标签分类理论
2017-03-15 10:10
190 查看
原文链接:http://click.aliyun.com/m/13969/最近在做DMP,负责设计一套标签管理系统。在对现有标签进行整理的过程中,整理出了这套东西。
首先,我们可以列出一些常见或者不常见的的“标签”样例:
一部分标签是多值标签,多个原子标签整个作为一个整体形成一个标签,例如微博上人们用来描述自己的关键词列表:例如:
还有一部分标签,为每个原子标签额外添加了一个权值参数。这也是很常见的需求,例如用来表示用户对逻辑上相关联的一组取值的频次频率值,预测概率等。
最后,为多值标签的每个原子标签添加关联权值就得到了权值标签,而单个的原子标签带有权值也是常见的事情,例如给出一个预测年龄及其置信度。如果这种单kv结构也用权值标签来表示,就会显得累赘与奇怪。因此适合单独作为一类。
结论:从标签的组织形式上看,标签可以分为四类:
于是,我们就获得了两个基本正交的维度:
这四种标签结构类型,除特殊的
对于权值标签,除了原子标签的类型,其权值也应当有一个合适的类型。强制其类型为
标签的
结论:从标签的原子类型上看:标签可以分为
例如:
字符标签与枚举标签的区别?
枚举标签与其他标签的区别在哪里?枚举标签的特点就是需要维护一张标签字典表,用于维护从枚举Entry的ID到Item的映射关系。
枚举标签可以具有层次关系。例如"城市枚举标签"就可以有上层标签:"省份枚举标签"。
多个枚举标签的字典可以放在同一张表中。
为什么不采用字符串作为枚举的ID?
结论:即 : 原子标签的取值类型与解释方式。
该维度的取值有4种:
原子类型:{
除了
即,标签从形式上可以分为15个类型。恰好可以用4个bit表示。因为最常见的标签都是单值标签,所以将标签结构类型的位域放在标签原子类型的位域之前是合理的设计。
这里需要提一下的是,标签形式分类与其存储类型的映射关系:存储上,单值标签采用
标签的人为分类适合使用动态分类体系通过外键引入。
Schema的设计如下:
cplus-taxonomy-schema.png
0. 标签的定义:标签分类学(Taxonomy)
对于标签(tag),很难列出一个公认的定义,指明这个概念的种差与属概念。所以为了把握这个概念,就需要采取定义另一种办法:分类与枚举。我们要解决的第一个问题是,有哪些类型的标签,如何对标签进行分类。首先不妨对“如何分类”本身进行分类,我们可以从“形式”与“内容”上分辨考察标签的分类。1. 标签的形式分类
标签的形式是标签分类最主要的依据。首先,我们可以列出一些常见或者不常见的的“标签”样例:
性别标签:女
年龄标签:23体重标签:90.6偶像标签:阿西莫夫
最近到过的城市标签:['北京','青岛','成都']
兴趣标签:['滑雪','旅游','吃']
三围标签:[100,100,100]
上年消费额标签:[5250.12,6873.23,1232.12,3231.23,...,2321.24]
网站浏览偏好标签:{"问答类":0.55, "交友类":0.75, "旅游类":0.82, "团购类":0.32,"电商":0.78,...}
手机品牌偏好标签:{"iphone7":0.99, "iphone5":0.35, "小米3":0.12,...}
预测游戏分数标签:{0 : 0.2, ..., 100 : 0.003, ..., 198 : 0.01, 199 : 0.01, 2100 : 0.005,...}
预测年龄标签:30 : <置信度0.72>通过观察我们可以发现一些东西1.1 从标签的组织形式上看
通常意义上的标签是单值标签,或称原子标签。其取值是一个独立的值。如女,
23,
90.6。
一部分标签是多值标签,多个原子标签整个作为一个整体形成一个标签,例如微博上人们用来描述自己的关键词列表:例如:
['90后','处女座','么么哒']。
还有一部分标签,为每个原子标签额外添加了一个权值参数。这也是很常见的需求,例如用来表示用户对逻辑上相关联的一组取值的频次频率值,预测概率等。
