GPU-CUDA编程实践(一)
2017-03-23 14:21
1256 查看
CUDA编程是有一定的流程和套路的

图1 CUDA程序流程
常用CUDA函数说明
1.__host__ cudaError_t cudaMalloc(void **devPtr, size_t size)
该函数主要用来分配设备上的内存(即显存中的内存)。该函数被声明为了__host__,即表示被host所调用,即在cpu中执行的代码所调用。
返回值:为cudaError_t类型,实质为cudaError的枚举类型,其中定义了一系列的错误代码。如果函数调用成功,则返回cudaSuccess。
第一个参数,void ** 类型,devPtr:用于接受该函数所分配的内存地址
第二个参数,size_t类型,size:指定分配内存的大小,单位为字
2.
__host__ cudaError_t cudaFree(void *devPtr)
该函数用来释放先前在设备上申请的内存空间(通过cudaMalloc、cudaMallocPitch等函数),注意,不能释放通过标准库函数malloc进行申请的内存。
返回值:为错误代码的类型值
第一个参数,void**类型,devPtr:指向需要释放的设备内存地址
3.
__host__ cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind)
该函数主要用于将不同内存段的数据进行拷贝,内存可用是设备内存,也可用是主机内存
第一个参数,void*类型,dst:为目的内存地址
第二个参数,const void *类型,src:源内存地址
第三个参数,size_t类型,count:将要进行拷贝的字节大小
第四个参数,enum cudaMemcpyKind类型,kind:拷贝的类型,决定拷贝的方向
cudaMemcpyKind类型如下:
[cpp] view
plain copy
enum __device_builtin__ cudaMemcpyKind
{
cudaMemcpyHostToHost = 0, /**< Host -> Host */
cudaMemcpyHostToDevice = 1, /**< Host -> Device */
cudaMemcpyDeviceToHost = 2, /**< Device -> Host */
cudaMemcpyDeviceToDevice = 3, /**< Device -> Device */
cudaMemcpyDefault = 4 /**< Default based unified virtual address space */
};
cudaMemcpyKind决定了拷贝的方向,即是从主机的内存拷贝至设备内存,还是将设备内存拷贝值主机内存等。cudaMemcpy内部根据拷贝的类型(kind)来决定调用以下的某个函数:
[cpp] view
plain copy
::cudaMemcpyHostToHost,
::cudaMemcpyHostToDevice,
::cudaMemcpyDeviceToHost,
::cudaMemcpyDeviceToDevice
4.
__host__ cudaError_t cudaDeviceReset(void)
该函数销毁当前进程中当前设备上所有的内存分配和重置所有状态,调用该函数达到重新初始该设备的作用。应该注意,在调用该函数时,应该确保该进程中其他host线程不能访问该设备!
下面是一个简单的向量相加的程序
/**
* Copyright 1993-2015 NVIDIA Corporation. All rights reserved.
*
* Please refer to the NVIDIA end user license agreement (EULA) associated
* with this source code for terms and conditions that govern your use of
* this software. Any use, reproduction, disclosure, or distribution of
* this software and related documentation outside the terms of the EULA
* is strictly prohibited.
*
*/
/**
* Vector addition: C = A + B.
*
* This sample is a very basic sample that implements element by element
* vector addition. It is the same as the sample illustrating Chapter 2
* of the programming guide with some additions like error checking.
*/
#include <stdio.h>
// For the CUDA runtime routines (prefixed with "cuda_")
#include <cuda_runtime.h>
#include <helper_cuda.h>
/**
* CUDA Kernel Device code
*
* Computes the vector addition of A and B into C. The 3 vectors have the same
* number of elements numElements.
*/
__global__ void
vectorAdd(const float *A, const float *B, float *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
{
C[i] = A[i] + B[i];
}
}
/**
* Host main routine
*/
int
main(void)
{
// Error code to check return values for CUDA calls
cudaError_t err = cudaSuccess;
// Print the vector length to be used, and compute its size
int numElements = 50000;
size_t size = numElements * sizeof(float);
printf("[Vector addition of %d elements]\n", numElements);
// Allocate the host input vector A
float *h_A = (float *)malloc(size);
// Allocate the host input vector B
float *h_B = (float *)malloc(size);
// Allocate the host output vector C
float *h_C = (float *)malloc(size);
// Verify that allocations succeeded
if (h_A == NULL || h_B == NULL || h_C == NULL)
{
fprintf(stderr, "Failed to allocate host vectors!\n");
exit(EXIT_FAILURE);
}
// Initialize the host input vectors
for (int i = 0; i < numElements; ++i)
{
h_A[i] = rand()/(float)RAND_MAX;
h_B[i] = rand()/(float)RAND_MAX;
}
// Allocate the device input vector A
float *d_A = NULL;
err = cudaMalloc((void **)&d_A, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device vector A (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Allocate the device input vector B
float *d_B = NULL;
err = cudaMalloc((void **)&d_B, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device vector B (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Allocate the device output vector C
float *d_C = NULL;
err = cudaMalloc((void **)&d_C, size);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to allocate device vector C (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Copy the host input vectors A and B in host memory to the device input vectors in
// device memory
printf("Copy input data from the host memory to the CUDA device\n");
err = cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy vector A from host to device (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy vector B from host to device (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Launch the Vector Add CUDA Kernel
int threadsPerBlock = 256;
int blocksPerGrid =(numElements + threadsPerBlock - 1) / threadsPerBlock;
printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, numElements);
err = cudaGetLastError();
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to launch vectorAdd kernel (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Copy the device result vector in device memory to the host result vector
// in host memory.
