《Java高并发程序设计》学习 --3.3 JDK的并发容器
2017-03-17 20:14
645 查看
1)并发集合简介
JDK提供的并发容器大部分在java.util.concurrent包中。如下所示:
ConcurrentHashMap : 一个高效的线程安全的HashMap。
CopyOnWriteArrayList : 在读多写少的场景中,性能非常好,远远高于vector。
ConcurrentLinkedQueue : 高效并发队列,使用链表实现,可以看成线程安全的LinkedList。
BlockingQueue : 一个接口,JDK内部通过链表,数组等方式实现了这个接口,表示阻塞队列,非常适合用作数据共享通道。
ConcurrentSkipListMap : 跳表的实现,这是一个Map,使用跳表数据结构进行快速查找。
2)线程安全的HashMap
如果需要一个线程安全的HashMap,一种可行的方法是使用Collections.synchronizedMap()方法包装HashMap。如下代码,产生的HashMap就是线程安全的:
public static Map m = Collections.synchronizedMap(new HashMap());
Collections.synchronizedMap()会生成一个名为SynchronizedMap的Map。它使用委托,将自己所有Map相关的功能交给传入的HashMap实现,而自己则主要负责保证线程安全。
具体参考下面的实现,首先SynchronizedMap内包装
其他所有相关的Map操作都会使用这个mutex进行同步。从而实现线程安全。
这个包装的Map可以满足线程安全的要求。但是,它在多线程环境中的性能表现并不算太好。无论是对Map的读取或者写入,都需要获得mutex的锁,这会导致所有对Map的操作全部进入等待状态,直到mutex锁可用。
一个更加专业的并发HashMap是ConcurrentHashMap。它位于java.util.concurrent包内。它专门为并发进行了性能优化,因此,更加适合多线程的场合。
3)有关List的线程安全
在Java中,ArrayList和Vector都是使用数组作为其内部实现。两者最大的不同在于Vector是线程安全的,而ArrayList不是。此外,LinkedList使用链表的数据结构实现了List。但LinkedList并不是线程安全的,不过参考前面对HashMap的包装,在这里我们也可以使用Collections.synchronizedList()方法来包装任意List。如下所示:
public static List<String> l = Collections.synchronizedList(new LinkedList<String>());
此时生成的List对象就是线程安全的。
4)高效读写的队列:深度剖析ConcurrentLinkedQueue
在JDK中提供了一个ConcurrentLinkedQueue类用来实现高并发的队列。
作为一个链表,需要定义有关链表内的节点,在ConcurrentLinkedQueue中,定义的节点Node核心如下:
private static class Node<E> {
volatile E item;
volatile Node<E> next;
}
其中item是用来表示目标元素的,字段next表示当前Node的下一个元素。
对Node进行操作时,使用了CAS操作。
方法casItem()表示设置当前Node的item值。它需要两个参数,第一个参数为期望值,第二个参数为设置目标值。当当前值等于cmp期望值时,就会将目标设置为val。同样,casNext()方法也是类似的,但它是用来设置next字段。
如下图所示,显示了插入时,tail的更新情况,可以看到tail的更新会产生滞后,并且每次更新会跳跃两个元素。
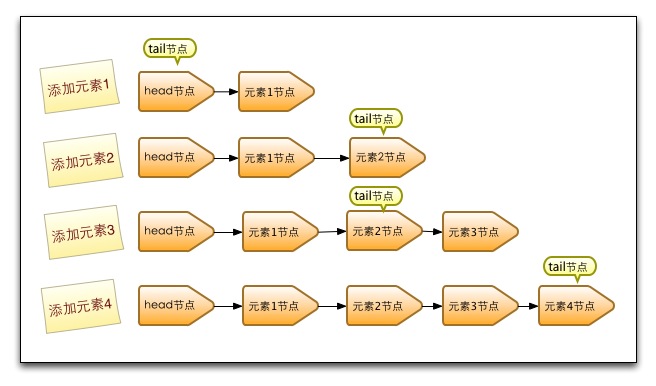
第一步添加元素1。队列更新head节点的next节点为元素1节点。又因为tail节点默认情况下等于head节点,所以它们的next节点都指向元素1节点。
第二步添加元素2。队列首先设置元素1节点的next节点为元素2节点,然后更新tail节点指向元素2节点。
第三步添加元素3,设置tail节点的next节点为元素3节点。
第四步添加元素4,设置元素3的next节点为元素4节点,然后将tail节点指向元素4节点。
通过debug入队过程并观察head节点和tail节点的变化,发现入队主要做两件事情,第一是将入队节点设置成当前队列尾节点的下一个节点。第二是更新tail节点,如果tail节点的next节点不为空,则将入队节点设置成tail节点,如果tail节点的next节点为空,则将入队节点设置成tail的next节点,所以tail节点不总是尾节点,理解这一点对于我们研究源码会非常有帮助。
