机器学习项目实战:泰坦尼克号获救预测
2017-03-21 00:16
621 查看
import pandas
titanic = pandas.read_csv("D:\\test\\titanic_train.csv")
#进行简单的统计学分析
print titanic.describe()#std代表方差,Age中存在缺失值PassengerId Survived Pclass Age SibSp \ count 891.000000 891.000000 891.000000 714.000000 891.000000 mean 446.000000 0.383838 2.308642 29.699118 0.523008 std 257.353842 0.486592 0.836071 14.526497 1.102743 min 1.000000 0.000000 1.000000 0.420000 0.000000 25% 223.500000 0.000000 2.000000 NaN 0.000000 50% 446.000000 0.000000 3.000000 NaN 0.000000 75% 668.500000 1.000000 3.000000 NaN 1.000000 max 891.000000 1.000000 3.000000 80.000000 8.000000 Parch Fare count 891.000000 891.000000 mean 0.381594 32.204208 std 0.806057 49.693429 min 0.000000 0.000000 25% 0.000000 7.910400 50% 0.000000 14.454200 75% 0.000000 31.000000 max 6.000000 512.329200 C:\Users\qiujiahao\Anaconda2\lib\site-packages\numpy\lib\function_base.py:3834: RuntimeWarning: Invalid value encountered in percentile RuntimeWarning)
#以下操作为对数据进行预处理 #算法大多是矩阵运算,不能存在缺失值,用均值来填充缺失值 titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median()) print titanic.describe()#std代表方差,Age中存在缺失值
PassengerId Survived Pclass Age SibSp \ count 891.000000 891.000000 891.000000 891.000000 891.000000 mean 446.000000 0.383838 2.308642 29.361582 0.523008 std 257.353842 0.486592 0.836071 13.019697 1.102743 min 1.000000 0.000000 1.000000 0.420000 0.000000 25% 223.500000 0.000000 2.000000 22.000000 0.000000 50% 446.000000 0.000000 3.000000 28.000000 0.000000 75% 668.500000 1.000000 3.000000 35.000000 1.000000 max 891.000000 1.000000 3.000000 80.000000 8.000000 Parch Fare count 891.000000 891.000000 mean 0.381594 32.204208 std 0.806057 49.693429 min 0.000000 0.000000 25% 0.000000 7.910400 50% 0.000000 14.454200 75% 0.000000 31.000000 max 6.000000 512.329200
#sex是字符串,无法进行计算,将它转成数字,用0代表man,1代表female print titanic["Sex"].unique() titanic.loc[titanic["Sex"]=="male","Sex"] = 0 titanic.loc[titanic["Sex"]=="female","Sex"] = 1
['male' 'female']
#登船的地点也是字符串,需要变换成数字,并填充缺失值
print titanic["Embarked"].unique()
titanic["Embarked"] = titanic["Embarked"].fillna('S')
#loc通过索引获取数据
titanic.loc[titanic["Embarked"]=="S","Embarked"] = 0
titanic.loc[titanic["Embarked"]=="C","Embarked"] = 1
titanic.loc[titanic["Embarked"]=="Q","Embarked"] = 2['S' 'C' 'Q' nan]
#使用回归算法(二分类)进行预测 #线性回归 from sklearn.linear_model import LinearRegression #交叉验证:将训练数据集分成3份,对这三份进行交叉验证,比如使用1,2样本测试,3号样本验证 #对最后得到得数据取平均值 from sklearn.cross_validation import KFold #选中一些特征 predictors = ["Pclass","Sex","Age","SibSp","Parch","Fare","Embarked"] alg = LinearRegression() #n_folds代表将数据切分成3份,存在3层的交叉验证,titanic.shape[0]代表样本个数 kf = KFold(titanic.shape[0],n_folds=3,random_state=1) predictions = [] for train,test in kf: #iloc通过行号获取数据 train_predictors = titanic[predictors].iloc[train,:] #获取对应的label值 train_target = titanic["Survived"].iloc[train] #进行训练 alg.fit(train_predictors,train_target) #进行预测 test_predictors = alg.predict(titanic[predictors].iloc[test,:]) #将结果加入到list中 predictions.append(test_predictors)
import numpy as np predictions = np.concatenate(predictions,axis=0) #将0到1之间的区间值,变成具体的是否被获救,1代表被获救 predictions[predictions>.5] = 1 predictions[predictions<=.5]= 0 accuracy = sum(predictions[predictions == titanic["Survived"]])/len(predictions) print accuracy
