【机器学习】感知机的一点理解
2017-03-20 16:17
176 查看
本文是对之前有关感知机的部分进行了总结。
首先,机器学习的初衷是想寻找一种类似人的大脑的算法来处理各种数据。其中,应用最多也最广的就是物体的识别。我们人在进行物体识别的时候,大脑工作机制可以大致分为三个阶段:
1.感官器官得到物理信息,如颜色、形状等;
2.大脑对信号进行模式学习;
3.输出动作。
随着生物神经科学的发展,人们逐渐了解到了大脑的构造以及信号的传输是由神经细胞(神经元)来完成的,它通过一些化学物质来达到电信号的传递,并构成了整个网络。所以人们仿照神经细胞的结构发明了神经元模型。即1957年,Rosenblatt提出的感知机模型 。
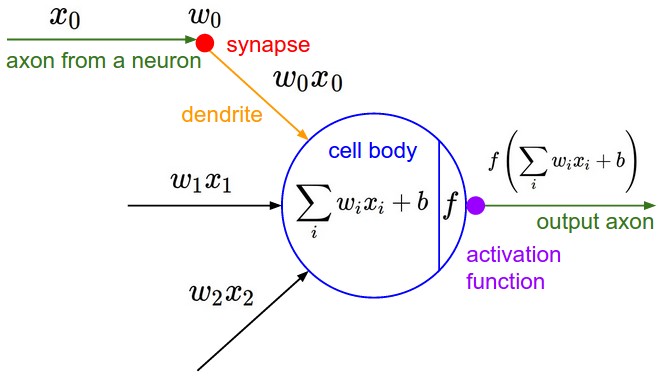
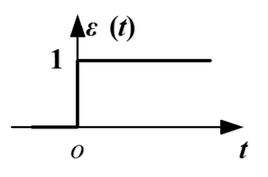
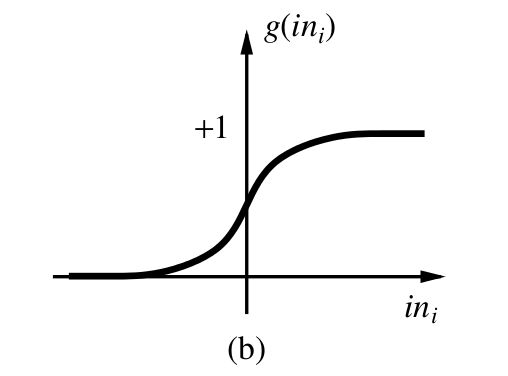
简单解释一下,左边xi是输入值,对应的wi是权值,可以看做神经元对不同信号敏感程度不同。中间左边的式子是说输入的形式是加权和。b是偏置,可以看做神经元内部的信号。f是激活函数,可以理解为阈值化,即高于一定水平的信号神经元激活,低于的话抑制。激活函数一般有阶梯函数和sigmod函数,如下:
下面我们具体看一下感知机如何工作。
假设我有一个问题让机器去完成,就是将苹果和香蕉两类水果分开。再假设我只能得到水果的两种特征:颜色和形状。
列表如下:
我们使用感知机来试着完成它。
2.输出1代表苹果,-1代表香蕉。
3.感知机模型我们预设为:w1=w2=1,b=0,激活函数采用sign函数。
Sout =f<
4000
/span>(x1×w1+x2×w2+b)=sign(1×1+1×1+0)=1
(2)香蕉,输入-1,-1。
Sout =f(x1×w1+x2×w2+b)=sign((-1)×1+(-1)×1+0)=-1
结果正确,无疑这个模型可以完成此任务。
但是,另外一个人在使用的时候就没有这么好运气了。
他在使用的时候设置模型为:w1=1,w2=-1,b=0,激活函数采用sign函数。
Sout = f(x1×w1+x2×w2+b)=sign(1×1-1×1+0)=-1
(2)香蕉,输入-1,-1 。
Sout = f(x1×w1+x2×w2+b)=sign((-1)×1+(-1)×(-1)+0)=-1
这一次什么也分不出来了。接着,他就想退而求其次。如果刚开始错了,那么我们告诉它这个错了,应该是什么,以后它就都分对了,那也是极好的。
首先对模型进行分析:
前面提到的感知机模型可以用这个式子来表示,
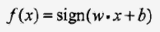
整个模型是一个线性分类模型,属于判别式模型。sign是符号函数,大于零为+1,小于零为-1。
那这个式子的几何意义为输入向量构成的空间中的一个超平面,正负样本在平面的两侧。超平面S方程如下:

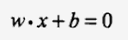
现在我们对这个问题进行建模,首先我们要找到的平面应该具有这样的性质:所有误分类点到平面的距离最短。也就是说误分类点离分类面越近越好,因为对于一个误分类点,真正的分类面应该在它附近。
空间R中一点x0到超平面S的距离为:
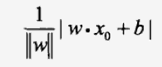
而对于误分类点,有:
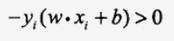
因为y是输出,它为+1或-1,显然误分类点的总输入和输出异号。
因此,误分类点到超平面S的距离为(去掉绝对值):
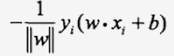
