机器学习与数据挖掘之决策树
2017-03-26 11:54
260 查看
参考文献:机器学习与数据挖掘参考文献
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部结点和叶结点。内部结点表示一个特征或属性,叶结点表示一个类。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。决策树学习用损失函数表示这一目标。决策树学习的损失函数通常是正则化的极大似然函数。决策树学习的策略是以损失函数为目标函数的最小化。
当损失函数确定以后,学习问题就变为在损失函数意义下选择最优决策树的问题。因为从所有可能的决策树中选取最优决策树是NP完全问题,所以现实中决策树学习算法通常采用启发式方法,近似求解这一最优化问题。这样得到的决策树是次最优的。
决策树的生成对应于模型的局部选择,决策树的剪枝对应于模型的全局选择。决策树的生成只考虑局部最优,相对地,决策树的剪枝则考虑全局最优。
通常决策树特征选择的准则有三种:信息增益(ID3)、信息增益比(C4.5)和基尼指数(CART)。
ID3算法
信息增益算法:
输入:训练数据集D和特征A;
输出:特征A对训练数据集D的信息增益g(D,A)。
(1)计算数据集D的经验熵H(D)

(2)计算特征A对数据集D的经验条件熵H(D|A)
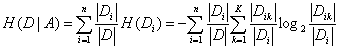
(3)计算信息增益
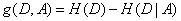
C4.5算法
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题,使用信息增益比可以对这一问题进行校正。
特征A
4000
对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D关于特征A的值的熵HA(D)之比,即
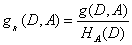
其中,
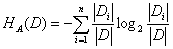
,n是特征A取值的个数。
ID3和C4.5的生成算法如下:
输入:训练数据集D,特征集A,阈值ε;
输出:决策树T。
(1)如果D中所有实例属于同一类Ck,则置T为单结点树,并将Ck作为该结点的类,返回T;
(2)如果A=∅,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
(3)否则,计算A中各特征对D的信息增益(ID3)或信息增益比(C4.5),选择信息增益或信息增益比最大的特征Ag;
(4)如果Ag的信息增益或信息增益比小于阈值ε,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
(5)否则,对Ag的每一种可能ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6)对结点i,以Di为训练集,以A-{Ag}为特征集,递归地调用步(1)~步(5),得到子树Ti,返回T。
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部结点和叶结点。内部结点表示一个特征或属性,叶结点表示一个类。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。决策树学习用损失函数表示这一目标。决策树学习的损失函数通常是正则化的极大似然函数。决策树学习的策略是以损失函数为目标函数的最小化。
当损失函数确定以后,学习问题就变为在损失函数意义下选择最优决策树的问题。因为从所有可能的决策树中选取最优决策树是NP完全问题,所以现实中决策树学习算法通常采用启发式方法,近似求解这一最优化问题。这样得到的决策树是次最优的。
决策树的生成对应于模型的局部选择,决策树的剪枝对应于模型的全局选择。决策树的生成只考虑局部最优,相对地,决策树的剪枝则考虑全局最优。
通常决策树特征选择的准则有三种:信息增益(ID3)、信息增益比(C4.5)和基尼指数(CART)。
ID3算法
信息增益算法:
输入:训练数据集D和特征A;
输出:特征A对训练数据集D的信息增益g(D,A)。
(1)计算数据集D的经验熵H(D)
(2)计算特征A对数据集D的经验条件熵H(D|A)
(3)计算信息增益
C4.5算法
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题,使用信息增益比可以对这一问题进行校正。
特征A
4000
对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D关于特征A的值的熵HA(D)之比,即
其中,
,n是特征A取值的个数。
ID3和C4.5的生成算法如下:
输入:训练数据集D,特征集A,阈值ε;
输出:决策树T。
(1)如果D中所有实例属于同一类Ck,则置T为单结点树,并将Ck作为该结点的类,返回T;
(2)如果A=∅,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
(3)否则,计算A中各特征对D的信息增益(ID3)或信息增益比(C4.5),选择信息增益或信息增益比最大的特征Ag;
(4)如果Ag的信息增益或信息增益比小于阈值ε,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类,返回T;
(5)否则,对Ag的每一种可能ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6)对结点i,以Di为训练集,以A-{Ag}为特征集,递归地调用步(1)~步(5),得到子树Ti,返回T。

相关文章推荐
- 机器学习、大数据、深度学习、数据挖掘、统计、决策和风险分析、概率和模糊逻辑的常见问题解答
- 机器学习、大数据、深度学习、数据挖掘、统计、决策和风险分析、概率和模糊逻辑的常见问题解答
- 机器学习、大数据、深度学习、数据挖掘、统计、决策和风险分析、概率和模糊逻辑的常见问题解答
- 加州理工学院公开课:机器学习与数据挖掘_Regularization(第十二课)
- 机器学习与模式识别、数据挖掘的关系
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱
- 机器学习、数据挖掘、计算机视觉等领域经典书籍推荐
- 经典的机器学习方面源代码库(非常全,数据挖掘,计算机视觉,模式识别,信息检索相关领域都适用的了)
- 机器学习与数据挖掘网上资源搜罗——良心推荐
- 数据挖掘、机器学习基础算法
- “R语言机器学习与大数据可视化”暨“Python文本挖掘与自然语言处理”核心技术高级研修班的通知
- 现阶段对数据库中知识发现KDD、数据挖掘、集成学习、深度学习、机器学习、人工智能、统计学、大数据、云计算的个人理解:
- 机器学习和数据挖掘在个性化推荐系统中的应用
- (转) 机器学习与数据挖掘网上资源搜罗——良心推荐
- 数据挖掘与R语言,数据分析,机器学习
- 数据挖掘——学习笔记(机器学习--监督,非监督,半监督学习)
- 数据分析/数据挖掘/机器学习---- 必读书目
- 数据分析/数据挖掘/机器学习---- 必读书目
- 数据挖掘、机器学习和模式识别关系与区别
- [置顶] 经典的机器学习方面源代码库(数据挖掘,计算机视觉,模式识别,信息检索)