开发中常用正则表达式及正则语法
2017-03-17 19:06
218 查看
两个在线正则测试地址:
http://tool.oschina.net/regex
https://regex101.com
1 . 校验密码强度
密码的强度必须是包含大小写字母中的一种和数字的组合,不能使用特殊字符,长度在8-10之间。
2. 校验中文
字符串仅能是中文。
3. 由数字、26个英文字母或下划线组成的字符串
4. 校验E-Mail 地址
同密码一样,下面是E-mail地址合规性的正则检查语句。
5. 校验身份证号码
下面是身份证号码的正则校验。15 或 18位。
15位:
18位:
6. 校验日期
“yyyy-mm-dd“ 格式的日期校验,已考虑平闰年。
7. 校验金额
金额校验,精确到2位小数。
8. 校验手机号
下面是国内 13、15、18开头的手机号正则表达式。(可根据目前国内收集号扩展前两位开头号码)
9. 判断IE的版本
IE目前还没被完全取代,很多页面还是需要做版本兼容,下面是IE版本检查的表达式。
10. 校验IP-v4地址
IP4 正则语句。
11. 校验IP-v6地址
IP6 正则语句。
12. 检查URL的前缀
应用开发中很多时候需要区分请求是HTTPS还是HTTP,通过下面的表达式可以取出一个url的前缀然后再逻辑判断。
13. 提取URL链接
下面的这个表达式可以筛选出一段文本中的URL。
14. 文件路径及扩展名校验
验证windows下文件路径和扩展名
15. 提取Color Hex Codes
有时需要抽取网页中的颜色代码,可以使用下面的表达式。
16. 提取网页图片
假若你想提取网页中所有图片信息,可以利用下面的表达式。
http://tool.oschina.net/regex
https://regex101.com
1 . 校验密码强度
密码的强度必须是包含大小写字母中的一种和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.*\d)+((?=.*[a-z])|(?=.*[A-Z])).{8,10}$2. 校验中文
字符串仅能是中文。
^[\u4e00-\u9fa5]{0,}$3. 由数字、26个英文字母或下划线组成的字符串
^\w+$
4. 校验E-Mail 地址
同密码一样,下面是E-mail地址合规性的正则检查语句。
[\w!#$%&'*+/=?^_`{|}~-]+(?:\.[\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\w](?:[\w-]*[\w])?\.)+[\w](?:[\w-]*[\w])?5. 校验身份证号码
下面是身份证号码的正则校验。15 或 18位。
15位:
^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$18位:
^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}([0-9]|X)$6. 校验日期
“yyyy-mm-dd“ 格式的日期校验,已考虑平闰年。
([0-9]{3}[1-9]|[0-9]{2}[1-9][0-9]{1}|[0-9]{1}[1-9][0-9]{2}|[1-9][0-9]{3})-(((0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|((0[469]|11)-(0[1-9]|[12][0-9]|30))|(02-(0[1-9]|[1][0-9]|2[0-8])))7. 校验金额
金额校验,精确到2位小数。
^[0-9]+(.[0-9]{2})?$8. 校验手机号
下面是国内 13、15、18开头的手机号正则表达式。(可根据目前国内收集号扩展前两位开头号码)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$9. 判断IE的版本
IE目前还没被完全取代,很多页面还是需要做版本兼容,下面是IE版本检查的表达式。
^.*MSIE [5-8](?:\.[0-9]+)?(?!.*Trident\/[5-9]\.0).*$
10. 校验IP-v4地址
IP4 正则语句。
\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b11. 校验IP-v6地址
IP6 正则语句。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))12. 检查URL的前缀