所有误分类点的集合记为M,则误分类点到S的总距离为:
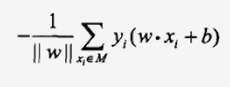
则上述求分类面的问题转化为最优化问题:
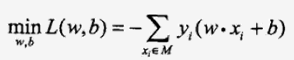
这个无约束的连续函数的最优化问题可以采用最速下降法求解,其核心就是参数的更新公式,即新参数=旧参数+步长*下降方向,这里下降方向就是目标函数的梯度,因为梯度是方向导数里最大的。求解如下:
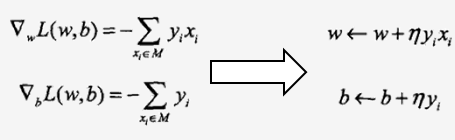
这样我们就得到了权值更新公式,η为步长,即学习率。
接着,我们对之前错误的分类进行更新:
w1new = w1old+1×x1=
1+1×1 = 2
w2new = w2old+1×x2=
-1+1×1 = 0
bnew = bold+
1 = 1
再次进行鉴别:
(1)苹果,输入1,1。
Sout = f(x1×w1+x2×w2+b)=sign(1×2+1×0+1)=1
(2)香蕉,输入-1,-1 。
Sout = f(x1×w1+x2×w2+b)=sign((-1)×2+(-1)×0+1)=-1
全部分类正确!至此,我们便有了一个较为实用的方法,我们可以用有限的数据进行学习,然后对更多的数据进行分类。
下面的编程求解分类面的实验:


左边是初始的输入和初始分类面,右边是经过32次迭代以后的正确分类面。
下面是我生成的中间过程的动画效果。

我们可以得到下表:
可以看到,实际上这个感知机模型完成了一个逻辑或。
参考资料:
[1] 统计学习方法,李航
[2] 神经网络与深度学习,吴岸城
首先,机器学习的初衷是想寻找一种类似人的大脑的算法来处理各种数据。其中,应用最多也最广的就是物体的识别。我们人在进行物体识别的时候,大脑工作机制可以大致分为三个阶段:
1.感官器官得到物理信息,如颜色、形状等;
2.大脑对信号进行模式学习;
3.输出动作。
随着生物神经科学的发展,人们逐渐了解到了大脑的构造以及信号的传输是由神经细胞(神经元)来完成的,它通过一些化学物质来达到电信号的传递,并构成了整个网络。所以人们仿照神经细胞的结构发明了神经元模型。即1957年,Rosenblatt提出的感知机模型 。
感知机模型
简单解释一下,左边xi是输入值,对应的wi是权值,可以看做神经元对不同信号敏感程度不同。中间左边的式子是说输入的形式是加权和。b是偏置,可以看做神经元内部的信号。f是激活函数,可以理解为阈值化,即高于一定水平的信号神经元激活,低于的话抑制。激活函数一般有阶梯函数和sigmod函数,如下:
下面我们具体看一下感知机如何工作。
假设我有一个问题让机器去完成,就是将苹果和香蕉两类水果分开。再假设我只能得到水果的两种特征:颜色和形状。
列表如下:
| 种类 | 颜色 | 形状 |
| 苹果 | 1(红色) | 1(圆形) |
| 香蕉 | -1(黄色) | -1(条形) |
问题分析:
1.输入两个x1(颜色),x2(形状)。2.输出1代表苹果,-1代表香蕉。
3.感知机模型我们预设为:w1=w2=1,b=0,激活函数采用sign函数。
鉴别:
(1)苹果,输入1,1。Sout =f<
4000
/span>(x1×w1+x2×w2+b)=sign(1×1+1×1+0)=1
(2)香蕉,输入-1,-1。
Sout =f(x1×w1+x2×w2+b)=sign((-1)×1+(-1)×1+0)=-1
结果正确,无疑这个模型可以完成此任务。
但是,另外一个人在使用的时候就没有这么好运气了。
他在使用的时候设置模型为:w1=1,w2=-1,b=0,激活函数采用sign函数。
第二次鉴别:
(1)苹果,输入1,1。Sout = f(x1×w1+x2×w2+b)=sign(1×1-1×1+0)=-1