最后,为多值标签的每个原子标签添加关联权值就得到了权值标签,而单个的原子标签带有权值也是常见的事情,例如给出一个预测年龄及其置信度。如果这种单kv结构也用权值标签来表示,就会显得累赘与奇怪。因此适合单独作为一类。
结论:从标签的组织形式上看,标签可以分为四类:
单值标签,
单权标签,
多值标签,
多权标签。
于是,我们就获得了两个基本正交的维度:
是否为多值标签,
是否带有权值。
这四种标签结构类型,除特殊的
单权标签后,恰好与JSON的三种Primitive Type:
atomic, array, object相对应。
1.2 从标签的原子类型上来看
我们知道,计算机的物理实现本质上只提供了整形与
浮点两种原子数据类型。将指针,单字符,布尔,浮点数都归入数值类型,将极其常用的字符数组看做字符串类型,那么逻辑上其实我们只有两种原子数据类型:即
数值类型(Numeric)与
字符串(String)。我们当然希望所有原子标签的类型只有
数值与
字符串两种简单的分类。但出于一些现实的约束(比如就是有离散标签与连续值标签的区分,比如ODPS就区分BIGINT和DOUBLE),我们还是会将
数值细分为
整形与
浮点,所以,用于原子标签的类型就变为三种:
整型、浮点,字符串。
对于权值标签,除了原子标签的类型,其权值也应当有一个合适的类型。强制其类型为
数值是一个合理且合适的约束,可以通过强制其物理类型为Double轻易实现。
标签的
原子类型维度和标签的
结构类型维度并不完全正交,这是出于一些技术上的约束。例如Python中的Dict,
数值类型是可以作为key的,然而JSON规范中,只有
字符串可以作为Object的key。
整形可以通过序列化安全地转换为字符串间接地作为key。但
浮点的不精密则会带来诸多麻烦,所以
多值标签的原子类型维度不可以取值
浮点。
结论:从标签的原子类型上看:标签可以分为
整形,
浮点,
字符串。
1.3 从对整形原子类型的解释方法上看
在2.1.2中,我们对标签的原子类型进行了分类,但出于生产实践的考虑,我们必须考虑另一种非常常见的情况,即枚举标签。枚举标签通常用一个整形表示标签取值,同时提供一个从整型值到字符串的字典,用于解释这个整型值。
例如:
# 性别标签字典gender_dict = {0:'男', 1:'女', 2: '人妖'....}# 性别标签取值0 # 一个用于表示男性的单值枚举标签[0, 0, 1, 0] # 一个用于表示家庭性别构成的多值枚举标签{0 : 0.1, 1: 0.4} # 一个用来表示预测性别+置信度 或者 性取向+倾向度 的多值枚举标签。再比如:# 省份对照字典province_dict = {11:'北京',12:'天津',13:'河北',......}# 省份取值标签13 # 单值枚举标签,我到河北省来!{'11': 0.76, '13':0.1} # 多值枚举标签,例如用户下一步预测作案地点概率+可行性。所以我们也可以发现,其实布尔类型就是一种特殊的枚举标签,有0:'False',1:'True'两个选项(先不考虑nullable)。完全可以自然地纳入枚举标签的体系中。所以,对于整形原子类型的解释方法,又可以成为一个标签分类的维度。即是否为枚举标签,由于这个维度和2.1.3中原子标签类型的维度高度相关(当原子标签类型为整形时本维度才有效),所以这两个维度应当合二为一。FAQ:枚举与整形的区别在哪里,即什么时候用整形什么时候用枚举?很简单,取值可以穷尽且数目合理的时候用枚举。例如,城市代码就是一个很合适的枚举标签。但一个人的头发数目虽然肯定是一个整数,但就不适合作为枚举标签了。
字符标签与枚举标签的区别?
例如,用户使用的手机品牌,似乎可以用一个单值字符标签标示,也可以用枚举来实现,但它更适合使用字符标签而非枚举标签。因为手机品牌并不是数目固定的,会不断地有品牌诞生与消逝。在这种情况下,枚举字典的频繁变化将对于标签使用带来诸多不便。
枚举标签与其他标签的区别在哪里?枚举标签的特点就是需要维护一张标签字典表,用于维护从枚举Entry的ID到Item的映射关系。
枚举标签可以具有层次关系。例如"城市枚举标签"就可以有上层标签:"省份枚举标签"。
多个枚举标签的字典可以放在同一张表中。
为什么不采用字符串作为枚举的ID?