0.783389450056 C:\Users\qiujiahao\Anaconda2\lib\site-packages\ipykernel\__main__.py:7: FutureWarning: in the future, boolean array-likes will be handled as a boolean array index
#使用逻辑回归,它虽然是回归算法,但是一般都用来分类 from sklearn import cross_validation from sklearn.linear_model import LogisticRegression alg = LogisticRegression(random_state=1) scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic["Survived"],cv=3) #注意,逻辑回归和线性回归得到的结果类型不一样,逻辑回归是概率值,线性回归是[0,1]区间的数值 print (scores.mean())
0.787878787879
#从以上结果来看,线性回归和逻辑回归并没有得到很高的准确率,接下来使用随机森林进行分析 #随机森林 #1.样本是随机的,有放回的取样 2.特征的选择也是随机的,防止过拟合 3.多颗决策树,取平均值 from sklearn import cross_validation from sklearn.ensemble import RandomForestClassifier #选中一些特征 predictors = ["Pclass","Sex","Age","SibSp","Parch","Fare","Embarked"] #random_state=1表示此处代码多运行几次得到的随机值都是一样的,如果不设置,两次执行的随机值是不一样的 #n_estimators指定有多少颗决策树,树的分裂的条件是:min_samples_split代表样本不停的分裂,某一个节点上的样本如果只有2个了 #就不再继续分裂了,min_samples_leaf是控制叶子节点的最小个数 alg = RandomForestClassifier(random_state=1,n_estimators=10,min_samples_split=2,min_samples_leaf=1) #进行交叉验证 kf = cross_validation.KFold(titanic.shape[0],n_folds=3,random_state=1) scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic["Survived"],cv=kf) print (scores.mean())
0.785634118967
#决策树为10颗的时候效果仍然不好,将决策树数量调整到50颗,并且放松以下条件,使每颗树可以更浅一些 alg = RandomForestClassifier(random_state=1,n_estimators=50,min_samples_split=4,min_samples_leaf=2) #进行交叉验证 kf = cross_validation.KFold(titanic.shape[0],n_folds=3,random_state=1) scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic["Survived"],cv=kf) #我们会发现准确度有了近一步的提高 print (scores.mean())
0.81593714927
#特征提取是数据挖掘里很总要的一部分 #以上使用的特征都是数据里已经有的了,在真实的数据挖掘里我们常常没有合适的特征,需要我们自己取提取 #自己生成一个特征,家庭成员的大小:兄弟姐妹+老人孩子 titanic["FamilySize"] = titanic["SibSp"] + titanic["Parch"] #名字的长度(据说国外的富裕的家庭都喜欢取很长的名字) titanic["NameLength"] = titanic["Name"].apply(lambda x:len(x))
import re
def get_title(name):
#此处是正则表达式:(+)代表匹配一个或者多个,\代表转义,总的来说就是匹配带点号的名称并且至少有一个字母开始
title_search = re.search('([A-Za-z]+)\.',name)
if title_search:
#返回匹配到的元组,group(1)代表返回匹配到的第一个()里的内容
return title_search.group(1)
return ""
titles = titanic["Name"].apply(get_title)
print (pandas.value_counts(titles))
print "......................."
#国外不同阶层的人都有不同的称呼
title_mapping = {"Mr":1,"Miss":2,"Mrs":3,"Master":4,"Dr":5,"Rev":6,"Major":7,"Col":7,"Mlle":8,"Mme":8,"Don":9,
"Lady":10,"Countess":10,"Jonkheer":10,"Sir":9,"Capt":7,"Ms":2}
for k,v in title_mapping.items():
#将不同的称呼替换成机器可以计算的数字
titles[titles==k]=v
print (pandas.value_counts(titles))
print "......................."
titanic["Title"] = titles
print titanic["Title"]Mr 517 Miss 182 Mrs 125 Master 40 Dr 7 Rev 6 Col 2 Major 2 Mlle 2 Countess 1 Ms 1 Lady 1 Jonkheer 1 Don 1 Mme 1 Capt 1 Sir 1 Name: Name, dtype: int64 ....................... 1 517 2 183 3 125 4 40 5 7 6 6 7 5 10 3 8 3 9 2 Name: Name, dtype: int64 ....................... 0 1 1 3 2 2 3 3 4 1 5 1 6 1 7 4 8 3 9 3 10 2 11 2 12 1 13 1 14 2 15 3 16 4 17 1 18 3 19 3 20 1 21 1 22 2 23 1 24 2 25 3 26 1 27 1 28 2 29 1 .. 861 1 862 3 863 2 864 1 865 3 866 2 867 1 868 1 869 4 870 1 871 3 872 1 873 1 874 3 875 2 876 1 877 1 878 1 879 3 880 3 881 1 882 2 883 1 884 1 885 3 886 6 887 2 888 2 889 1 890 1 Name: Title, dtype: object
