Hadoop 3.0.0-alpha2安装(一)
2017-04-01 11:44
441 查看
1、集群部署概述
1.1 Hadoop简介
研发要做数据挖掘统计,需要Hadoop环境,便开始了本次安装测试,仅仅使用了3台虚拟机做测试工作。 简介……此处省略好多……,可自行查找 …… 从你找到的内容可以总结看到,NameNode和JobTracker负责分派任务,DataNode和TaskTracker负责数据计算和存储。这样集群中可以有一台NameNode+JobTracker,N多台DataNode和TaskTracker。### 直接从word文档中拷贝到博客编辑后台的,看官注意个别空格等问题!1.2版本信息
本次测试安装所需软件版本信息如表1-1所示。表1-1:软件版本信息| 名称 | 版本信息 |
| 操作系统 | CentOS-6.8-x86_64-bin-DVD1.iso |
| Java | jdk-8u121-linux-x64.tar.gz |
| Hadoop | hadoop-3.0.0-alpha2.tar.gz |
1.3测试环境说明
本实验环境是在虚拟机中安装测试的,Hadoop集群中包括1个Master,2个Salve,节点之间内网互通,虚拟机主机名和IP地址如表1-2所示。| 主机名 | 模拟外网IP地址(eth1) | 备注 |
| master | 192.168.24.15 | NameNode+JobTracker |
| slave1 | 192.168.24.16 | DataNode+TaskTracker |
| slave2 | 192.168.24.17 | DataNode+TaskTracker |
2、操作系统设置
1、安装常用软件### 由于操作系统是最小化安装,所以安装一些常用的软件包# yum install gcc gcc-c++ openssh-clients vimmake ntpdate unzip cmake tcpdump openssl openssl-devel lzo lzo-devel zlibzlib-devel snappy snappy-devel lz4 lz4-devel bzip2 bzip2-devel cmake wget2、修改主机名# vim /etc/sysconfig/network # 其他两个节点分别是:slave1和slave2NETWORKING=yesHOSTNAME=master3、配置hosts文件# vim /etc/hosts # master和slave服务器上均添加以下配置内容10.0.24.15 master10.0.24.16 slave110.0.24.17 slave24、创建账号# useradd hadoop5、文件句柄设置# vim/etc/security/limits.conf* soft nofile 65000* hard nofile 65535$ ulimit -n # 查看6、系统内核参数调优sysctl.confnet.ipv4.ip_forward = 0net.ipv4.conf.default.rp_filter = 1net.ipv4.conf.default.accept_source_route = 0kernel.sysrq = 0kernel.core_uses_pid = 1net.ipv4.tcp_syncookies = 1kernel.msgmnb = 65536kernel.msgmax = 65536kernel.shmmax = 68719476736kernel.shmall = 4294967296net.ipv4.tcp_max_tw_buckets = 60000net.ipv4.tcp_sack = 1net.ipv4.tcp_window_scaling = 1net.ipv4.tcp_rmem = 4096 87380 4194304net.ipv4.tcp_wmem = 4096 16384 4194304net.core.wmem_default = 8388608net.core.rmem_default = 8388608net.core.rmem_max = 16777216net.core.wmem_max = 16777216net.core.netdev_max_backlog = 262144net.core.somaxconn = 262144net.ipv4.tcp_max_orphans = 3276800net.ipv4.tcp_max_syn_backlog = 262144net.ipv4.tcp_timestamps = 0net.ipv4.tcp_synack_retries = 1net.ipv4.tcp_syn_retries = 1net.ipv4.tcp_tw_recycle = 1net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_mem = 94500000 915000000 927000000net.ipv4.tcp_fin_timeout = 1net.ipv4.tcp_keepalive_time = 1200net.ipv4.tcp_max_syn_backlog = 65536net.ipv4.tcp_timestamps = 0net.ipv4.tcp_synack_retries = 2net.ipv4.tcp_syn_retries = 2net.ipv4.tcp_tw_recycle = 1#net.ipv4.tcp_tw_len = 1net.ipv4.tcp_tw_reuse = 1#net.ipv4.tcp_fin_timeout = 30#net.ipv4.tcp_keepalive_time = 120net.ipv4.ip_local_port_range = 1024 65535 7、关闭SELINUX# vim /etc/selinux/config #SELINUX=enforcing #SELINUXTYPE=targeted SELINUX=disabled # reboot # 重启服务器生效8、配置ssh# vim /etc/ssh/sshd_config # 去掉以下内容前“#”注释HostKey /etc/ssh/ssh_host_rsa_keyRSAAuthentication yesPubkeyAuthentication yesAuthorizedKeysFile .ssh/authorized_keys# /etc/init.d/sshd restart9、配置master和slave间无密码互相登录(1)maseter和slave服务器上均生成密钥# su - hadoop$ssh-keygen -b 1024 -t rsaGenerating public/private rsa key pair.Enter file in which to save the key(/root/.ssh/id_rsa): <–直接输入回车Enter passphrase (empty for no passphrase): <–直接输入回车Enter same passphrase again: <–直接输入回车Your identification has been saved in/root/.ssh/id_rsa.Your public key has been saved in/root/.ssh/id_rsa.pub.The key fingerprint is: ……注意:在程序提示输入 passphrase 时直接输入回车,表示无证书密码。(2)maseter和slave服务器上hadoop用户下均创建authorized_keys文件$ cd .ssh$ vim authorized_keys # 添加master和salve服务器上hadoop用户下id_rsa.pub文件内容ssh-rsa AAAAB3Nza…省略…HxNDk= hadoop@masterssh-rsa AAAAB3Nza…省略…7CmlRs= hadoop@slave1ssh-rsa AAAAB3Nza…省略…URmXD0= hadoop@slave2$ chmod 644 authorized_keys$ ssh -p2221 hadoop@10.0.24.16 $ ssh -p2221 slave1 # 分别测试ssh连通性3、Java环境安装
### Hadoop集群均需安装Java环境# mkdir /data && cd /data# tar zxf jdk-8u121-linux-x64.tar.gz# ln -sv jdk1.8.0_121 jdk# chown -R root. jdk*# cat >> /etc/profile.d/java.sh<<'EOF'# Set jave environmentexport JAVA_HOME=/data/jdkexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/libexport PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/binEOF # source /etc/profile # 及时生效 # java -version或# javac-version # 查看版本信息4、Hadoop集群安装
4.1 master上安装Hadoop
# cd /data# hadoop-3.0.0-alpha2.tar.gz# ln -sv hadoop-3.0.0-alpha2 hadoop # mkdir -p /data/hadoop/logs # chown -Rhadoop:hadoop /data/hadoop/logs# mkdir -p /data/hadoop/tmp # 配置文件core-site.xml中配置使用# mkdir -p /data/{hdfsname1,hdfsname2}/hdfs/name# mkdir -p /data/{hdfsdata1,hdfsdata2}/hdfs/data# chown -R hadoop:hadoop /data/hdfs*# 以上四个文件目录hadfs-site.xml中配置使用# cat >> /etc/profile.d/hadoop.sh<<'EOF'# Set hadoop environmentexport HADOOP_HOME=/data/hadoopexport PATH=$PATH:$HADOOP_HOME/binEOF # source /etc/profile# chown -R hadoop:hadoop hadoop*4.2 master上配置Hadoop
# cd /data/hadoop/etc/hadoop4.2.1 hadoop-env.sh
# vim hadoop-env.sh # master和slave末行均添加# Set jave environmentexport JAVA_HOME=/data/jdkexport HADOOP_SSH_OPTS="-p 2221"4.2.2 core-site.xml
# vim core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/tmp</value> </property> <property> <name>io.compression.codecs</name> <value>org.apache.hadoop.io.compress.DefaultCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec,org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.BZip2Codec</value> </property> <property> <name>io.compression.codec.lzo.class</name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property></configuration>### 说明:第1个<property>:定义hdfsnamenode的主机名和端口,本机,主机名在/etc/hosts设置第2个<property>:定义如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删掉,必须重新执行format才行,否则会出错。