应用开发中很多时候需要区分请求是HTTPS还是HTTP,通过下面的表达式可以取出一个url的前缀然后再逻辑判断。
if (!s.match(/^[a-zA-Z]+:\/\//))
{
s = 'http://' + s;
}13. 提取URL链接
下面的这个表达式可以筛选出一段文本中的URL。
[a-zA-z]+://[^\s]*
14. 文件路径及扩展名校验
验证windows下文件路径和扩展名
^[a-zA-Z]:(((\\(?! )[^/:*?<>\""|\\]+)+\\?)|(\\)?)\s*$
15. 提取Color Hex Codes
有时需要抽取网页中的颜色代码,可以使用下面的表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$16. 提取网页图片
假若你想提取网页中所有图片信息,可以利用下面的表达式。
\< *
17. 提取页面超链接
提取html中的超链接。(<a\s*(?!.*\brel=)[^>]*)(href="https?:\/\/)((?!(?:(?:www\.)?'.implode('|(?:www\.)?', $follow_list).'))[^"]+)"((?!.*\brel=)[^>]*)(?:[^>]*)>
18. 抽取注释
如果你需要移除HMTL中的注释,可以使用如下的表达式。<!--(.*?)-->
19. 匹配HTML标签
通过下面的表达式可以匹配出HTML中的标签属性。<\/?\w+((\s+\w+(\s*=\s*(?:".*?"|'.*?'|[\^'">\s]+))?)+\s*|\s*)\/?>
以下引用:http://blog.csdn.net/virus2014/article/details/51217027正则表达式的语法规则:
一、行定位符(^和$)
行定位符就是用来描述字串的边界。“^”表示行的开始;“$”表示行的结尾。如:
^tm : 该表达式表示要匹配字串tm的开始位置是行头,如tm equal Tomorrow Moon就可以匹配
tm$ : 该表达式表示要匹配字串tm的位置是行尾,Tomorrow Moon equal tm匹配。
如果要匹配的字串可以出现在字符串的任意部分,那么可以直接 写成 :tm
二、单词定界符(\b、\B)
单词分界符\b,表示要查找的字串为一个完整的单词。如:\btm\b
还有一个大写的\B,意思和\b相反。它匹配的字串不能是一个完整的单词,而是其他单词或字串的一部分。如:\Btm\B
三、字符类([ ])
正则表达式是区分大小写的,如果要忽略大小写可使用方括号表达式“[]”。只要匹配的字符出现在方括号内,即可表示匹配成功。但要注意:一个方括号只能匹配一个字符。例如,要匹配的字串tm不区分大小写,那么该表达式应该写作如下格式:[Tt][Mm]
POSIX风格的预定义字符类如表所示:
[img]https://img-blog.csdn.net/20170316164739694?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvbWluZ2RhOA==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast" border="0" >
四、选择字符(|)
还有一种方法可以实现上面的匹配模式,就是使用选择字符(|)。该字符可以理解为“或”,如上例也可以写成 (T|t)(M|m),该表达式的意思是以字母T或t开头,后面接一个字母M或m。
使用“[]”和使用“|”的区别在于“[]”只能匹配单个字符,而“|”可以匹配任意长度的字串。如果不怕麻烦,上例还可以写为 :TM|tm|Tm|tM
五、连字符(-)
变量的命名规则是只能以字母和下划线开头。但这样一来,如果要使用正则表达式来匹配变量名的第一个字母,要写为 :[a,b,c,d…A,B,C,D…]
这无疑是非常麻烦的,正则表达式提供了连字符“-”来解决这个问题。连字符可以表示字符的范围。如上例可以写成 :[a-zA-Z]
六、排除字符([^])
上面的例子是匹配符合命名规则的变量。现在反过来,匹配不符合命名规则的变量,正则表达式提供了“^”字符。这个元字符在前面出现过,表示行的开始。而这里将会放到方括号中,表示排除的意思。
例如:[^a-zA-Z],该表达式匹配的就是不以字母和下划线开头的变量名。
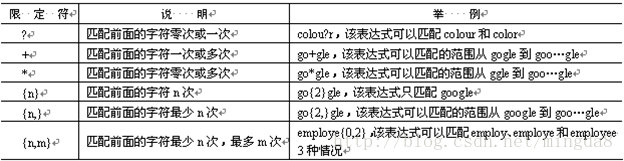
七、限定符(? * + {n,m})
对于重复出现字母或字串,可以使用限定符来实现匹配。限定符主要有6种,如表所示:
八、点号字符(.)