#特征重要性分析 #分析不同特征对最终结果的影响 #例如衡量age列的重要程度时,什么也不干,得到一个错误率error1, #加入一些噪音数据,替换原来的值(注意,此时其他列的数据不变),又得到一个一个错误率error2 #两个错误率的差值可以体现这一个特征的重要性 import numpy as np from sklearn.feature_selection import SelectKBest,f_classif import matplotlib.pyplot as plt #选中一些特征 predictors = ["Pclass","Sex","Age","SibSp","Parch","Fare","Embarked","FamilySize","Title","NameLength"] #选择特性 seletor = SelectKBest(f_classif,k=5) seletor.fit(titanic[predictors],titanic["Survived"]) scores = -np.log10(seletor.pvalues_) #显示不同特征的重要程度 plt.bar(range(len(predictors)),scores) plt.xticks(range(len(predictors)),predictors,rotation="vertical") plt.show()
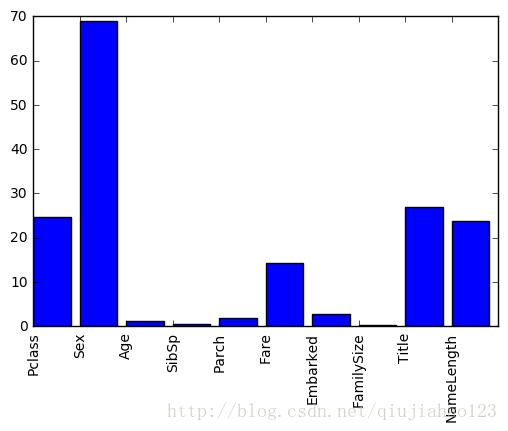
#通过以上特征的重要性分析,选择出4个最重要的特性,重新进行随机森林的算法 predictors = ["Pclass","Sex","Fare","Title"] alg = RandomForestClassifier(random_state=1,n_estimators=50,min_samples_split=4,min_samples_leaf=2) #进行交叉验证 kf = cross_validation.KFold(titanic.shape[0],n_folds=3,random_state=1) scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic["Survived"],cv=kf) #目前的结果是没有得到提高,本处的目的是为了练习在随机森林中的特征选择,它对于实际的数据挖掘具有重要意义 print (scores.mean())
0.814814814815
#在竞赛中常用的耍赖的办法:集成多种算法,取最后每种算法的平均值,来减少过拟合 from sklearn.ensemble import GradientBoostingClassifier import numpy as np #GradientBoostingClassifier也是一种随机森林的算法,可以集成多个弱分类器,然后变成强分类器 algorithms = [ [GradientBoostingClassifier(random_state=1,n_estimators=25,max_depth=3),["Pclass","Sex","Age","Fare","Embarked","FamilySize","Title"]], [LogisticRegression(random_state=1),["Pclass","Sex","Fare","FamilySize","Title","Age","Embarked"]] ] kf = KFold(titanic.shape[0],n_folds=3,random_state=1) predictions = [] for train,test in kf: train_target = titanic["Survived"].iloc[train] full_test_predictions = [] for alg,predictors in algorithms: alg.fit(titanic[predictors].iloc[train,:],train_target) test_predictions = alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:,1] full_test_predictions.append(test_predictions) test_predictions = (full_test_predictions[0] + full_test_predictions[1])/2 test_predictions[test_predictions<=.5]=0 test_predictions[test_predictions>.5] =1 predictions.append(test_predictions) predictions = np.concatenate(predictions,axis=0) #发现准确率提高了一个百分点 accuracy = sum(predictions[predictions == titanic["Survived"]])/len(predictions) print accuracy
0.821548821549 C:\Users\qiujiahao\Anaconda2\lib\site-packages\ipykernel\__main__.py:27: FutureWarning: in the future, boolean array-likes will be handled as a boolean array index

相关文章推荐
- 机器学习项目实战:泰坦尼克号获救预測
- 数据科学工程师面试宝典系列之二---Python机器学习kaggle案例:泰坦尼克号船员获救预测
- 机器学习(1)-项目 0: 预测泰坦尼克号乘客生还率
- 数据科学工程师面试宝典系列之二---Python机器学习kaggle案例:泰坦尼克号船员获救预测
- 机器学习中的特征选择——决策树模型预测泰坦尼克号乘客获救实例
- 【机器学习实战】Machine Learning in Action 代码 视频 项目案例
- 机器学习项目实战之贷款申请最大利润
- 机器学习-实战-入门-linearSVC和SVC,身高体重与胖瘦关系的分类与预测
- 【机器学习】Random Forest(随机森林)入门和实战(一)先写个项目
- 机器学习实战 - 读书笔记(08) - 预测数值型数据:回归
- 【机器学习实战三:Logistic回归之点的二分类和预测病马的死亡率】
- Python开源机器学习项目实战
- 机器学习实战——预测数值型数据:回归
- 机器学习 - 泰坦尼克号预测生还
- 机器学习项目开发实战,应用
- 利用随机森林,xgboost,logistic回归,预测泰坦尼克号上面的乘客的获救概率
- 项目二:使用机器学习(SVM)进行基因预测
- 机器学习实战之KNN(交友网站网友预测)
- 机器学习--第八讲--项目:预测桌游评论
- 【机器学习实战】美国波斯顿房价预测