默认是NameNode、DataNode、JournalNode等存放数据的公共目录。用户也可以自己单独指定这三类节点的目录。这里的/data/hadoop/tmp目录与文件都是自己创建的,配置后在格式化namenode的时候也会自动创建。 第3个<property>:定义hdfs使用压缩(本次测试暂时关闭了本项目,可以注释掉)第4个<property>:定义压缩格式和解码器类(本次测试暂时关闭了本项目,可以注释掉)4.2.3 hdfs-site.xml
# vim hdfs-site.xml<configuration> <property> <name>dfs.name.dir</name> <value>file:///data/hdfsname1/hdfs/name,file:// /data/hdfsname2/hdfs/name</value> <description> </description> </property> <property> <name>dfs.data.dir</name> <value>file:///data/hdfsdata1/hdfs/data,file:///data/hdfsdata2/hdfs/data</value> <description> </description> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.datanode.du.reserved</name> <value>1073741824</value> </property> <property> <name>dfs.block.size</name> <value>134217728</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property></configuration>第1个<property>:定义hdfs Namenode持久存储名字空间、事务日志路径。多路径可以使用“,”分割,这里配置模拟了多磁盘挂载。第2个<property>:定义本地文件系统上DFS数据节点应存储其块的位置。可以逗号分隔目录列表,则数据将存储在所有命名的目录中,通常在不同的设备上。第3个<property>:定义DataNode存储block的副本数量。默认值是3个,我们现在有2个 DataNode,该值不大2即可,份数越多越安全,但速度越慢。第4个<property>:定义du操作返回。第5个<property>:定义hdfs的存储块大小,默认64M,我用的128M。第6个<property>:权限设置,最好不要。4.2.4 mapred-site.xml
# cp -a mapred-site.xml.templatemapred-site.xml # vim mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /data/hadoop/etc/hadoop, /data/hadoop/share/hadoop/common/*, /data/hadoop/share/hadoop/common/lib/*, /data/hadoop/share/hadoop/hdfs/*, /data/hadoop/share/hadoop/hdfs/lib/*, /data/hadoop/share/hadoop/mapreduce/*, /data/hadoop/share/hadoop/mapreduce/lib/*, /data/hadoop/share/hadoop/yarn/*, /data/hadoop/share/hadoop/yarn/lib/* </value> </property></configuration>###说明:上面的mapreduce.application.classpath一开始没有配置,导致使用mapreduce时报错Error: Could not find or load main classorg.apache.hadoop.mapreduce.v2.app.MRAppMaster4.2.5 yarn-site.xml
# vim yarn-site.xml<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property></configuration>第1个<property>:定义指的是运行ResourceManager机器所在的节点.第2个<property>:定义在hadoop2.2.0版本中是mapreduce_shuffle,一定要看清楚。### 注意:本次测试使用了默认文件,没有添加任何内容。4.2.6 workers
# vim workers # 配置slave的主机名,否则slave节点不启动slave1slave24.3 slava上安装Hadoop
复制主节点master上的hadoop安装配置环境到所有的slave上,切记:目标路径要与master保持一致。$ scp -P2221 hadoop.tar.gzhadoop@slave1:/home/hadoop$ scp -P2221 hadoop.tar.gzhadoop@slave2:/home/hadoop4.4配置防火墙
### 实验时可以关闭防火墙,避免不必要的麻烦,等后续陆续调试4.5 Hadoop启动及其验证
4.5.1 master上格式化HDFS文件系统
