量。
图(a)表示解耦后的空间,以及解耦后原矩阵位于两个F 和F~中的分量。我们用DFFS(distance from feature space 来表征被忽略的部分,DIFS(distance in feature space)来表征被提取的部分)
图(b)是特征值的值谱,我们可以看到最大的前M个 被分到F 中,之后的被分到F~中,并且我们可以看到特征值得下降是非常迅速的,这也是为什么我们可以选择前M个来表示原矩阵。
在KL展开式中,剩余部分造成的误差用
来表示,yi表示降阶矩阵中的每一个向量。而DFFS的欧式长度应该等于这部分误差。
3.概率定义部分
由于我们是从高斯分布开始,那么认为P(x | Ω)应该如(4)所示,而Mahalanobis
距离[对于一个均值为μ,协方差矩阵为Σ的多变量向量,其马氏距离为sqrt( (x-μ)'Σ^(-1)(x-μ) )。]应该如(6)
∑是协方差,因为Λ是特征值矩阵,所以马氏距离d(x)变成了(7)。
如果我们把(7)分成两部分,一部分位于F中,一部分位于F~中,则(7)就变成了如下所示:
在工程中,M 是一个较小的数,因为我们降阶了,而d(x)的第二部分,由于N 是比较大的,所以第二部分的和还是很难计算。此时对照(3)来看,我们发现第二部分的和应该和ε^2(x)有关,而由特征值λi产生的系数我们用ρ来表示,因此(8)变成了如下所示。
将d^(x) 带入到(4)中,我们得到了:
在这里我们看到,乘积第一部分是x在F空间中的相似程度,而第二部分是x在F~空间中的相似程度。而接下来我们只要找到一个对应的ρ 来表示这个式子即可。由于篇幅问题,之后的部分放在(2)中继续讨论。

相关文章推荐
- 视觉学习中对象检测到的概率(2)(Probabilistic Visual Learning for Object Representation)
- 素描令牌:一个中层的学习轮廓和目标检测的表征Sketch Tokens: A Learned Mid-level Representation for Contour and Object Detec
- Deep Auxiliary Learning for Visual Localization and Odometry 基于深度辅助学习的视觉定位和里程计
- Learning a Deep Compact Image Representation for Visual Tracking
- Deep Neural Networks for Object Detection(基于DNN的对象检测)
- 深度学习入门:Supervised Hashing for Image Retrieval via Image Representation Learning
- Learning Dynamic Siamese Network for Visual Object Tracking 阅读笔记
- 漫谈基于模型的强化学习方法 PILCO - Probabilistic Inference for Learning Control
- 【深度学习:目标检测】RCNN学习笔记(2):Rich feature hierarchies for accurate object detection and semantic segmentat
- Deep Learning Features at Scale for Visual Place Recognition 用于地点识别的大规模深度学习算法
- 对抗学习用于目标检测--A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
- Joint Deep Learning For Pedestrian Detection(论文笔记-深度学习:行人检测)
- 对抗学习用于目标检测--A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
- cascade learning 级联学习 learning SURF Cascade for Fast band Accurate Object Detection
- 对抗学习用于目标检测--A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
- 【深度学习:目标检测】RCNN学习笔记(1):Rich feature hierarchies for accurate object detection and semantic segmentat
- Incremental Learning for Robust Visual Tracking学习笔记二之warpimg
- DL学习笔记16 Structured Probabilistic Models for Deep Learning
- Learning a Deep Compact Image Representation for Visual Tracking的部分翻译和个人理解
- 对象检测(object detection)