下面为ConcurrentLinkedQueue中向队列中添加元素的offer()方法。
首先值得注意的是,这个方法没有任何锁操作。线程安全完全由CAS操作和队列的算法来保证。整个方法的核心是for循环,这个循环没有出口,直到尝试成功,这也符合CAS操作的流程。当第一次加入元素时,由于队列为空,因此p.next为null。流程进入第8行。并将p的next节点赋值为newNode,也就是将新的元素加入到队列中。此时,p==t成立,因此不会执行第12行的代码更新tail末尾。如果casNext()成功,程序直接返回,如果失败,则再进行一次循环尝试,直到成功。因此增加一个元素后,tail并不会被更新。
当程序试图增加第2个元素时,由于t还在head的位置上,因此p.next指向实际的第一个元素,因此第6行的q!=null,这表示q不是最后的节点。由于往队列中增加元素需要最后一个节点的位置,因此,循环开始查找最后一个节点。于是,程序会进入第23行,获得最后一个节点。此时,p实际上是指向链表中的第一个元素,而它的next为null,故在第2个循环时,进入第8行。p更新自己的next,让它指向新加入的节点。如果成功,由于此时p!=t成功,则会更新t所在位置,将t移动到链表最后。
在第17行,处理了p==q的情况。这种情况是由于遇到了哨兵(sentinel)节点导致的。所谓哨兵节点,就是next指向自己的节点。这种节点在队列中的存在价值不大,主要表示要删除的节点,或者空节点。当遇到哨兵节点时,由于无法通过next取得后续的节点,因此很可能直接返回head,期望通过从链表头部开始遍历,进一步查找到链表末尾。但一旦发生在执行过程中,tail被其他线程修改的情况,则进行一次“打赌”,使用新的tail作为链表末尾(这样就避免了重新查找tail的开销)。
下面我们来看一下哨兵节点是如何产生的。弹出队列内的元素。其执行过程如下:
由于队列中只有一个元素,根据前文的描述,此时tail并没有更新,而是指向和head相同的位置。而此时,head本身的item域为null,其next为列表第一个元素。故在第一个循环中,代码直接进入第18行,将p赋值为q,而q就是p.next,也是当前列表中的第一个元素。接着,在第2轮循环中,p.item显然不为null,因此,代码应该可以进入第7行(如果CAS操作成功)。进入第7行,也意味着p的item域被设置为null(因为这是弹出元素,需要删除)。同时,此时p和h是不相等的(因为p已经指向原有的第一个元素了)。故执行了第8行的updateHead()操作,其实现如下:
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
h.lazySetNext(h);
}
可以看到,在updateHead中,就将p作为新的链表头部(通过casHead()实现),而原有的head就被设置为哨兵(通过lazySetNext()实现)。
这样一个哨兵节点就产生了,而由于此时原有的head头部和tail实际上是同一个元素。因此,再次offer()插入元素时,就会遇到这个tail,也就是哨兵。这就是offer()代码中,第17行判断的意义。
5)不变模式下的CopyOnWriteArrayList
为了将读取的性能发挥到极致,JDK中提供了CopyOnWriteArrayList类。对它来说,读取是完全不用加锁的,并且写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。当这个List需要修改时,并不修改原有的内容,而是对原有的数据进行一次复制,将修改的内容写入副本。写完之后,再将修改完的副本替换原来的数据。这样就可以保证写操作不会影响读了。
下面的代码展示了有关读取的实现:
读取代码没有任何同步控制和锁操作,因为内部数组array不会发生修改,只会被另外一个array替代,因此可以保证数据安全。
写操作如下:
首先,写操作使用锁,这个锁仅限于控制写-写的情况。其重点在于第7行代码,进行了内部元素的完整复制。因此,会生成一个新的数组newElements。然后,将新的元素加入newElements。接着,在第9行,使用新的数组替换老的数组,修改就完成了。整个过程不会影响读取,并且修改完后,读取线程可以立即“察觉”到这个修改(因为array变量是volatile类型)。
6)数据共享通道:BlockingQueue
我们使用BlockingQueue进行多个线程间的数据共享。主要介绍ArrayBlockingQueue和LinkedBlockingQueue。ArrayBlockingQueue是基于数组实现的,而LinkedBlockingQueue基于链表。因此,ArrayBlockingQueue更适合做有界对垒,因为队列中可容纳的最大元素需要在队列创建时指定。而LinkedBlockingQueue适合做无界队列,或者那些边界值非常大的队列。