在绝大多数语言中,枚举都是默认以整形实现的。整型实现的枚举标签相对字符串的实现具有巨大的性能优势。
结论:即 : 原子标签的取值类型与解释方式。
该维度的取值有4种:
枚举,
整形,
浮点,
字符串
1.4 小结
由上述可知,从标签的形式上,我们获得了两个大的,基本正交的分类维度:组织形式:{单值标签,
单权标签,
多值标签,
多权标签}
原子类型:{
枚举标签,
整形标签,
文本标签,
浮点标签, }
除了
浮点多权标签不是合理的组合之外,其他共计
4 x 4 -1 = 15种组合。
即,标签从形式上可以分为15个类型。恰好可以用4个bit表示。因为最常见的标签都是单值标签,所以将标签结构类型的位域放在标签原子类型的位域之前是合理的设计。
1.4.1 标签结构类型字段
| 结构 | 标记 | 说明 |
|---|---|---|
| 单值标签 | 0x00 | 取值为单一原子类型相应值 |
| 单权标签 | 0x01 | 取值为单一原子类型及其权值,可以以分隔符值,数组或字典等形式实现。 |
| 多值标签 | 0x10 | 取值为同种原子类型组成的列表 |
| 权值标签 | 0x10 | 取值为同种原子类型组成的字典,key只能为string或string(bigint) |
1.4.2 标签原子类型字段
| 结构 | 标记 | 说明 |
|---|---|---|
| 枚举标签 | 0x00 | 实际为Bigint类型,默认类型,需要对照类型字典解读 |
| 整形标签 | 0x01 | 整形数值原子标签 |
| 文本标签 | 0x10 | 字符串原子标签 |
| 浮点标签 | 0x11 | 浮点数数值原子标签 |
1.4.3 标签形式分类一览表
| 类型ID | 英文代号 | 名称 | 结构ID | 结构名 | 原子ID | 原子名称 | 存储 |
|---|---|---|---|---|---|---|---|
| 0 | atom-enum | 单值枚举 | 0 | 单值 | 0 | 枚举 | int |
| 1 | atom-int | 单值整形 | 0 | 单值 | 1 | 整形 | int |
| 2 | atom-text | 单值文本 | 0 | 单值 | 2 | 文本 | text |
| 3 | atom-float | 单值浮点 | 0 | 单值 | 3 | 浮点 | float |
| 4 | paire-enum | 单权枚举 | 1 | 单权 | 0 | 枚举 | json |
| 5 | paire-int | 单权整形 | 1 | 单权 | 1 | 整形 | json |
| 6 | paire-text | 单权文本 | 1 | 单权 | 2 | 文本 | json |
| 7 | paire-float | 单权浮点 | 1 | 单权 | 3 | 浮点 | json |
| 8 | list-enum | 多值枚举 | 2 | 多值 | 0 | 枚举 | json |
| 9 | list-int | 多值整形 | 2 | 多值 | 1 | 整形 | json |
| 10 | list-text | 多值文本 | 2 | 多值 | 2 | 文本 | json |
| 11 | list-float | 多值浮点 | 2 | 多值 | 3 | 浮点 | json |
| 12 | dict-enum | 多权枚举 | 3 | 多权 | 0 | 枚举 | json |
