[置顶] 机器学习笔记week2(Andrew NG)
2017-03-09 21:50
260 查看
机器学习笔记week2(Andrew NG)
martin
机器学习笔记week2Andrew NG
Linear Regression with Multiple Variable多元线性回归
Gradient Descent in Multivariate Linear Regression多元线性回归中的梯度下降
Features and Polynomial Regression特征与多项式回归
Normal Equation正规方程
OctaveMatlab TutorialOctaveMatlab教程
Linear Regression with Multiple Variable(多元线性回归)
在week1中讨论了单一变量的线性回归,但是在week2中我们会讨论多变量的线性回归,也即是多元线性回归。在week1中的预测房价的例子中输入变量只有一个即房子的面积,在week2中我们会根据房子的多种指标来预测房价。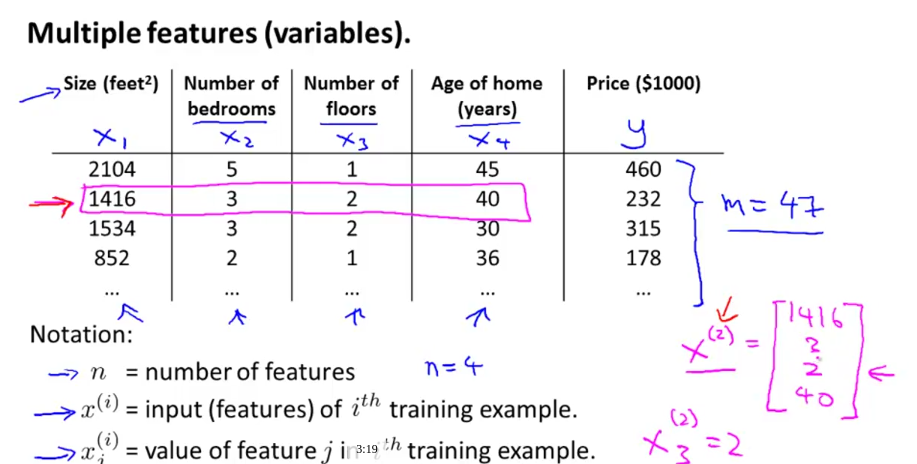
n代表了输入变量x中每一个数据含有的特征数。
选择题1

由于输入变量由单一变向多元,所以我们的假设函数也要随之变换:

可以从图片中看到,我们的假设函数变成了:
hθ(x)=θ0+θ1x1+θ2x2+...+θnxn
为了方便,我们通常定义x0=1,这样的话输入变量x就包含了x0从n维变成了n+1维,同样参数θ也从n维变成了n+1维。所以可以分别把输入变量x和参数θ写成向量的形式:
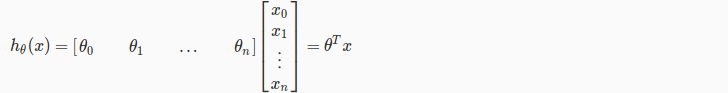
于是假设函数就变成了:
hθ(x)=θTX
Gradient Descent in Multivariate Linear Regression(多元线性回归中的梯度下降)
多元线性回归中的梯度下降的原理与单变量的一模一样,只是增加了多个求导项而已,下图给出了二者之间的对比:
左图是单变量(n=1)的参数更新,右图是多元(n>=1)的参数更新。可以看到二者其实没有什么差异。
选择题2

对于输入向量的特征这里还有些需要注意的事项:特征缩放和均值归一化。先来说说特征缩放:

为什么要采用特征缩放呢?从这附图中可以看出端倪。上图中的左边是未经特征缩放的关于θ1与θ2的轮廓图,右图是经过特征缩放的轮廓图,可以看出来左图比较瘦长,右图比较饱满。产生这种形状的原因是当输入变量的各个特征变量的范围相差很大时就会出现瘦长的轮廓图,而这种未经处理的特征在进行梯度下降时会走好多弯路,在曲折中前进震荡数次才会到达我们想要的终点,而经过处理的特征所呈现的轮廓图比较饱满,在进行梯度下降时会很快的进行收敛,有效的减少了震荡的次数,会径直的奔向终点。

再来说说均值归一化,这个算是特征缩放的加强版,作用与前者一样,下图就是均值归一化的运算公式和步骤:

如果样本的特征不是很好,那么我们可以运用归一化来代替原本的特征,这里有三种形式的归一化:
1、把数变成(0,1)之间的小数:x=xsum
2、把有量纲表达式变成无量纲表达式,并映射到(0,1):x=x−minmax−min
3、把有量纲表达式变成无量纲表达式,并映射到(-1,1):x=x−μσ
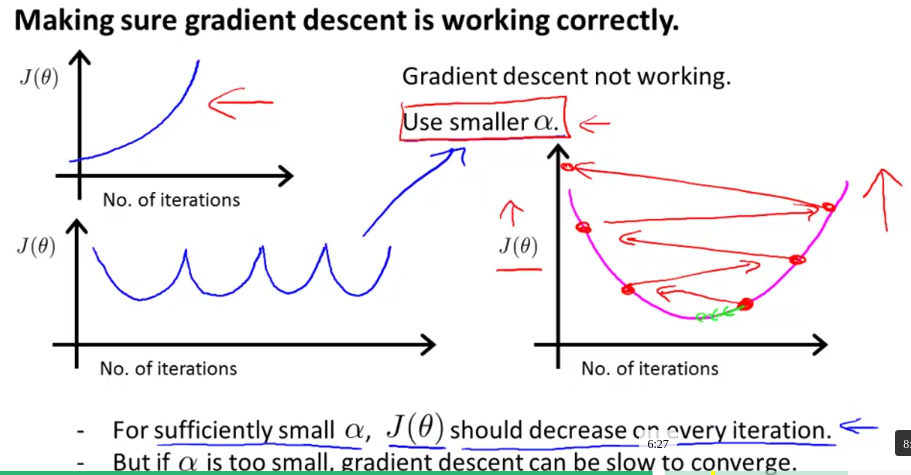
下面再来说说学习速率α的选择问题。正常情况下,当α选择适当,那么随着迭代的进行函数的代价函数会逐渐降低直至收敛:

但是,当α选择的过大时会导致震荡越过最优点,选择的过小时则会降低收敛的速度:
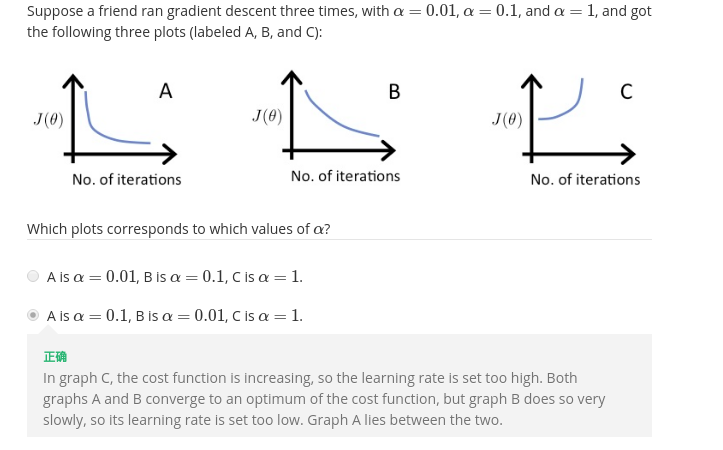
选择题3
Features and Polynomial Regression(特征与多项式回归)
可以将多项式回归变成线性回归,期间要进行特征缩放或者均值归一化: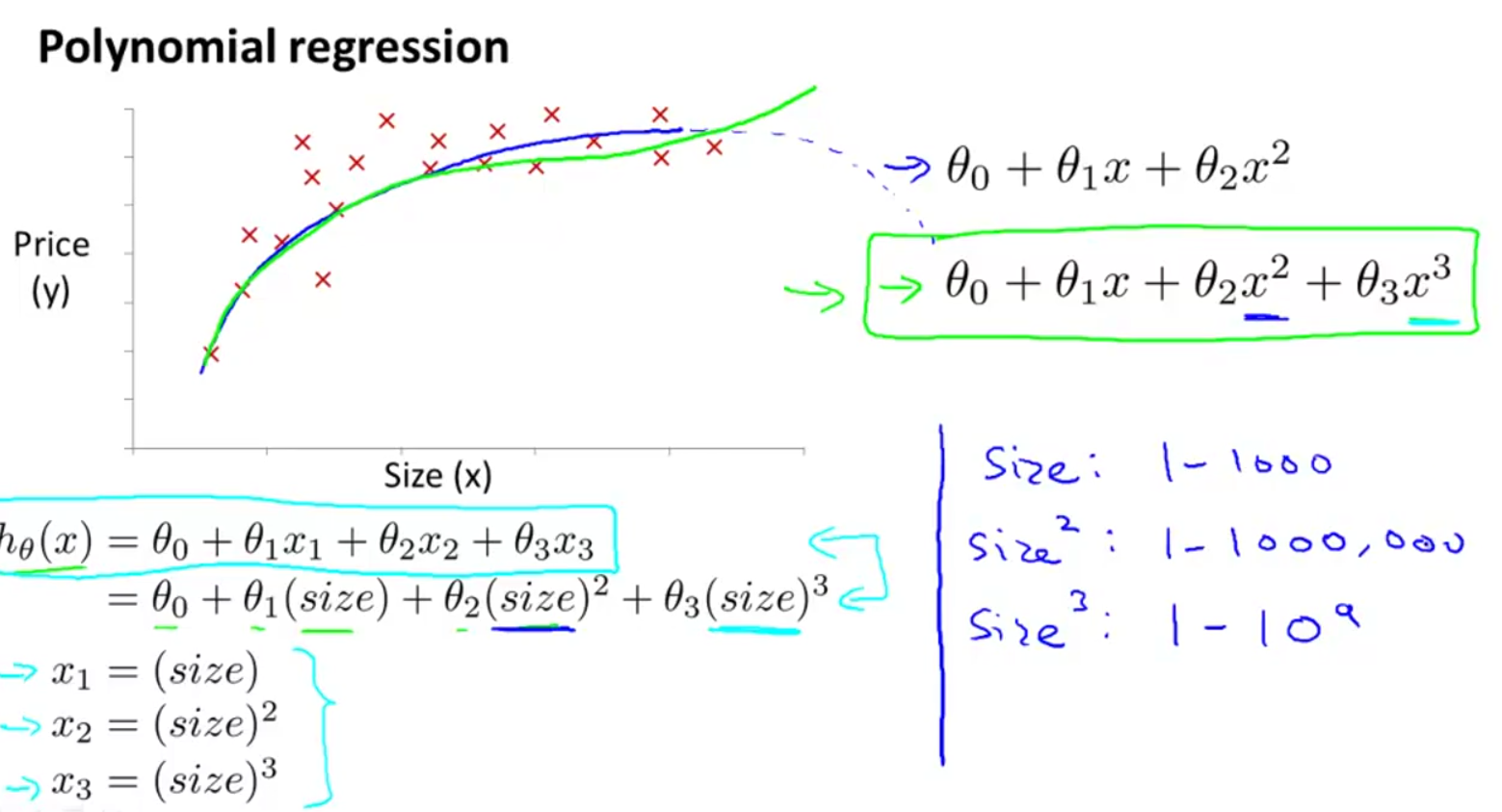
选择题4

Normal Equation(正规方程)
在某些时候用正规方程来求解参数θ的最优值效果会更好。相比用梯度下降方法用迭代来逐步求解最优值,正规方程可以一次性求解出最优值。这是正规方程的优点,当然也有缺点。在介绍它的优缺点之前我们先来看看什么是正规方程: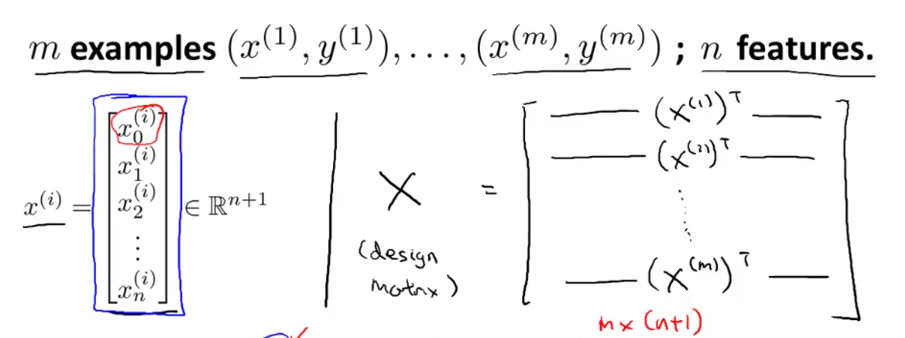
将m个数据集构成一个大的矩阵集合X,我们称这个矩阵集合为设计矩阵。每一个x都是n+1维的,所以X是一个m×(n+1)维的矩阵。需要注意的是每个x里面的x0=1。
选择题5
有了X和y的定义那么接下来的θ就好求了,给出正规方程的式子:
θ=(XTX)−1XTy
之前有说过梯度下降和正规方程各有优缺点,下图中已标出:

简而言之,就是当特征n不是特别大的时候,比如n=100,n=1000甚至n=10000时都可以采用正规方程,但是如果n继续增大就要考虑使用梯度下降了,因为当n特别大时计算XTX的逆矩阵是比较费时间的。
小节测试题1
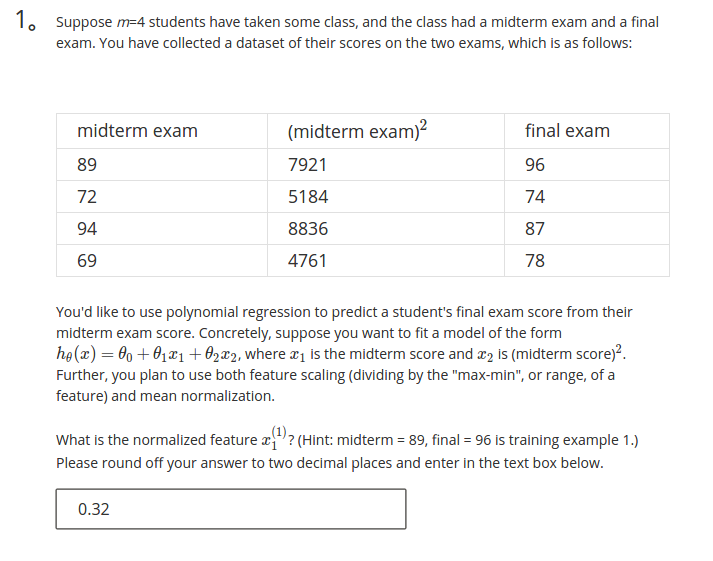
解析
μ=(89+72+94+69)4=81,S=max−min=94−69=25,故x(1)1=x(1)1−μS=0.32
小节选择题2

小节选择题3

小节选择题4

解析
当输入变量的特征大于104时就要考虑梯度下降时而不是正规方程了,因为当特征维数特别大时,矩阵的计算、求逆会变得特变慢。
小节选择题5

解析
特征缩放唯一能解决的就是在梯度下降时带来的速度的提升,并不能改变正规方程计算的速度。
Octave/Matlab Tutorial(Octave/Matlab教程)
基本操作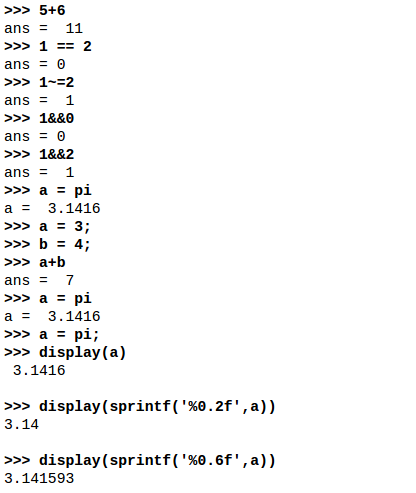
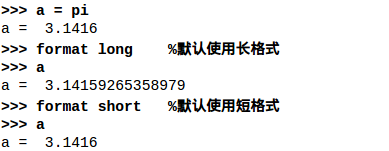