printf("Copy output data from the CUDA device to the host memory\n");
err = cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to copy vector C from device to host (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Verify that the result vector is correct
for (int i = 0; i < numElements; ++i)
{
if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5)
{
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
}
printf("Test PASSED\n");
// Free device global memory
err = cudaFree(d_A);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device vector A (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaFree(d_B);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device vector B (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
err = cudaFree(d_C);
if (err != cudaSuccess)
{
fprintf(stderr, "Failed to free device vector C (error code %s)!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
// Free host memory
free(h_A);
free(h_B);
free(h_C);
printf("Done\n");
return 0;
}目前CUDA和OpenCL是最主流的两个GPU编程库,CUDA和OpenCL都是原生支持C/C++的,其它语言想要访问还有些麻烦,比如Java,需要通过JNI来访问CUDA或者OpenCL。基于JNI,现今有各种Java版本的GPU编程库,比如JCUDA等。另一种思路就是语言还是由java来编写,通过一种工具将java转换成C。
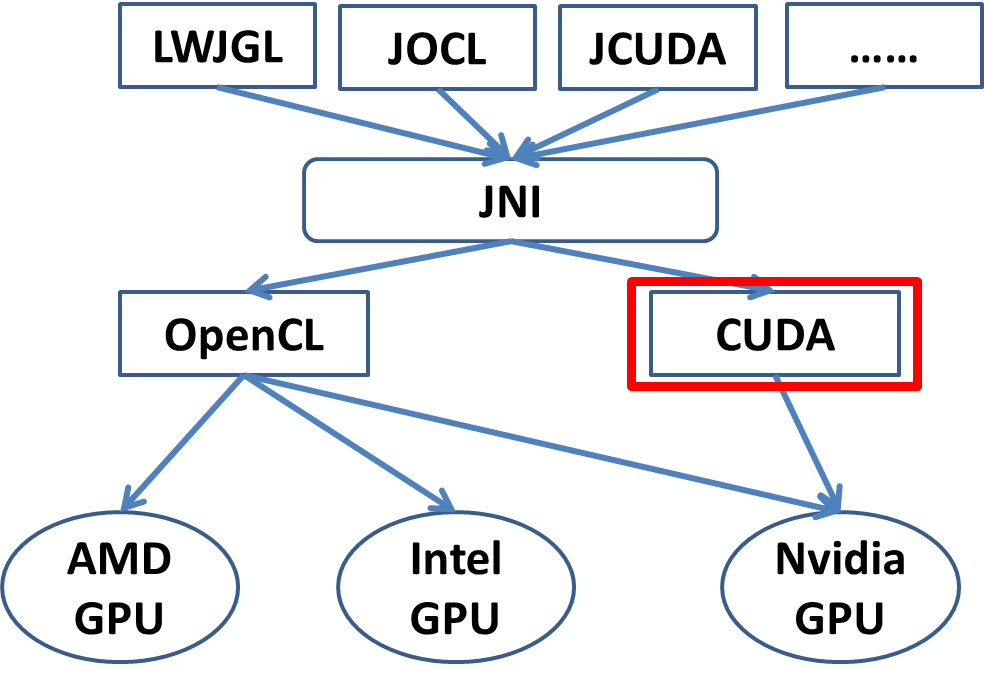
图2 GPU编程库

相关文章推荐
- (CUDA 编程8).CUDA 内存使用 global 二------GPU的革命
- GPU(CUDA)学习日记(三)------ CUDA基本架构介绍以及编程入门!~~
- 提高多GPU编程与执行效率 CUDA 4.0初探
- GPU-cuda编程葵花宝典
- GPU编程——CUDA在VS2010下环境搭建
- 《GPU高性能编程 CUDA实战》(CUDA By Example)读书笔记
- GPU编程之CUDA(一)——入门知识
- cuda编程实践-2
- CUDA编程实践-3
- GPU 编程入门到精通(一)之 CUDA 环境安装
- CUDA by Example 第三章 部分翻译实践 GPU器件参数提取
- 看cuda初级教程视频笔记(周斌讲的)--CUDA、GPU编程模型
- (CUDA 编程9).CUDA shared memory使用------GPU的革命
- CUDA编程-GPU架构软硬件体系
- GPU编程之CUDA(八)——示例程序运行截图【3_Imaging】
- CUDA 编程1).CUDA 线程执行模型分析(一)招兵 ------ GPU的革命(转)
- GPU编程之CUDA初学名词解释
- CUDA by Example 第三章 部分翻译实践 GPU器件参数提取
- GPU CUDA编程中threadIdx, blockIdx, blockDim, gridDim之间的区别与联系
- GPU(CUDA)学习日记(六)------ vector,动态数组,引用,编程调试经验总结等一些比较琐碎的记录