Python批量爬取第三方库(安装)(二进制.whl文件)
2017-03-10 17:33
676 查看
使用 pip 下载安装某些第三方库,是一件很痛苦的事情,下载速度很慢。一旦下载超时,下载会被中止,需要重新下载。
本人用Python批量爬取http://www.lfd.uci.edu/~gohlke/pythonlibs/上的第三方库(二进制.whl文件)
save_path = 'F:\\test\\test'
url = 'http://www.lfd.uci.edu/~gohlke/pythonlibs/'
html = getHtml(url)
print('html done')
html_mod=re.sub('.' , '.' , html)
name_list = re.findall(r'title=\W+>(.*-py2.*whl)</a>',html_mod)
正式的下载地址为:http://www.lfd.uci.edu/~gohlke/pythonlibs/tuth5y6k/semantic_version-2.6.0-py2.py3-none-any.whl
正式的下载地址为:" http://www.lfd.uci.edu/~gohlke/pythonlibs/ ” + “ tuth5y6k/ " + " *.whl "
中间的tuth5y6k每隔段时间会变化成其他字符
最好的办法是:
把url = 'http://www.lfd.uci.edu/~gohlke/pythonlibs/'
html = getHtml(url),把html写入.txt文件。
原网页把 “ . ” 变成了“. ”, 所以需要把“. ”替换 “ . ” 。
例如:原网页 semantic_version-2.6.0-py2.py3-none-any.whl 变成了 semantic_version-2ǒnj-py2.py3-none-any.whl,所以需要替换回来。
不过原网页可能把数字或字母替换成其他字符,需要自己自适应的替换回来。
html_mod=re.sub('‑' , '-' , html)
html_mod=re.sub('.' , '.' , html)
正则表达式(匹配不同的文件名):
name_list = re.findall(r'title=\W+>(.*-py2.*whl)</a>',html_mod) 本次下载中使用的正则表达式
name_list = re.findall(r'title=\W+>(.*cp27.*win32.*whl)</a>',html_mod)本次下载中使用的正则表达式
name_list = re.findall(r'title=\W+>(.*cp27.*amd64.*whl)</a>',html_mod)未使用
WHL文件是二进制文件,所以保存的时候需要以二进制写入(即wb),普通方式写入,会导致下载的文件安装不了。
file = open(file_name, 'wb')
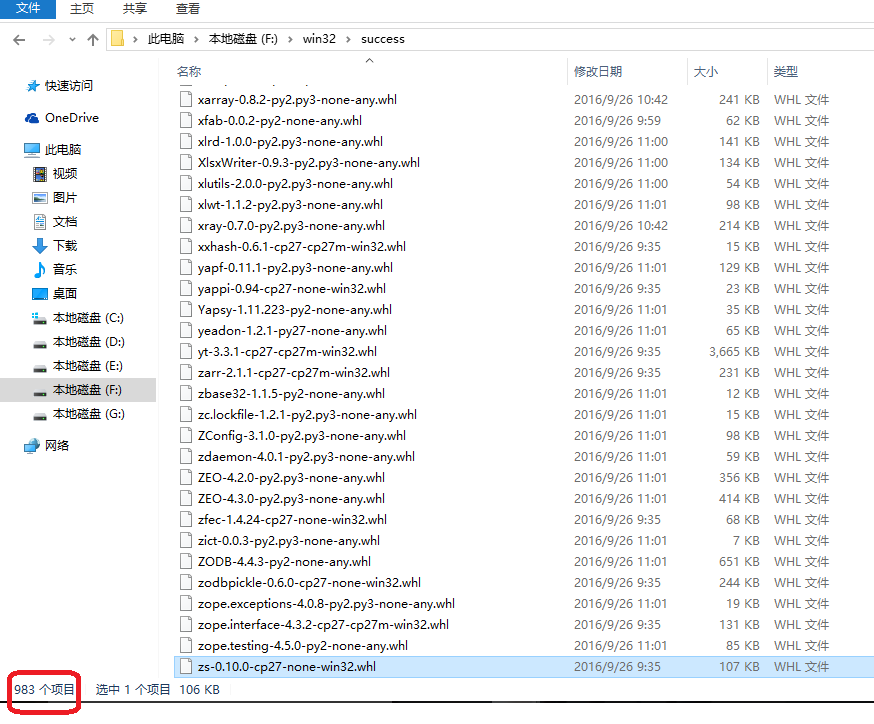
从红色框看出下载了983个whl项目
下载了这么多第三方库,在另外一台闲置电脑是试着写脚本安装所有983个第三方库。
本人用Python批量爬取http://www.lfd.uci.edu/~gohlke/pythonlibs/上的第三方库(二进制.whl文件)
url = 'http://www.lfd.uci.edu/~gohlke/pythonlibs/'
html = getHtml(url)
print('html done')
html_mod=re.sub('.' , '.' , html)
