HA+Federation集群实现(七)
2017-03-24 09:55
302 查看
集群规划

配置步骤
1、core-site.xml
1)整合Federation和HA的配置
2、hdfs-site.xml
1)添加新增节点配置
3、启动服务
1)zookeeper
2)journalnode
3)datanode
4)namenode
5)zkfc
实施步骤
在原有的ha基础上进行配置,即基于《基于ZK自动切换模式的实现(六)》的基础之上进行配置
1)停止所有服务
[hadoop@master ~]$ hadoop-daemons.sh --hostnames 'master hadoop04' stop zkfc
[hadoop@master ~]$ hadoop-daemons.sh stop datanode
[hadoop@master ~]$ hadoop-daemons.sh --hostnames 'master hadoop04' stop namenode
[hadoop@master ~]$ hadoop-daemons.sh --hostnames 'slave1 slave2 hadoop04' stop journalnode
[hadoop@slave1 ~]$ zkServer.sh stop 《===注意标红处的主机
[hadoop@slave2 ~]$ zkServer.sh stop
[hadoop@hadoop04 ~]$ zkServer.sh stop
2)vi core-site.xml
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="cmt.xml"/>
<property>
<name>fs.defaultFS</name>
<value>viewfs://nsX</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/journalnode/data</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop04:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>
3)vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.ha.namenodes.ns2</name>
<value>nn3,nn4</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2.nn3</name>
<value>slave1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop04:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2.nn4</name>
<value>slave2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop04:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2.nn3</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2.nn4</name>
<value>slave2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop04:8485;slave1:8485;slave2:8485/ns1</value> 《==在slave1和slave2上修改为 ns2
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns2</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
4)同步配置
[hadoop@slave2 ~]$ cd /opt/hadoop/etc/hadoop
[hadoop@slave2 ~]$ scp –r *.xml slave1:/opt/hadoop/etc/hadoop
[hadoop@slave2 ~]$ scp –r *.xml slave2:/opt/hadoop/etc/hadoop
[hadoop@slave2 ~]$ scp -r *.xml hadoop04:/opt/hadoop/etc/hadoop
5)修改slave1、slave2的hdfs-site.xml
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop04:8485;slave1:8485;slave2:8485/ns1</value> 《==在slave1和slave2上修改为
ns2
</property>
6)启动zookeeper集群
[hadoop@slave1 hadoop]$ zkServer.sh start
[hadoop@slave2 hadoop]$ zkServer.sh start
[hadoop@hadoop04 hadoop]$ zkServer.sh start
7)zkfc重新格式化
ON MASTER 《===理论上可以不做,只做slave1上的格式化
[hadoop@master hadoop]$ hdfs zkfc –formatZK
On slave1
[hadoop@slave1 ~]$ hdfs zkfc –formatZK
8)启动journalnode服务
[hadoop@master hadoop]$ hadoop-daemons.sh --hostnames 'slave1 slave2 hadoop04' start journalnode