| 13 | dict-int | 多权整形 | 3 | 多权 | 1 | 整形 | json |
| 14 | dict-text | 多权文本 | 3 | 多权 | 2 | 文本 | json |
Bigint,
Double,
String存储。单权标签采用长度固定为2的数组
[value,weight]存储,多值标签采用数组存储
[value1,value2,...],多权标签采用对象
{v1:w1}存储,且当原子类型为整形与枚举时,其中的value应当存储其字符串序列化形式以符合JSON对key类型的要求。从结果上看,所有单值标签都直接以其对应类型进行序列化存储。其余所有标签都采用JSON序列化的方式存储。下面给出每种标签的样例:
1.4.4 标签形式分类样例表
| id | title | storage | sample |
|---|---|---|---|
| 0 | 单值枚举 | int | 性别标签:1 {"0":"男", "1" :"女"} |
| 1 | 单值整形 | int | 年龄:23 |
| 2 | 单值文本 | text | 喜爱小说:"百年孤独" |
| 3 | 单值浮点 | float | 体重:60.13 |
| 4 | 单权枚举 | json | 预测性别:[1, 0.99] |
| 5 | 单权整形 | json | 预测年龄:[23, 0.99] |
| 6 | 单权文本 | json | 电视剧-喜爱度:["星际迷航", 9.8] |
| 7 | 单权浮点 | json | 预测体重:[60.13, 0.78] |
| 8 | 多值枚举 | json | 闹钟设置:[1, 2, 3, 4, 5] |
| 9 | 多值整形 | json | 三围:[100, 100, 100] |
| 10 | 多值文本 | json | 喜爱电视剧:["星际迷航", "绝命毒师", "是的,大臣!"] |
| 11 | 多值浮点 | json | 月度消费记录:[6379.13, 6378.24, 6356.12] |
| 12 | 多权枚举 | json | 闹钟设置概率分布:{"1":0.98, "2" :0.75, "3" :0.75, "4" :0.5, "5" :0.3} |
| 13 | 多权整形 | json | 幸运数字 - 喜爱度:{"7":0.32, "5" :0.63} |
| 14 | 多权文本 | json | 网站浏览偏好标签:{"问答类":0.55, "交友类" :0.75} |
2. 标签的内容分类
标签按内容性质分类的方式,相比形式分类显得十分多样。可以纯粹的从标签的取值特性上分类(Nullable,权值是否归一化,etc...),也可以从标签的来源场景(移动端,PC端),标签的所有权(私有,内部,群组,公司),标签的规模,标签的依赖,标签的row ID类型(OneID, acookie, mobile, umid, etc...),或者前端展示时采用的层级类目等等很多维度上进行分类。形式分类会决定标签的展现形式,但内容分类并没有这种影响。所以按内容分类的结果更适合作为描述字段而非放入类型字段。换句话说,与其把内容分类称为分类,倒不如称之为枚举属性更为合适。但是对于内容分类,我们仍然需要进一步的考察。按标签内容分类可以进一步细分为: 按标签固有属性分类,和按人为用途分类。属于标签固有属性的,适合放入标签元数据表中,作为一个字段。而属于人为用途划分的,因为需求可能会频繁地发生变化,所以需要提供一种在不改变数据库Schema的前提下支持动态增添分类体系的机制来实现这一需求。本文建议采用类似"WordPress"的Taxonomy概念,为人为划分构建一个动态分类体系。2.2 标签动态分类体系的设计