name_list = re.findall(r'title=\W+>(.*-py2.*whl)</a>',html_mod)
正式的下载地址为:http://www.lfd.uci.edu/~gohlke/pythonlibs/tuth5y6k/semantic_version-2.6.0-py2.py3-none-any.whl
正式的下载地址为:" http://www.lfd.uci.edu/~gohlke/pythonlibs/ ” + “ tuth5y6k/ " + " *.whl "
中间的tuth5y6k每隔段时间会变化成其他字符
最好的办法是:
把url = 'http://www.lfd.uci.edu/~gohlke/pythonlibs/'
html = getHtml(url),把html写入.txt文件。
原网页把 “ . ” 变成了“. ”, 所以需要把“. ”替换 “ . ” 。
例如:原网页 semantic_version-2.6.0-py2.py3-none-any.whl 变成了 semantic_version-2ǒnj-py2.py3-none-any.whl,所以需要替换回来。
不过原网页可能把数字或字母替换成其他字符,需要自己自适应的替换回来。
html_mod=re.sub('‑' , '-' , html)
html_mod=re.sub('.' , '.' , html)
正则表达式(匹配不同的文件名):
name_list = re.findall(r'title=\W+>(.*-py2.*whl)</a>',html_mod) 本次下载中使用的正则表达式
name_list = re.findall(r'title=\W+>(.*cp27.*win32.*whl)</a>',html_mod)本次下载中使用的正则表达式
name_list = re.findall(r'title=\W+>(.*cp27.*amd64.*whl)</a>',html_mod)未使用
WHL文件是二进制文件,所以保存的时候需要以二进制写入(即wb),普通方式写入,会导致下载的文件安装不了。
file = open(file_name, 'wb')
#!/usr/bin/env python
# coding=utf-8
import urllib
import urllib2
import re
import os,os.path
import codecs
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def download_file(download_url,file_name):
print download_url
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1)AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'}
req = urllib2.Request(download_url,headers=headers)
response = urllib2.urlopen(req)
file = open(file_name, 'wb')
file.write(response.read())
file.close()
print file_name
print("Completed : .... %d ..." % x)
save_path = 'F:\\test\\test'
url = 'http://www.lfd.uci.edu/~gohlke/pythonlibs/'
html = getHtml(url)