9)在slave1上执行journalnode的初始化
[hadoop@slave1 ~]$ hdfs namenode –initializeSharedEdits
在以前的ha配置过程中master节点也执行过这个操作
10)格式化slave1
[hadoop@slave1 ~]$ hdfs namenode -format -clusterid hd260
11)启动master的namenode服务
[hadoop@master hadoop]$ hadoop-daemon.sh start namenode
12)hadoop04节点namenode信息同步
[hadoop@hadoop04 hadoop]$ hdfs namenode –bootstrapStandby
13)hadoop04节点 namenode服务启动
[hadoop@hadoop04 hadoop]$ hadoop-daemon.sh start namenode
14) slave1节点namenode服务启动
[hadoop@slave1 ~]$ hadoop-daemon.sh start namenode
15)在slave2上进行namenode信息同步 《==在这里同步跟格式化是一个效果
[hadoop@slave2 hadoop]$ hdfs namenode –bootstrapStandby
16)在slave2上启动namenode
[hadoop@slave2 hadoop]$ hadoop-daemon.sh start namenode
17)启动datanode
[hadoop@master hadoop]$ hadoop-daemons.sh start datanode
18)
[hadoop@master hadoop]$ hadoop-daemons.sh --hostnames 'master slave1 slave2 hadoop04' start zkfc
19)
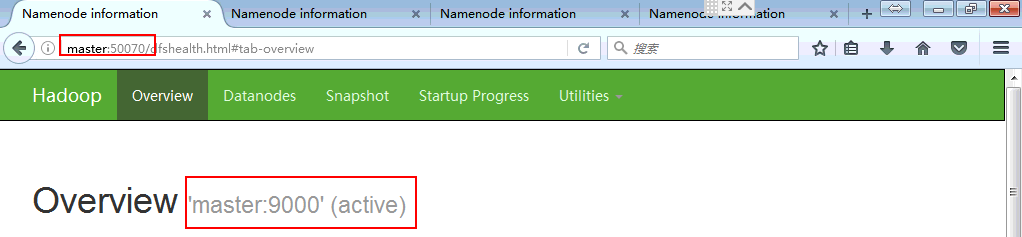
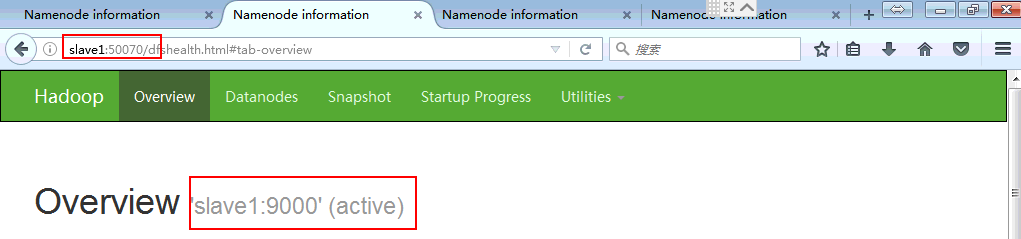
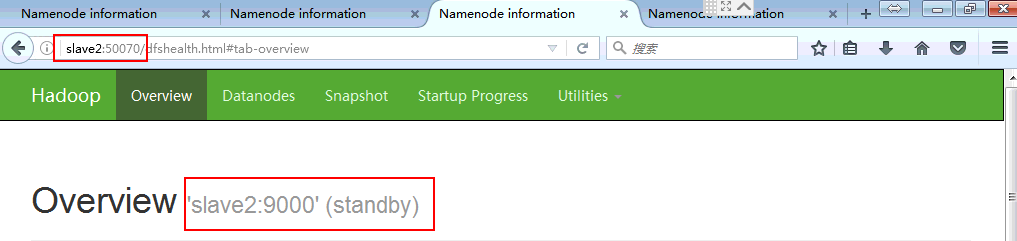
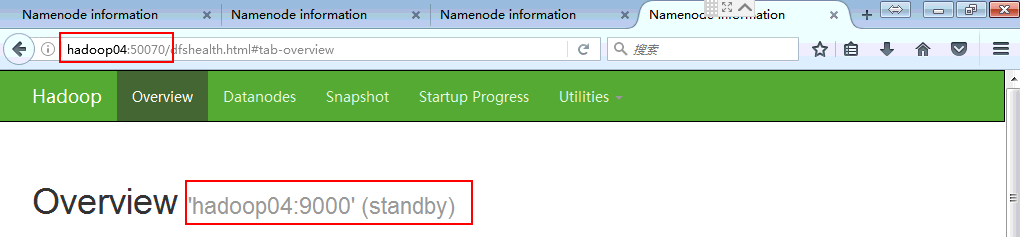
状态正确,配置成功
配置步骤
1、core-site.xml
1)整合Federation和HA的配置
2、hdfs-site.xml
1)添加新增节点配置
3、启动服务
1)zookeeper
2)journalnode
3)datanode
4)namenode
5)zkfc
实施步骤
在原有的ha基础上进行配置,即基于《基于ZK自动切换模式的实现(六)》的基础之上进行配置
1)停止所有服务
[hadoop@master ~]$ hadoop-daemons.sh --hostnames 'master hadoop04' stop zkfc
[hadoop@master ~]$ hadoop-daemons.sh stop datanode
[hadoop@master ~]$ hadoop-daemons.sh --hostnames 'master hadoop04' stop namenode
[hadoop@master ~]$ hadoop-daemons.sh --hostnames 'slave1 slave2 hadoop04' stop journalnode
[hadoop@slave1 ~]$ zkServer.sh stop 《===注意标红处的主机
[hadoop@slave2 ~]$ zkServer.sh stop
[hadoop@hadoop04 ~]$ zkServer.sh stop
2)vi core-site.xml
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="cmt.xml"/>
<property>
<name>fs.defaultFS</name>
<value>viewfs://nsX</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/journalnode/data</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop04:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>
3)vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.ha.namenodes.ns2</name>
<value>nn3,nn4</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2.nn3</name>
<value>slave1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop04:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2.nn4</name>
<value>slave2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop04:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2.nn3</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2.nn4</name>
<value>slave2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop04:8485;slave1:8485;slave2:8485/ns1</value> 《==在slave1和slave2上修改为 ns2