BlockingQueue让服务线程在队列为空时,进行等待,当有新的消息进入队列后,自动将线程唤醒。以ArrayBlockingQueue为例。
ArrayBlockingQueue的内部元素都放置在一个对象数组中:
final Object[] items;
向队列中压入元素可以使用offer()方法和put()方法。对于offer()方法,如果当前队列已经满了,它就会立即返回false。如果没有满,则执行正常的入队操作。我们需要关注的是put()方法。put()方法也是将元素压入队列末尾。如果队列满了,它会一直等待,直到队列中有空闲的位置。
从队列中弹出元素可以使用poll()方法和take()方法。它们都是从队列的头部获得一个元素。不同之处在于:如果队列为空poll()方法直接返回null,而take()方法会等待,直到队列内有可用元素。
因此,put()方法和take()方法才是体现Blocking的关键。为了做好等待和
c1ba
通知两件事,在ArrayBlockingQueue内部定义了一下一些字段:
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
当执行take()操作时,如果队列为空,则让当前线程等待在notEmpty上。新元素入队时,则进行一次notEmpty上的通知。
下面的代码显示了take()的过程:
第6行代码,就要求当前线程进行等待。当队列中有新元素时,线程会得到一个通知。下面是元素入队时的一段代码:
注意第5行代码,当新元素进入队列后,需要通知等待在notEmpty上的线程,让它们继续工作。
同理,对于put()操作也是一样,当队列满时,需要让压入线程等待,如下面第7行。
当有元素从队列中被挪走,队列出现空位时,也需要通知等待入队的线程:
上述代码表示从队列中拿走一个元素。当有空闲位置时,在第7行,通知等待入队的线程。
7)随机数据结构:跳表(SkipList)
跳表是一种可以用来快速查找的数据结构,有点类似平衡树。它们都可以对元素进行快速的查找。但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整。而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。
跳表的另外一个特点是随机算法。跳表的本质是同时维护了多个链表,并且链表是分层的。如图所示。
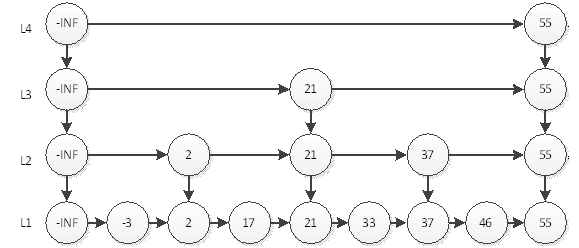
最底层的链表维护了跳表内所有的元素,每上面一层链表都是下面一层的子集,一个元素插入哪些层是完全随机的。
跳表内的所有链表的元素都是排序的。查找时,可以从顶级链表开始查找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续查找。也就是说在查找过程中,搜索是跳跃式的。
因此,跳表是一种使用空间换时间的算法。
使用跳表实现Map和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,会得到一个有序的结果。
实现这一数据结构的类是ConcurrentSkipListMap。下面展示了跳表的简单实用:
和HashMap不同,对跳表的遍历输出是有序的。
跳表的内部实现有几个关键的数据结构组成。首先是Node,一个Node就是表示一个节点,里面含有两个重要的元素key和value(就是Map的key和value)。每个Node还会指向下一个Node,因此还有一个元素next。
对Node的所有操作,使用的CAS方法:
方法casValue()用来设置value的值,相对的casNext()用来设置next的字段。
另外一个重要的数据结构是Index,表示索引。它内部包装了Node,同时增加了向下的引用和向右的引用。
整个跳表是根据Index进行全网的组织的。
此外,对于每一层的表头,还需要记录当前处于哪一层。为此,还需要一个称为HeadIndex的数据结构,表示链表头部的第一个Index。它继承自Index。
注:本篇博客内容摘自《Java高并发程序设计》
JDK提供的并发容器大部分在java.util.concurrent包中。如下所示:
ConcurrentHashMap : 一个高效的线程安全的HashMap。
CopyOnWriteArrayList : 在读多写少的场景中,性能非常好,远远高于vector。
ConcurrentLinkedQueue : 高效并发队列,使用链表实现,可以看成线程安全的LinkedList。
BlockingQueue : 一个接口,JDK内部通过链表,数组等方式实现了这个接口,表示阻塞队列,非常适合用作数据共享通道。
ConcurrentSkipListMap : 跳表的实现,这是一个Map,使用跳表数据结构进行快速查找。