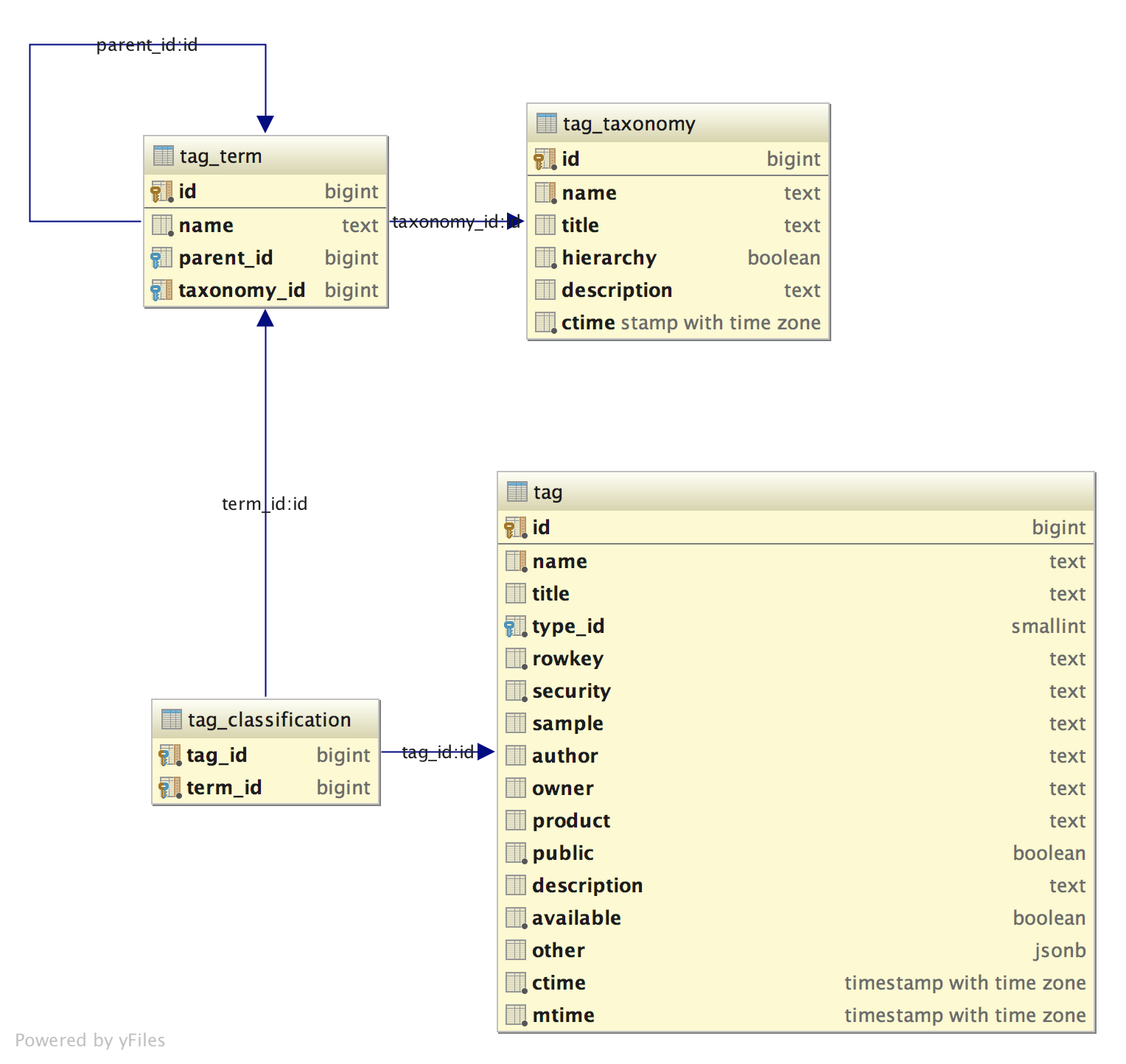
为了提供适应这种变化需求的灵活性,可以考虑构建一张分类体系表(tag_taxonomy)、一张分类项表(tag_term)、一张分类表(tag_classification)。动态的实现分类体系的增添。如果需要实现带有层次结构的分类体系,只需要在分类项中,为每个分类条目维护一个父条目的指针即可。举个例子,如果我们需要动态添加一个"公私"分类。首先,需要在分类体系表里注册这种分类体系:"标签公私分类体系"。然后在分类项表中,添加"公有","私有",两个分类体系的具体取值条目。最后,在标签分类表中,将标签与分类具体取值相关联。2.3 小结
对于标签的内容分类:标签的固有性质适合作为标签表的字段出现标签的人为分类适合使用动态分类体系通过外键引入。
Schema的设计如下:
cplus-taxonomy-schema.png

相关文章推荐
- 标签分类理论
- 标签分类理论
- WordPress获取某个分类关联的标签
- 组织行为学对项目管理的意义:动机理论 . 分类: 项目管理 2014-06-25 19:12 263人阅读 评论(0) 收藏
- 使用caffe训练一个多标签分类/回归模型
- 译:用标准C编写COM(八) 2010-08-04 15:32:07| 分类: ActiveX Scriptin | 标签: |举报 |字号大
- 单端反激式变换器开关稳压电源原理图 此博文包含图片 (2009-02-24 12:17:53)转载▼ 标签: 单端反激式 变换器 高频变压器 原理图 磁滞回线 磁心 杂谈 分类: technical
- 深度学习与文本分类总结第二篇--大规模多标签文本分类
- IPV4理论知识3----分类编址址两级编址
- 内容的分类和标签
- WordPress让分类/标签等存档页也能置顶文章
- 【像黑客一样写博客之八】分类标签
- (转)如何创建Filter的属性页 [此博文包含图片] (2012-09-06 10:15:58) 转载 ▼ 标签: 杂谈 分类: DirectShow http://blog.csdn.net/
- 在Eclipse下,采用mulan多标签分类软件进行一个简单的测试实验
- HTML——常用标签元素分类
- ML-KNN(多标签分类)
- Android Gradle 多版本多APK打包,修改生成APK名称 标签: androidgradle多版本打包 2017-04-01 15:16 1113人阅读 评论(0) 收藏 举报 分类:
- 基于live555的rtsp 客户端模块优化 标签: live555rtsp客户端 2014-11-14 09:24 980人阅读 评论(0) 收藏 举报 分类: 流媒体(16) 版权声明:本文
- 多标签分类(multilabel classification )
- 利用人工智能(Magpie开源库)给一段中文的文本内容进行分类打标签