### 注意回到master服务器上执行如下操作:# su - hadoop$ /data/hadoop/bin/hdfsnamenode -format # 显示如下内容:2017-03-15 19:02:50,062 INFO namenode.NameNode:STARTUP_MSG:/************************************************************STARTUP_MSG: Starting NameNodeSTARTUP_MSG: user = hadoopSTARTUP_MSG: host = master/10.0.24.15STARTUP_MSG: args = [-format]STARTUP_MSG: version = 3.0.0-alpha2……此处省略好多……Re-format filesystem in Storage Directory/data/hdfsname1/hdfs/name ? (Y or N) yRe-format filesystem in Storage Directory/data/hdfsname2/hdfs/name ? (Y or N) y……此处省略好多……2017-03-15 19:03:48,703 INFO namenode.FSImage:Allocated new BlockPoolId: BP-1344030132-10.0.24.15-1489575828688……此处省略好多……2017-03-15 19:03:48,999 INFO util.ExitUtil: Exitingwith status 02017-03-15 19:03:49,002 INFO namenode.NameNode:SHUTDOWN_MSG:/************************************************************SHUTDOWN_MSG: Shutting down NameNode atmaster/10.0.24.15************************************************************/4.5.2 启动校验停止集群
$ cd /data/hadoop/sbin # master服务器上操作(1)$ ./start-all.sh # 启动 # 显示内容:WARNING WARN暂时没有解决,详见5、FAQ内WARNING: Attempting to start all Apache Hadoopdaemons as hadoop in 10 seconds.WARNING: This is not a recommended productiondeployment configuration.WARNING: Use CTRL-C to abort.Starting namenodes on [master]Starting datanodesStarting secondary namenodes [master]2017-03-21 18:51:03,092 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicableStarting resourcemanagerStarting nodemanagers(2)$ /data/jdk1.8.0_121/bin/jps # master上查看进程9058 SecondaryNameNode9272 ResourceManager9577 RunJar8842 NameNode9773 Jps(3)$ /data/jdk1.8.0_121/bin/jps # slave1\slave2上查看进程5088 DataNode5340 Jps5213 NodeManager(4)$ ./stop-all.sh # master服务器上操作停止集群WARNING: Stopping all Apache Hadoop daemons as hadoopin 10 seconds.WARNING: Use CTRL-C to abort.Stopping namenodes on [master]Stopping datanodesStopping secondary namenodes [master]2017-03-21 18:57:20,746 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicableStopping nodemanagersslave1: WARNING: nodemanager did not stop gracefullyafter 5 seconds: Trying to kill with kill -9slave2: WARNING: nodemanager did not stop gracefullyafter 5 seconds: Trying to kill with kill -9Stopping resourcemanager(5)$ /data/jdk1.8.0_121/bin/jps # 再次查看进程都已经正常关闭11500 Jps(6)Web页面1)http://192.168.24.15:8088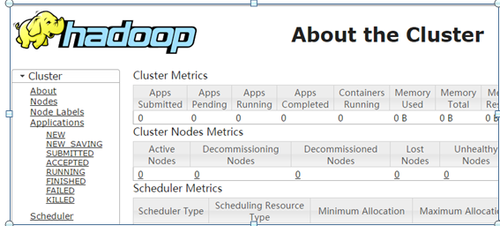
2)http://192.168.24.15:9870
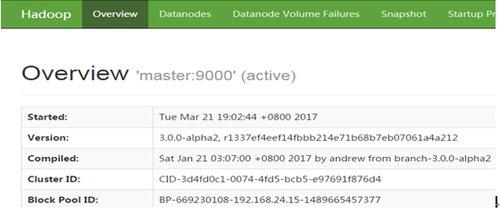
4.5.3 Mapreduce程序测试
$ cd /data/hadoop/bin1、第一种测试方法:$ hadoop jar../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0-alpha2.jar pi 1 1 #说明成功
Number of Maps = 1
Samples per Map = 1
Wrote input for Map #0
Starting Job