移动数据




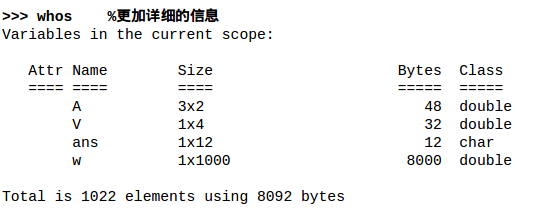







数据计算






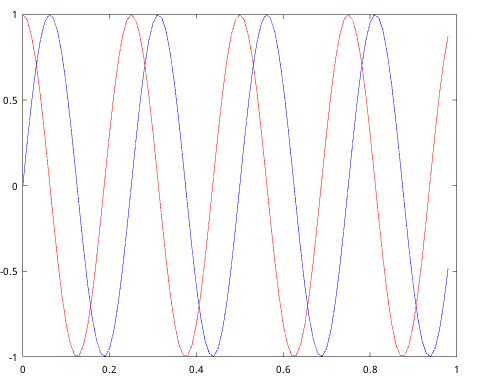
绘制数据





控制语句
for循环
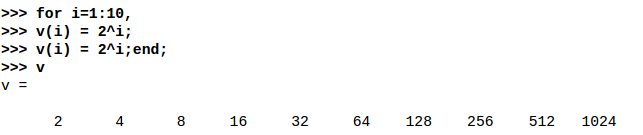
注意,Octave里面的for是可以循环到最后一个迭代元素的,也就是上如上图i是可以等于10的。
while循环
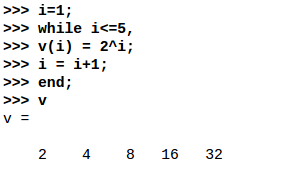
break

if语句

定义函数
编辑器:

命令行:

问题描述:
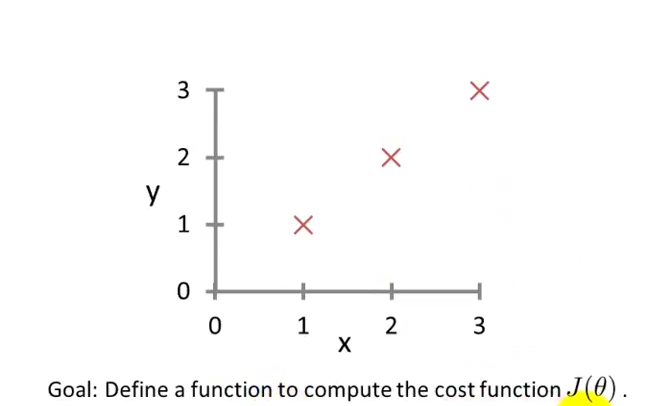
构建一个损失函数来计算图中三点的误差。
编辑器:
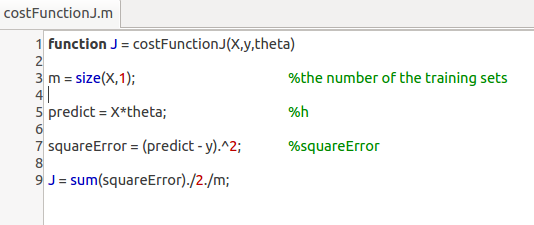
命令行:

小结测试题1

小结测试题2

小结测试题3
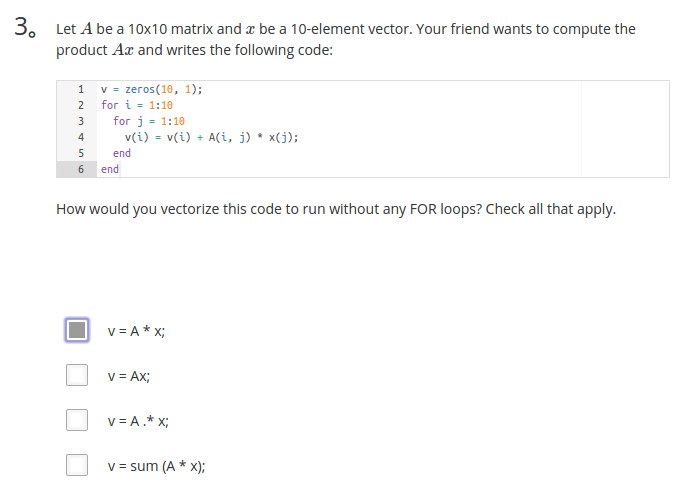
小结测试题4
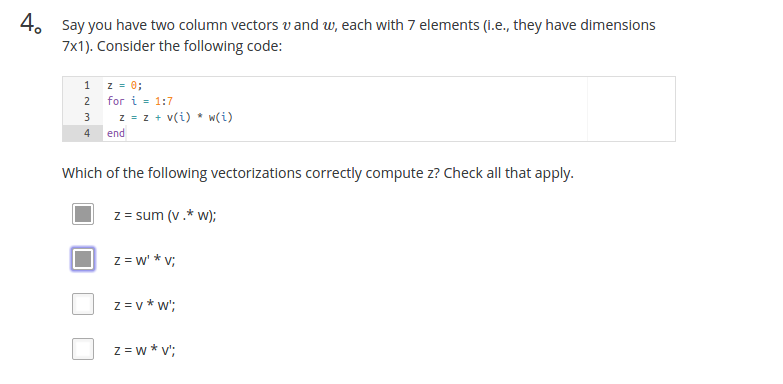
小结测试题5
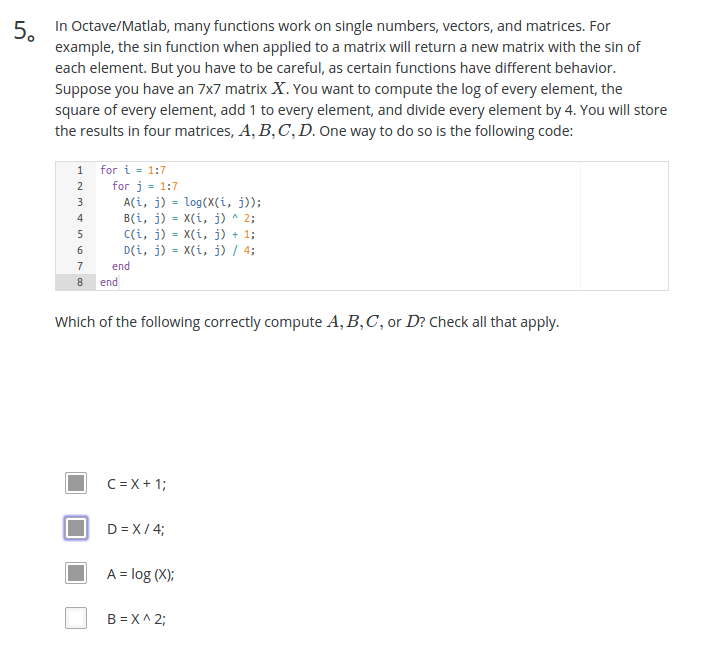
解析
对于数值运算(即二者不同时为矩阵)./与/是一回事。如:
>> a=[1 2;3 4]; >> b=[1 2;3 4]; >> a/b ans = 1 0 0 1 >> a./b ans = 1 1 1 1
a/b相当于a乘b的逆,a./b是a的每个元素与b的每个元素对应相除。
>> a=[1 2 3 4 5]; >> b=3; >> a./b >> a/b
这种情况下,结果就是一样的。

相关文章推荐
- [置顶] 机器学习笔记week3(Andrew NG)
- [置顶] 机器学习笔记week4(Andrew NG)
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 4——神经网络(一)
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 6(一)—— 机器学习诊断、偏差与方差
- Andrew NG 机器学习 笔记-week3-逻辑回归
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 9(二)——推荐系统作业
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 1——简单的线性回归模型和梯度下降
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 8(一)——无监督学习
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 7——支持向量机
- Andrew NG 机器学习 笔记-week1-单变量线性回归
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 3——逻辑回归、过拟合与正则化
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 6(二)——误差分析与数据集偏斜处理
- Andrew Ng机器学习笔记week8 无监督学习(聚类、PCA)
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 5——神经网络(二)
- [置顶] 机器学习笔记week5(Andrew NG)
- Andrew NG 机器学习 笔记-week2-多变量线性回归
- Coursera 机器学习(by Andrew Ng)课程学习笔记 Week 8(二)——降维
- Stanford机器学习课程(Andrew Ng) Week 1 Parameter Learning --- 梯度下降法
- Andrew Ng 机器学习 第一课 监督学习应用.梯度下降 笔记
- 《机器学习》(Machine Learning)——Andrew Ng 斯坦福大学公开课学习笔记(一)