2)线程安全的HashMap
如果需要一个线程安全的HashMap,一种可行的方法是使用Collections.synchronizedMap()方法包装HashMap。如下代码,产生的HashMap就是线程安全的:
public static Map m = Collections.synchronizedMap(new HashMap());
Collections.synchronizedMap()会生成一个名为SynchronizedMap的Map。它使用委托,将自己所有Map相关的功能交给传入的HashMap实现,而自己则主要负责保证线程安全。
具体参考下面的实现,首先SynchronizedMap内包装
private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable {
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
......
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value
4000
);}
}
......
}其他所有相关的Map操作都会使用这个mutex进行同步。从而实现线程安全。
这个包装的Map可以满足线程安全的要求。但是,它在多线程环境中的性能表现并不算太好。无论是对Map的读取或者写入,都需要获得mutex的锁,这会导致所有对Map的操作全部进入等待状态,直到mutex锁可用。
一个更加专业的并发HashMap是ConcurrentHashMap。它位于java.util.concurrent包内。它专门为并发进行了性能优化,因此,更加适合多线程的场合。
3)有关List的线程安全
在Java中,ArrayList和Vector都是使用数组作为其内部实现。两者最大的不同在于Vector是线程安全的,而ArrayList不是。此外,LinkedList使用链表的数据结构实现了List。但LinkedList并不是线程安全的,不过参考前面对HashMap的包装,在这里我们也可以使用Collections.synchronizedList()方法来包装任意List。如下所示:
public static List<String> l = Collections.synchronizedList(new LinkedList<String>());
此时生成的List对象就是线程安全的。
4)高效读写的队列:深度剖析ConcurrentLinkedQueue
在JDK中提供了一个ConcurrentLinkedQueue类用来实现高并发的队列。
作为一个链表,需要定义有关链表内的节点,在ConcurrentLinkedQueue中,定义的节点Node核心如下:
private static class Node<E> {
volatile E item;
volatile Node<E> next;
}
其中item是用来表示目标元素的,字段next表示当前Node的下一个元素。
对Node进行操作时,使用了CAS操作。
boolean casItem(E cmp,E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val)
}
boolean casNext(Node<E> cmp,Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}方法casItem()表示设置当前Node的item值。它需要两个参数,第一个参数为期望值,第二个参数为设置目标值。当当前值等于cmp期望值时,就会将目标设置为val。同样,casNext()方法也是类似的,但它是用来设置next字段。
如下图所示,显示了插入时,tail的更新情况,可以看到tail的更新会产生滞后,并且每次更新会跳跃两个元素。
第一步添加元素1。队列更新head节点的next节点为元素1节点。又因为tail节点默认情况下等于head节点,所以它们的next节点都指向元素1节点。
第二步添加元素2。队列首先设置元素1节点的next节点为元素2节点,然后更新tail节点指向元素2节点。
第三步添加元素3,设置tail节点的next节点为元素3节点。
第四步添加元素4,设置元素3的next节点为元素4节点,然后将tail节点指向元素4节点。
通过debug入队过程并观察head节点和tail节点的变化,发现入队主要做两件事情,第一是将入队节点设置成当前队列尾节点的下一个节点。第二是更新tail节点,如果tail节点的next节点不为空,则将入队节点设置成tail节点,如果tail节点的next节点为空,则将入队节点设置成tail的next节点,所以tail节点不总是尾节点,理解这一点对于我们研究源码会非常有帮助。