点字符(.)可以匹配出换行符外的任意一个字符。
注意:是除了换行符外的、任意的一个字符。如匹配以s开头、t结尾、中间包含一个字母的单词。
格式如下: ^s.t$,匹配的单词包括:sat、set、sit等。
再举一个实例,匹配一个单词,它的第一个字母为r,第3个字母为s,最后一个字母为t。能匹配该单词的正则表达式为:^r.s.*t$
九、转义字符(\)
正则表达式中的转移字符(\)和PHP中的大同小异,都是将特殊字符(如“.”、“?”、“\”等)变为普通的字符。举一个IP地址的实例,用正则表达式匹配诸如127.0.0.1这样格式的IP地址。如果直接使用点字符,格式为:[0-9]{1,3}(.[0-9]{1,3}){3}
这显然不对,因为“.”可以匹配一个任意字符。这时,不仅是127.0.0.1这样的IP,连127101011这样的字串也会被匹配出来。所以在使用“.”时,需要使用转义字符(\)。修改后上面的正则表达式格式为: [0-9]{1,3}(.[0-9]{1,3}){3}
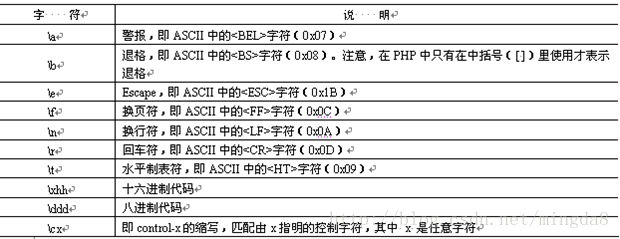
十、反斜线(\)
除了可以做转义字符外,反斜线还有其他一些功能。反斜线可以将一些不可打印的字符显示出来,如表所示:
还可以指定预定义字符集,如表所示:
反斜线还有一种功能,就是定义断言,其中已经了解过了\b、\B,其他如表所示:
十一、括号字符(())
小括号字符的第一个作用就是可以改变限定符的作用范围,如“|”、“*”、“^”等。来看下面的一个表达式。
(thir|four)th,这个表达式的意思是匹配单词thirth或fourth,如果不使用小括号,那么就变成了匹配单词thir和fourth了。
小括号的第二个作用是分组,也就是子表达式。如(.[0-9]{1,3}){3},就是对分组(.[0-9]{1,3})进行重复操作。后面要学到的反向引用和分组有着直接的关系。
十二、反向引用
反向引用需要使用到分组,分组就是使用()括起来的部分为一个整体,在进行分组匹配时的原则是:由外向内,由左向右。
反向引用如:\1,\2等。
\1:表示的是引用第一次匹配到的()括起来的部分
\2:表示的是引用第二次匹配到的()括起来的部分(1)例: String regex = "^(\\d)\\1$"; 首先这里是匹配两位,\d一位,\1又引用\d一位 这里的\1会去引用(\d)匹配到的内容,因为(\d)是第一次匹配到的内容。 如:str = "22"时,(\\d)匹配到2,所以\1引用(\\d)的值也为2,所以str="22"能匹配 str = "23"时,(\\d)匹配到2,因为\1引用(\\d)的值2,而这里是3,所以str="23"不能匹配 (2)例: String regex = "^(\\d)\\1[0-9](\d)\1{2}"; 注意在后面第二个(\d)\1{2}中的\1,这里的\1并不会去匹配他前面的(\d),而是匹配第一个(\\d) (3)例: String regex = "^(\d)\1[0-9](\d)\2{2}$"; 这里使用了\2引用第二次匹配到的分组,这里第二次匹配的分组为\2前面的(\d),这里的{2}指的是\2的值出现两次 (4)例: String regex = "^((\d)3)\1[0-9](\d)\2{2}$"; 当匹配中的分组有嵌套时,是从外向里匹配的,其次在由左向右匹配 这里主要是分析匹配到分组的顺序,首先匹配((\d)3)这整个部分,其次匹配((\d)3)里面的(\d),第三次匹配时最后一个\2前面的(\d)
十三、模式修饰符
模式修饰符的作用是设定模式。也就是规定正则表达式应该如何解释和应用。
不同的语言都有自己的模式设置,PHP中的主要模式如表所示:




相关文章推荐
- iOS开发------常用正则表达式语法以及常用正则
- BS开发中常用的javascript技术【常用的正则表达式及符号诠释】
- 开发中常用的正则表达式
- 常用数据验证数据表达式释义(附:正则表达式语法)
- WEB开发中常用的正则表达式
- 常用正则表达式及基本语法
- asp.net开发中,常用正则表达式
- 常用正则表达式及基础语法
- !!!最常用正则表达式语法
- web开发常用正则表达式
- C++中正则表达式使用,正则表达式语法以及常用正则表达式大全
- C#开发一些常用的正则表达式
- UE正则表达式语法及常用语句
- 常用正则表达式语法例句
- Delphi 正则表达式语法(4): 常用转义字符与 .
- Web网站开发常用正则表达式
- Delphi 正则表达式语法(4): 常用转义字符与 .
- WEB开发中常用的正则表达式
- 正则表达式语法及常用的正则表达式
- 前端开发中常用正则表达式