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns2</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
4)同步配置
[hadoop@slave2 ~]$ cd /opt/hadoop/etc/hadoop
[hadoop@slave2 ~]$ scp –r *.xml slave1:/opt/hadoop/etc/hadoop
[hadoop@slave2 ~]$ scp –r *.xml slave2:/opt/hadoop/etc/hadoop
[hadoop@slave2 ~]$ scp -r *.xml hadoop04:/opt/hadoop/etc/hadoop
5)修改slave1、slave2的hdfs-site.xml
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop04:8485;slave1:8485;slave2:8485/ns1</value> 《==在slave1和slave2上修改为
ns2
</property>
6)启动zookeeper集群
[hadoop@slave1 hadoop]$ zkServer.sh start
[hadoop@slave2 hadoop]$ zkServer.sh start
[hadoop@hadoop04 hadoop]$ zkServer.sh start
7)zkfc重新格式化
ON MASTER 《===理论上可以不做,只做slave1上的格式化
[hadoop@master hadoop]$ hdfs zkfc –formatZK
On slave1
[hadoop@slave1 ~]$ hdfs zkfc –formatZK
8)启动journalnode服务
[hadoop@master hadoop]$ hadoop-daemons.sh --hostnames 'slave1 slave2 hadoop04' start journalnode
9)在slave1上执行journalnode的初始化
[hadoop@slave1 ~]$ hdfs namenode –initializeSharedEdits
在以前的ha配置过程中master节点也执行过这个操作
10)格式化slave1
[hadoop@slave1 ~]$ hdfs namenode -format -clusterid hd260
11)启动master的namenode服务
[hadoop@master hadoop]$ hadoop-daemon.sh start namenode
12)hadoop04节点namenode信息同步
[hadoop@hadoop04 hadoop]$ hdfs namenode –bootstrapStandby
13)hadoop04节点 namenode服务启动
[hadoop@hadoop04 hadoop]$ hadoop-daemon.sh start namenode
14) slave1节点namenode服务启动
[hadoop@slave1 ~]$ hadoop-daemon.sh start namenode
15)在slave2上进行namenode信息同步 《==在这里同步跟格式化是一个效果
[hadoop@slave2 hadoop]$ hdfs namenode –bootstrapStandby
16)在slave2上启动namenode
[hadoop@slave2 hadoop]$ hadoop-daemon.sh start namenode
17)启动datanode
[hadoop@master hadoop]$ hadoop-daemons.sh start datanode
18)
[hadoop@master hadoop]$ hadoop-daemons.sh --hostnames 'master slave1 slave2 hadoop04' start zkfc
19)
状态正确,配置成功

相关文章推荐
- RHEL5实现高可用HA集群+GFS+EnterpriseDB
- 使用Heartbeat实现高性能集群--HA
- corosync+pacemaker实现高可用(HA)集群(二)
- HA集群之DRBD实现MySQL高可用
- HA集群之DRBD浅析及实现DRBD高可用 推荐
- RHEL5实现高可用HA集群+GFS+EnterpriseDB
- Heartbeat+MySQL+NFS 实现高可用(HA)的MySQL集群
- 解析RHCS高可用集群HA及负载均衡集群LB的实现方法
- Corosync+Pacemaker+DRBD+MySQL 实现高可用(HA)的MySQL集群 推荐
- Heartbeat+MySQL+NFS 实现高可用(HA)的MySQL集群
- 整合HA和LB来实现高可用的LB集群
- mysql服务器的HA集群之corosync+drbd+pacemaker实现 上
- mysql服务器的HA集群之corosync+drbd+pacemaker实现-下篇
- corosync+pacemaker实现高可用(HA)集群(一)
- corosync+drbd+pacemaker实现mysql服务器的HA集群
- RHEL5 实现高可用HA集群+GFS+EnterpriseDB
- mysql服务器的HA集群之corosync+drbd+pacemaker实现-上篇 推荐
- mysql服务器的HA集群之corosync+drbd+pacemaker实现 下
- 高可用集群HA及负载均衡集群LB的实现方法
- 解析RHCS高可用集群HA及负载均衡集群LB的实现方法