(2)香蕉,输入-1,-1 。
Sout = f(x1×w1+x2×w2+b)=sign((-1)×1+(-1)×(-1)+0)=-1
这一次什么也分不出来了。接着,他就想退而求其次。如果刚开始错了,那么我们告诉它这个错了,应该是什么,以后它就都分对了,那也是极好的。
参数学习
这里我们打算采用数学的方法来寻求矫正错误的方法。首先对模型进行分析:
前面提到的感知机模型可以用这个式子来表示,
整个模型是一个线性分类模型,属于判别式模型。sign是符号函数,大于零为+1,小于零为-1。
那这个式子的几何意义为输入向量构成的空间中的一个超平面,正负样本在平面的两侧。超平面S方程如下:
现在我们对这个问题进行建模,首先我们要找到的平面应该具有这样的性质:所有误分类点到平面的距离最短。也就是说误分类点离分类面越近越好,因为对于一个误分类点,真正的分类面应该在它附近。
空间R中一点x0到超平面S的距离为:
而对于误分类点,有:
因为y是输出,它为+1或-1,显然误分类点的总输入和输出异号。
因此,误分类点到超平面S的距离为(去掉绝对值):
所有误分类点的集合记为M,则误分类点到S的总距离为:
则上述求分类面的问题转化为最优化问题:
这个无约束的连续函数的最优化问题可以采用最速下降法求解,其核心就是参数的更新公式,即新参数=旧参数+步长*下降方向,这里下降方向就是目标函数的梯度,因为梯度是方向导数里最大的。求解如下:
这样我们就得到了权值更新公式,η为步长,即学习率。
接着,我们对之前错误的分类进行更新:
w1new = w1old+1×x1=
1+1×1 = 2
w2new = w2old+1×x2=
-1+1×1 = 0
bnew = bold+
1 = 1
再次进行鉴别:
(1)苹果,输入1,1。
Sout = f(x1×w1+x2×w2+b)=sign(1×2+1×0+1)=1
(2)香蕉,输入-1,-1 。
Sout = f(x1×w1+x2×w2+b)=sign((-1)×2+(-1)×0+1)=-1
全部分类正确!至此,我们便有了一个较为实用的方法,我们可以用有限的数据进行学习,然后对更多的数据进行分类。
下面的编程求解分类面的实验:
左边是初始的输入和初始分类面,右边是经过32次迭代以后的正确分类面。
下面是我生成的中间过程的动画效果。
进一步分析
如果我们将sign函数换成step函数,即阶跃函数。那么我们的例子中的感知机为step(x1+x2),w1=w2=1,b=0.我们可以得到下表:
| x1 | x2 | out |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
| x1 | x2 | out |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
[1] 统计学习方法,李航
[2] 神经网络与深度学习,吴岸城

相关文章推荐
- 【机器学习】感知机的一点理解
- 【机器学习】感知机的一点理解
- 【机器学习】感知机的一点理解
- 【机器学习】感知机的一点理解
- 【机器学习】感知机的一点理解
- 【机器学习】感知机的一点理解
- 【机器学习】感知机的一点理解
- 【机器学习】感知机的一点理解
- 【机器学习】感知机的一点理解
- 【机器学习】感知机的一点理解
- 机器学习之条件随机场CRF一点理解
- 机器学习——15分钟透彻理解感知机
- 【机器学习】多层感知机的理解
- 【机器学习】多层感知机的理解
- 【机器学习】多层感知机的理解
- 【机器学习】多层感知机的理解
- 【机器学习】多层感知机的理解
- 对机器学习的一点理解
- 机器学习之感知机学习笔记第一篇:求输入空间R中任意一点X0到超平面S的距离
- 机器学习入门 一、理解机器学习+简单感知机(JAVA实现)