下面为ConcurrentLinkedQueue中向队列中添加元素的offer()方法。
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
//p是最后一个节点
if (p.casNext(null, newNode)) {
//每2次,更新下一个tail
if (p != t)
casTail(t, newNode);
return true;
}
//CAS竞争失败,再次尝试
}
else if (p == q)
//遇到哨兵节点,从head开始遍历
//但如果tail被修改,则使用tail(因为可能被修改正确)
p = (t != (t = tail)) ? t : head;
else
//取下一个节点或者最后一个节点
p = (p != t && t != (t = tail)) ? t : q;
}
}首先值得注意的是,这个方法没有任何锁操作。线程安全完全由CAS操作和队列的算法来保证。整个方法的核心是for循环,这个循环没有出口,直到尝试成功,这也符合CAS操作的流程。当第一次加入元素时,由于队列为空,因此p.next为null。流程进入第8行。并将p的next节点赋值为newNode,也就是将新的元素加入到队列中。此时,p==t成立,因此不会执行第12行的代码更新tail末尾。如果casNext()成功,程序直接返回,如果失败,则再进行一次循环尝试,直到成功。因此增加一个元素后,tail并不会被更新。
当程序试图增加第2个元素时,由于t还在head的位置上,因此p.next指向实际的第一个元素,因此第6行的q!=null,这表示q不是最后的节点。由于往队列中增加元素需要最后一个节点的位置,因此,循环开始查找最后一个节点。于是,程序会进入第23行,获得最后一个节点。此时,p实际上是指向链表中的第一个元素,而它的next为null,故在第2个循环时,进入第8行。p更新自己的next,让它指向新加入的节点。如果成功,由于此时p!=t成功,则会更新t所在位置,将t移动到链表最后。
在第17行,处理了p==q的情况。这种情况是由于遇到了哨兵(sentinel)节点导致的。所谓哨兵节点,就是next指向自己的节点。这种节点在队列中的存在价值不大,主要表示要删除的节点,或者空节点。当遇到哨兵节点时,由于无法通过next取得后续的节点,因此很可能直接返回head,期望通过从链表头部开始遍历,进一步查找到链表末尾。但一旦发生在执行过程中,tail被其他线程修改的情况,则进行一次“打赌”,使用新的tail作为链表末尾(这样就避免了重新查找tail的开销)。
下面我们来看一下哨兵节点是如何产生的。弹出队列内的元素。其执行过程如下:
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null && p.casItem(item, null)) {
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}由于队列中只有一个元素,根据前文的描述,此时tail并没有更新,而是指向和head相同的位置。而此时,head本身的item域为null,其next为列表第一个元素。故在第一个循环中,代码直接进入第18行,将p赋值为q,而q就是p.next,也是当前列表中的第一个元素。接着,在第2轮循环中,p.item显然不为null,因此,代码应该可以进入第7行(如果CAS操作成功)。进入第7行,也意味着p的item域被设置为null(因为这是弹出元素,需要删除)。同时,此时p和h是不相等的(因为p已经指向原有的第一个元素了)。故执行了第8行的updateHead()操作,其实现如下:
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
h.lazySetNext(h);
}
可以看到,在updateHead中,就将p作为新的链表头部(通过casHead()实现),而原有的head就被设置为哨兵(通过lazySetNext()实现)。
这样一个哨兵节点就产生了,而由于此时原有的head头部和tail实际上是同一个元素。因此,再次offer()插入元素时,就会遇到这个tail,也就是哨兵。这就是offer()代码中,第17行判断的意义。
5)不变模式下的CopyOnWriteArrayList
为了将读取的性能发挥到极致,JDK中提供了CopyOnWriteArrayList类。对它来说,读取是完全不用加锁的,并且写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。当这个List需要修改时,并不修改原有的内容,而是对原有的数据进行一次复制,将修改的内容写入副本。写完之后,再将修改完的副本替换原来的数据。这样就可以保证写操作不会影响读了。
下面的代码展示了有关读取的实现:
private volatile transient Object[] array;
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}读取代码没有任何同步控制和锁操作,因为内部数组array不会发生修改,只会被另外一个array替代,因此可以保证数据安全。
写操作如下:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}首先,写操作使用锁,这个锁仅限于控制写-写的情况。其重点在于第7行代码,进行了内部元素的完整复制。因此,会生成一个新的数组newElements。然后,将新的元素加入newElements。接着,在第9行,使用新的数组替换老的数组,修改就完成了。整个过程不会影响读取,并且修改完后,读取线程可以立即“察觉”到这个修改(因为array变量是volatile类型)。
6)数据共享通道:BlockingQueue
我们使用BlockingQueue进行多个线程间的数据共享。主要介绍ArrayBlockingQueue和LinkedBlockingQueue。ArrayBlockingQueue是基于数组实现的,而LinkedBlockingQueue基于链表。因此,ArrayBlockingQueue更适合做有界对垒,因为队列中可容纳的最大元素需要在队列创建时指定。而LinkedBlockingQueue适合做无界队列,或者那些边界值非常大的队列。
BlockingQueue让服务线程在队列为空时,进行等待,当有新的消息进入队列后,自动将线程唤醒。以ArrayBlockingQueue为例。
ArrayBlockingQueue的内部元素都放置在一个对象数组中:
final Object[] items;
向队列中压入元素可以使用offer()方法和put()方法。对于offer()方法,如果当前队列已经满了,它就会立即返回false。如果没有满,则执行正常的入队操作。我们需要关注的是put()方法。put()方法也是将元素压入队列末尾。如果队列满了,它会一直等待,直到队列中有空闲的位置。
从队列中弹出元素可以使用poll()方法和take()方法。它们都是从队列的头部获得一个元素。不同之处在于:如果队列为空poll()方法直接返回null,而take()方法会等待,直到队列内有可用元素。
因此,put()方法和take()方法才是体现Blocking的关键。为了做好等待和
c1ba
通知两件事,在ArrayBlockingQueue内部定义了一下一些字段:
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
当执行take()操作时,如果队列为空,则让当前线程等待在notEmpty上。新元素入队时,则进行一次notEmpty上的通知。
下面的代码显示了take()的过程:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return extract();
} finally {
lock.unlock();
}
}第6行代码,就要求当前线程进行等待。当队列中有新元素时,线程会得到一个通知。下面是元素入队时的一段代码:
private void insert(E x) {
items[putIndex] = x;
putIndex = inc(putIndex);
++count;
notEmpty.signal();
}注意第5行代码,当新元素进入队列后,需要通知等待在notEmpty上的线程,让它们继续工作。
同理,对于put()操作也是一样,当队列满时,需要让压入线程等待,如下面第7行。
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
insert(e);
} finally {
lock.unlock();
}
}当有元素从队列中被挪走,队列出现空位时,也需要通知等待入队的线程:
private E extract() {
final Object[] items = this.items;
E x = this.<E>cast(items[takeIndex]);
items[takeIndex] = null;
takeIndex = inc(takeIndex);
--count;
notFull.signal();
return x;
}上述代码表示从队列中拿走一个元素。当有空闲位置时,在第7行,通知等待入队的线程。
7)随机数据结构:跳表(SkipList)
跳表是一种可以用来快速查找的数据结构,有点类似平衡树。它们都可以对元素进行快速的查找。但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整。而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。