2017-04-01 05:34:34,150 INFO client.RMProxy:Connecting to ResourceManager at master/192.168.24.15:8032
2017-04-01 05:34:35,765 INFO input.FileInputFormat:Total input files to process : 1
2017-04-01 05:34:35,876 INFO mapreduce.JobSubmitter:number of splits:1
2017-04-01 05:34:35,926 INFOConfiguration.deprecation:yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead,use yarn.system-metrics-publisher.enabled
2017-04-01 05:34:36,402 INFO mapreduce.JobSubmitter:Submitting tokens for job: job_1490957345671_0007
2017-04-01 05:34:36,939 INFO impl.YarnClientImpl:Submitted application application_1490957345671_0007
2017-04-01 05:34:37,085 INFO mapreduce.Job: The urlto track the job: http://master:8088/proxy/application_1490957345671_0007/ 2017-04-01 05:34:37,086 INFO mapreduce.Job: Runningjob: job_1490957345671_0007
2017-04-01 05:34:47,336 INFO mapreduce.Job: Jobjob_1490957345671_0007 running in uber mode : false
2017-04-01 05:34:47,340 INFO mapreduce.Job: map 0% reduce 0%
2017-04-01 05:34:57,496 INFO mapreduce.Job: map 100% reduce 0%
2017-04-01 05:35:05,574 INFO mapreduce.Job: map 100% reduce 100%
2017-04-01 05:35:05,588 INFO mapreduce.Job: Jobjob_1490957345671_0007 completed successfully
2、第二种测试方式:
(1)生成HDFS请求目录执行MapReduce任务$ hdfs dfs -mkdir /user $ hdfs dfs -mkdir /user/hduser(2)将输入文件拷贝到分布式文件系统$ hdfs dfs -mkdir /user/hduser/input$ hdfs dfs -put ../etc/hadoop/yarn-site.xml /user/hduser/input(2)运行提供的示例程序$ hadoop jar../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0-alpha2.jar grep/user/hduser/input/yarn-site.xml output 'dfs[a-z.]+'……省略……2017-03-31 10:58:46,650 INFO mapreduce.Job: map 100% reduce 100%2017-03-31 10:58:46,664 INFO mapreduce.Job: Jobjob_1490957345671_0003 completed successfully2017-03-31 10:58:46,860 INFO mapreduce.Job: Counters:49……省略……http://192.168.24.15:9870里可以看到:

### 由于博客文字限制,只能分开写了:
Hadoop 3.0.0-alpha2安装(二)链接: http://laowafang.blog.51cto.com/251518/1912345刘政委 2017-04-01

相关文章推荐
- Hadoop 3.0.0-alpha2安装(三)之Python编写MapReduce
- 小白学习大数据之路——Hadoop3.0.0-alpha2 安装以及测试程序wordcount实践
- hadoop 3.0.0 alpha3 安装、配置
- hadoop 3.0.0 alpha3 安装、配置
- hadoop 3.0.0 alpha3 安装、配置
- Centos 7 安装Hadoop 3.0.0-alpha1
- Hadoop 3.0.0-alpha2安装(二)
- 编译Hadoop-3.0.0-alpha1本地库+snappy
- cmake的使用实例: opencv-3.0.0-alpha安装
- 安装opencv3.0.0-alpha 后出现“CV_BGR2GRAY”: 未声明的标识符的解决办法
- 红帽LINUX 5下安装Hadoop 2.0.0-alpha
- 大数据生态系统基础:Hadoop(二):Hadoop 3.0.0集群安装和验证
- hadoop 3.0.0 alpha1 分布式搭建
- Hadoop 3.0.0-alpha1几个值得关注的特性
- hadoop-3.0.0-beta1运维手册(002):安装Guest操作系统
- CentOS6.2上安装Hadoop-2.0.0-alpha(独立版)和jdk7u4
- 安装opencv3.0.0-alpha 后出现“CV_BGR2GRAY”: 未声明的标识符的解决办法
- ubuntu 14.04 install hadoop 3.0.0 alpha1
- Hadoop-2.0.2-alpha安装 CentOs6.2 jdk1.7