A Tutorial on Clustering Algorithms - Clustering Algorithms【翻译】
2017-03-11 21:25
441 查看
原文章 A Tutorial on Clustering Algorithms,包含以下部分:
☑ Introduction
☑ Clustering Algorithms
☑ K-means
☒ Fuzzy C-means
☒ Hierarchical
☒ Mixture of Gaussians
本文为 Clustering Algorithms 翻译内容,后续内容请直接点击以上链接(☑为已完成内容)。
本文系Subson翻译,转载请注明。
互斥聚类
重叠聚类
层次聚类
概率聚类
第一种聚类算法采用互斥的方式将数据聚类,所以如果某一个数据属于一个确切的族簇,那么它将不会包含在另一个族簇中。下图为一个简单的例子,其中点的分离是通过二维平面上的一条直线。

与第一种聚类算法相反,第二种重叠聚类使用模糊数据集聚类数据,所以在不同程度关系上来看一个点可能属于两个或者更多的族簇。这种情况下,数据将会关联一个合适的关系值。
作为替代,层次聚类算法是基于最近的两个族簇的联合。初始条件是设置作为族簇的每一个基准。经过几次迭代它能达到期望的族簇。
最后一种聚类算法完全采用概率学方法。
在本教程中,我们提出四种最常用的聚类算法:
K-means
Fuzzy C-means
Hierarchical clustering
Mixtyre of Gaussians
这里四种具体的聚类算法分别是上面列举的四种聚类算法的一种。K-means属于互斥聚类,Fuzzy C-means属于重叠聚类,Hierarchical clustering显然是层次聚类,Mixtyre of Gaussians属于概率聚类算法。我们将在接下来的段落讨论以上每一种聚类算法。
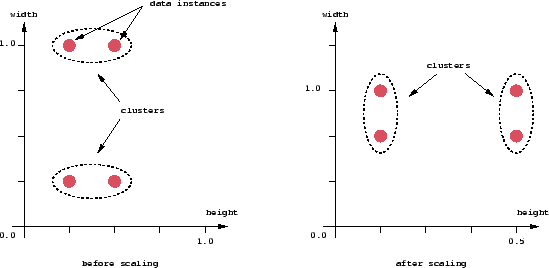
注意这不仅仅是一个平面问题,这种问题也发生在联合为了聚类的目的所采用的独特距离测度和数据特征向量的单一组成的数学公式上,即不同的公式导致不同的聚类结果。
重述,对于每个具体的应用必须将领域知识用于指导合适的距离测度公式。
dp(xi,xj)=(∑K−1d∣∣xi,k−xj,k∣∣p)1p
其中d是数据的纬度。欧氏距离是p=2时的特殊情况,当p=1时则是曼哈顿指标。然而对于任意给定的应用场景,并没有一个一般化理论进行指导。
通常情况下,数据特征向量的分量不具备即刻可比性。可能是这些分量不是连续变量,比如长度,而某些只是名义上的分类,比如一星期的每一天。这再次说明,领域知识必须用于制定合适的度量。
后续章节待续。。。
本文系Subson翻译,转载请注明。
☑ Introduction
☑ Clustering Algorithms
☑ K-means
☒ Fuzzy C-means
☒ Hierarchical
☒ Mixture of Gaussians
本文为 Clustering Algorithms 翻译内容,后续内容请直接点击以上链接(☑为已完成内容)。
本文系Subson翻译,转载请注明。
聚类算法
算法分类
聚类算法可被分为以下列出的:互斥聚类
重叠聚类
层次聚类
概率聚类
第一种聚类算法采用互斥的方式将数据聚类,所以如果某一个数据属于一个确切的族簇,那么它将不会包含在另一个族簇中。下图为一个简单的例子,其中点的分离是通过二维平面上的一条直线。
与第一种聚类算法相反,第二种重叠聚类使用模糊数据集聚类数据,所以在不同程度关系上来看一个点可能属于两个或者更多的族簇。这种情况下,数据将会关联一个合适的关系值。
作为替代,层次聚类算法是基于最近的两个族簇的联合。初始条件是设置作为族簇的每一个基准。经过几次迭代它能达到期望的族簇。
最后一种聚类算法完全采用概率学方法。
在本教程中,我们提出四种最常用的聚类算法:
K-means
Fuzzy C-means
Hierarchical clustering
Mixtyre of Gaussians