跳表的另外一个特点是随机算法。跳表的本质是同时维护了多个链表,并且链表是分层的。如图所示。
最底层的链表维护了跳表内所有的元素,每上面一层链表都是下面一层的子集,一个元素插入哪些层是完全随机的。
跳表内的所有链表的元素都是排序的。查找时,可以从顶级链表开始查找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续查找。也就是说在查找过程中,搜索是跳跃式的。
因此,跳表是一种使用空间换时间的算法。
使用跳表实现Map和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,会得到一个有序的结果。
实现这一数据结构的类是ConcurrentSkipListMap。下面展示了跳表的简单实用:
Map<Integer, Integer> map = new ConcurrentSkipListMap<Integer, Integer>();
for(int i=0; i<30; i++) {
map.put(i,i);
}
for(Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey());
}和HashMap不同,对跳表的遍历输出是有序的。
跳表的内部实现有几个关键的数据结构组成。首先是Node,一个Node就是表示一个节点,里面含有两个重要的元素key和value(就是Map的key和value)。每个Node还会指向下一个Node,因此还有一个元素next。
static final class Node<K,V> {
final K key;
volatile Object value;
volatile Node<K,V> next;
}对Node的所有操作,使用的CAS方法:
boolean casValue(Object cmp, Object val) {
return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val);
}
boolean casNext(Node<K,V> cmp, Node<K,V> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}方法casValue()用来设置value的值,相对的casNext()用来设置next的字段。
另外一个重要的数据结构是Index,表示索引。它内部包装了Node,同时增加了向下的引用和向右的引用。
static class Index<K,V> {
final Node<K,V> node;
final Index<K,V> down;
volatile Index<K,V> right;
}整个跳表是根据Index进行全网的组织的。
此外,对于每一层的表头,还需要记录当前处于哪一层。为此,还需要一个称为HeadIndex的数据结构,表示链表头部的第一个Index。它继承自Index。
static final class HeadIndex<K,V> extends Index<K,V> {
final int level;
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
}注:本篇博客内容摘自《Java高并发程序设计》

相关文章推荐
- 【Java高并发学习】Fork/Join框架、以及JDK中的高并发容器
- java并发包学习系列:jdk并发容器(草稿)
- 黑马程序员 Java学习总结之JDK1.5并发库
- Java学习笔记(81)-----------并发容器之CopyOnWriteArrayList
- 《Java高并发程序设计》学习 --6.5 增强的Future:CompletableFuture
- java高并发程序设计学习笔记五六JDK并发包
- java高并发程序设计学习笔记一前言
- 跟着实例学习java多线程9-并发容器
- Java高并发程序设计 JDK并发包(上)
- java并发包:jdk并发容器
- JAVA高并发程序设计学习:Synchronized同步代码块具体使用方法
- java高并发程序设计学习笔记四无锁
- java并发容器ConcurrentHashMap学习心得
- Java 并发编程深入学习——CopyOnWrite容器使用和原理分析
- 一步步学习java并发编程模式之Active Object模式(五) 使用JDK的内置实现
- Java学习笔记(80)-----------并发容器之ConcurrentHashMap
- Java高并发程序设计笔记5之JDK同步控制
- Java高并发程序设计笔记6之JDK同步控制
- java高并发程序设计学习笔记二多线程基础
- JDK同步控制工具,JAVA高并发程序设计