print('html done')
html_mod=re.sub('.' , '.' , html)
name_list = re.findall(r'title=\W+>(.*-py2.*whl)',html_mod)
x=1
files=os.listdir(save_path)
print files
for name in name_list:
file_name = os.path.join(save_path ,name)
if name in files:
continue
download_file('http://www.lfd.uci.edu/~gohlke/pythonlibs/dp2ng7en/'+name,file_name)
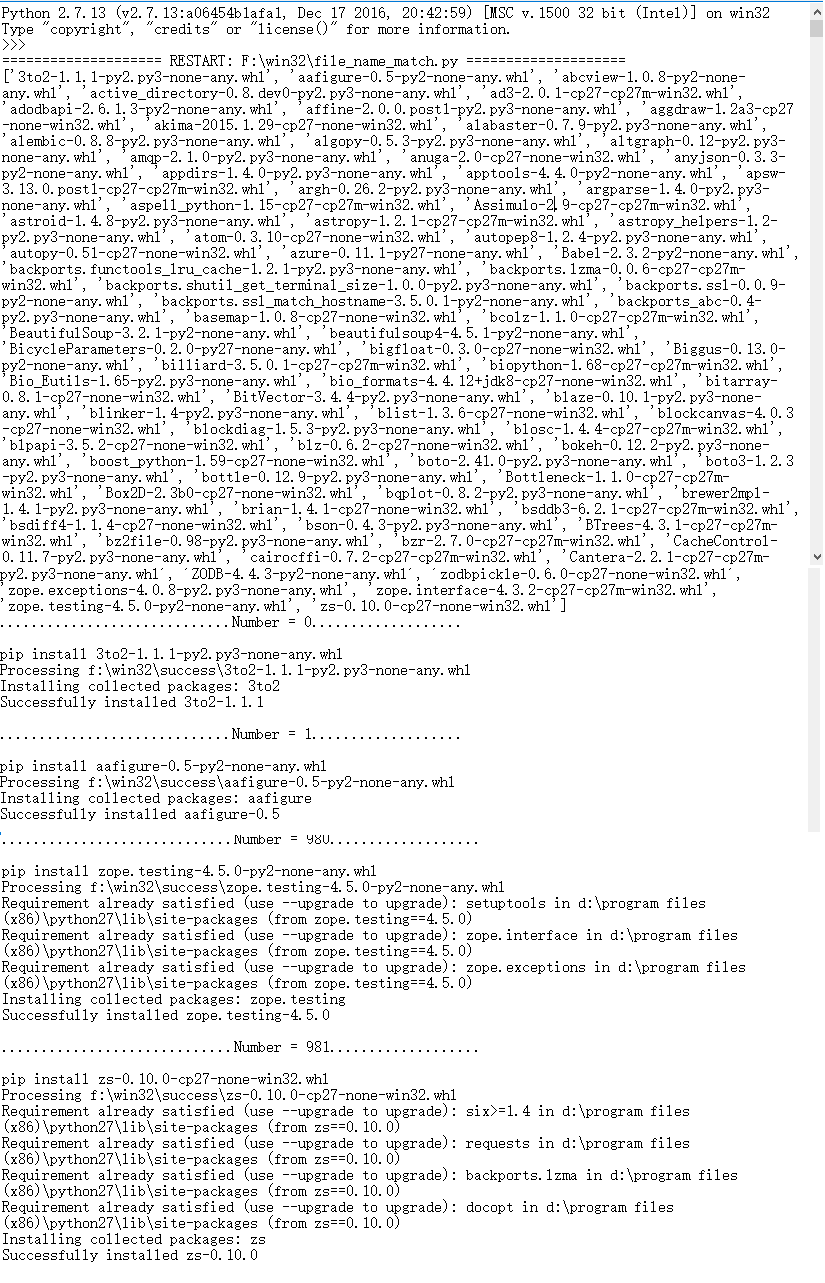
x=x+1从红色框看出下载了983个whl项目
下载了这么多第三方库,在另外一台闲置电脑是试着写脚本安装所有983个第三方库。
import urllib
import urllib2
import re
import os,os.path
import codecs
from subprocess import Popen,PIPE
downloaded_path='F:\\win32\\success'
filelist=[]
files=os.listdir(downloaded_path)
file_name=r'F:\win32\record_program_install.txt'
print files
x=0
for file in files:
file_name = os.path.join(downloaded_path ,file)
print('.............................Number = %d...................\n'%x )
print('pip install %s' % file)
output=os.popen('pip install %s' % file_name)
print output.read()
x+=1

相关文章推荐
- Python安装第三方库,如何安装.whl和.egg文件
- Python2.7安装第三方包pip .whl 文件
- python 安装pip和easy installers和whl文件
- python用pip安装whl后缀的模块文件
- python pip以及whl文件安装
- Win7,64位下Python3.5.2,安装Beautiful Soup 4(whl文件)
- python中的二进制numpy文件的作用及安装教程
- python 安装pip、.whl格式的文件
- python 下.whl 文件安装
- Win7,64位下Python3.5.2,安装numpy、matplotlib、scipy(whl文件)
- windows7下安装enum34 (whl文件)(python)
- Win7,64位下Python3.5.2,安装reportlab(whl文件)
- python的whl文件安装
- 历史文章分类汇总-Anaconda安装第三方包(whl文件)
- python第三方包的windows安装文件exe格式
- Python - Windows下安装easy_install, pip 及whl文件安装方法
- python文件whl的安装方法
- 如何给python安装.whl文件
- openCV + Python 配置问题,同时 配置 pip 和安装Python相关的库 即 那个 whl 文件
- Anaconda安装第三方包(whl文件)