这里四种具体的聚类算法分别是上面列举的四种聚类算法的一种。K-means属于互斥聚类,Fuzzy C-means属于重叠聚类,Hierarchical clustering显然是层次聚类,Mixtyre of Gaussians属于概率聚类算法。我们将在接下来的段落讨论以上每一种聚类算法。
距离测度
聚类算法一个非常重要的组成是数据点之间的距离测度。如果数据矢量实例分量都具有相同的物理单元,那么采用简单的欧氏距离度量去成功聚类相似数据实例是足够的。然而即使这样,欧氏距离有时也能导致误导,下图采用宽度和高度作为距离测度举例说明。两种测度都采用相同的物理单元,使用不同的比例缩放(一个在宽度上做缩放,一个在高度上做缩放)。如图所示,不同的缩放导致不同的聚类结果。注意这不仅仅是一个平面问题,这种问题也发生在联合为了聚类的目的所采用的独特距离测度和数据特征向量的单一组成的数学公式上,即不同的公式导致不同的聚类结果。
重述,对于每个具体的应用必须将领域知识用于指导合适的距离测度公式。
闵可夫斯基度规
对于高维数据,一个常用的距离度量就是闵可夫斯基度规dp(xi,xj)=(∑K−1d∣∣xi,k−xj,k∣∣p)1p
其中d是数据的纬度。欧氏距离是p=2时的特殊情况,当p=1时则是曼哈顿指标。然而对于任意给定的应用场景,并没有一个一般化理论进行指导。
通常情况下,数据特征向量的分量不具备即刻可比性。可能是这些分量不是连续变量,比如长度,而某些只是名义上的分类,比如一星期的每一天。这再次说明,领域知识必须用于制定合适的度量。
后续章节待续。。。
本文系Subson翻译,转载请注明。

相关文章推荐
- A Tutorial on Clustering Algorithms - K-means【翻译】
- A Tutorial on Clustering Algorithms
- A Tutorial on Clustering Algorithms-聚类小知识
- A Tutorial on Clustering Algorithms
- Axure RP Pro - 翻译 - 5.5 Tutorial教程 - AXURE 202 Article 4: Rich Functionality复杂功能 - OnFocus and OnLostFocus Events - OnFocus和OnLo
- 翻译:A Tutorial on the Device Tree (Zynq) -- Part III
- 论文翻译:A Tutorial on Energy-Based Learning
- Axure RP Pro - 翻译 - 5.5 Tutorial教程 - AXURE 202 Article 6: Rich Functionality复杂功能 - OnPageLoad Event - OnPageLoad事件
- A tutorial on Spectral Clustering
- 论文:Banerjee A, Ghosh J. On Scaling Up Balanced Clustering Algorithms.[C]笔记
- 翻译:A Tutorial on the Device Tree (Zynq) -- Part I
- 翻译:A Tutorial on the Device Tree (Zynq) -- Part II
- Axure RP Pro - 翻译 - 5.5 Tutorial教程 - AXURE 202 Article 2: Rich Functionality复杂功能 - OnChange Event - OnChange事件
- top 10 tipis on Logging in Java- Tutorial (翻译)
- 翻译:A Tutorial on the Device Tree (Zynq) -- Part IV
- db4o Tutorial 中文翻译(十一)
- 《MapReduce: Simplified Data Processing on Large Cluster 》论文翻译
- ruby on rails tutorial 笔记 (第四章)
- A tutorial on Principal Components Analysis - 主成分分析(PCA)教程
- Qt on Android Episode 7(翻译)