Batch GD/Mini-batch GD/SGD/Mini-batch SGD/Online GD
2017-04-03 23:28
260 查看
用下面的损失函数来作为例子:
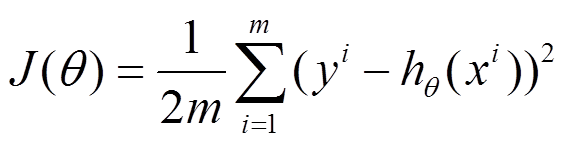
参数更新公式为:
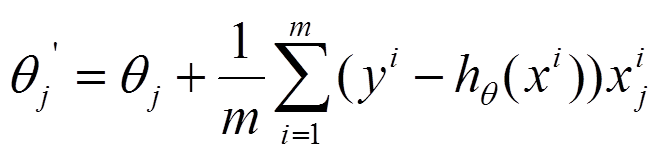
1. Batch GD
对于 Batch GD, m 是整个 batch 大小, 它用整个集合的数据来更新参数。
2. Mini-batch GD
整个 batch 被分为几个小的 mini-batches, m 是 mini-batch 的大小。
3. SGD/Mini-batch SGD
m=1,在所有数据上迭代直到收敛。这其实是
batch size 为1的 Mini-batch GD 的特殊情况。
4. Online GD
m=1,但是每一个数据用完后就被丢弃不再使用。
参数更新公式为:
1. Batch GD
对于 Batch GD, m 是整个 batch 大小, 它用整个集合的数据来更新参数。
2. Mini-batch GD
整个 batch 被分为几个小的 mini-batches, m 是 mini-batch 的大小。
3. SGD/Mini-batch SGD
m=1,在所有数据上迭代直到收敛。这其实是
batch size 为1的 Mini-batch GD 的特殊情况。
4. Online GD
m=1,但是每一个数据用完后就被丢弃不再使用。

相关文章推荐
- 【原创】batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD -- 大数据背景下的梯度训练算法
- batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD -- 大数据背景下的梯度训练算法
- 关于梯度下降batch-GD,SGD,Mini-batch-GD,Stochastic GD,Online-GD的介绍
- batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD -- 大数据背景下的梯度训练算法
- batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD -- 大数据背景下的梯度训练算法
- batch-GD,Mini-batch-GD, SGD, Online-GD
- batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD
- batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD
- 关于梯度训练介绍,batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD
- BGD(Batch Gradient Descent), SGD (Stochastic Gradient Descent), MBGD (Mini-Batch Gradient Descent)
- 梯度下降(BGD)、随机梯度下降(SGD)、Mini-batch Gradient Descent、带Mini-batch的SGD
- 大规模机器学习:SGD,mini-batch和MapReduce
- tensorflow实现最基本的神经网络 + 对比GD、SGD、batch-GD的训练方法
- 大规模机器学习:SGD,mini-batch和MapReduce
- 梯度下降(BGD)、随机梯度下降(SGD)、Mini-batch Gradient Descent、带Mini-batch的SGD
- tensorflow实现最基本的神经网络 + 对比GD、SGD、batch-GD的训练方法
- 梯度下降(BGD)、随机梯度下降(SGD)、Mini-batch Gradient Descent、带Mini-batch的SGD
- [Machine Learning] 梯度下降(BGD)、随机梯度下降(SGD)、Mini-batch Gradient Descent、带Mini-batch的SGD
- Online和Batch任务的区别
- faster-rcnn 之 基于roidb get_minibatch(数据准备操作)