3.1、Spark核心概念——RDD概述
2017-03-09 15:17
260 查看
总结:
Spark-RDD创建过程:
1、创建一个 SparkConf 对象 sc
2、通过 SparkConf 对象创建一个 SparkContext 对象
3、通过 SparkContext 对象创建一个 RDD 对象
4、通过 RDD 对象来操作数据
一、Spark应用的运行方式
1、每个 Spark 应用都由一个驱动器程序( driver program)来发起集群上的各种并行操作,驱动器程序包含应用的 main 函数,并且定义了集群上的分布式数据集;
2、驱动器程序通过一个 SparkContext 对象来访问 Spark,这个对象代表对计算集群的一个连接
shell 启动时已经自动创建了一个 SparkContext 对象,是一个叫作 sc 的变量;
3、一旦有了 SparkContext,你就可以用它来创建 RDD,例如,我们可以调用sc.textFile() 来创建一个代表文件中各行文本的 RDD。我们可以在这些行上进行各种操作,比如 count()。要执行这些操作,驱动器程序一般要管理多个执行器( executor)节点。比如,如果我们在集群上运行 count() 操作,那么不同的节点会统计文件的不同部分的行数。最后,我们有很多用来传递函数的 API,可以将对应操作运行在集群上,比如,筛选出文件中包含某个特定单词的行;
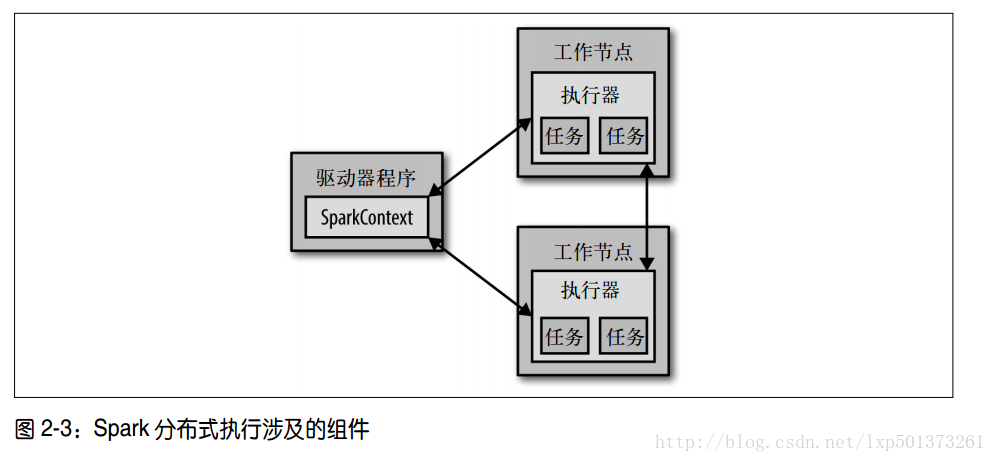
4、Spark API 最神奇的地方,就在于像 filter 这样基于函数的操作也会在集群上并行执行。也就是说, Spark 会自动将函数(比如 line.contains(“Python”))发到各个执行器节点上。这样,你就可以在单一的驱动器程序中编程,并且让代码自动运行在多个节点上。
5、Spark 也可以在 Java、 Scala 或 Python 的独立程序中被连接使用。这与在 shell 中使用的主要区别在于你需要自行初始化 SparkContext。接下来,使用的 API 就一样了。在 Python 中, 你可以把应用写成 Python 脚本,但是需要使用 Spark 自带的 bin/sparksubmit 脚本来运行。 spark-submit 脚本会帮我们引入 Python 程序的 Spark 依赖。这个脚本为 Spark 的 PythonAPI 配置好了运行环境;
6、一旦完成了应用与 Spark 的连接,接下来就需要在你的程序中导入 Spark 包并且创建SparkContext。你可以通过先创建一个 SparkConf 对象来配置你的应用,然后基于这个
SparkConf 创建一个 SparkContext 对象。
示例代码:
def main():
conf = SparkConf().setMaster(“localhost”).setAppName(“My App”)
sc = SparkContext(conf = conf)
lines = sc.textFile(“dd.json”)
print lines.collect()
print lines.count()
if name == ‘main‘:
main()
Spark-RDD创建过程:
1、创建一个 SparkConf 对象 sc
2、通过 SparkConf 对象创建一个 SparkContext 对象
3、通过 SparkContext 对象创建一个 RDD 对象
4、通过 RDD 对象来操作数据
一、Spark应用的运行方式
1、每个 Spark 应用都由一个驱动器程序( driver program)来发起集群上的各种并行操作,驱动器程序包含应用的 main 函数,并且定义了集群上的分布式数据集;
2、驱动器程序通过一个 SparkContext 对象来访问 Spark,这个对象代表对计算集群的一个连接
shell 启动时已经自动创建了一个 SparkContext 对象,是一个叫作 sc 的变量;
3、一旦有了 SparkContext,你就可以用它来创建 RDD,例如,我们可以调用sc.textFile() 来创建一个代表文件中各行文本的 RDD。我们可以在这些行上进行各种操作,比如 count()。要执行这些操作,驱动器程序一般要管理多个执行器( executor)节点。比如,如果我们在集群上运行 count() 操作,那么不同的节点会统计文件的不同部分的行数。最后,我们有很多用来传递函数的 API,可以将对应操作运行在集群上,比如,筛选出文件中包含某个特定单词的行;
4、Spark API 最神奇的地方,就在于像 filter 这样基于函数的操作也会在集群上并行执行。也就是说, Spark 会自动将函数(比如 line.contains(“Python”))发到各个执行器节点上。这样,你就可以在单一的驱动器程序中编程,并且让代码自动运行在多个节点上。
5、Spark 也可以在 Java、 Scala 或 Python 的独立程序中被连接使用。这与在 shell 中使用的主要区别在于你需要自行初始化 SparkContext。接下来,使用的 API 就一样了。在 Python 中, 你可以把应用写成 Python 脚本,但是需要使用 Spark 自带的 bin/sparksubmit 脚本来运行。 spark-submit 脚本会帮我们引入 Python 程序的 Spark 依赖。这个脚本为 Spark 的 PythonAPI 配置好了运行环境;
6、一旦完成了应用与 Spark 的连接,接下来就需要在你的程序中导入 Spark 包并且创建SparkContext。你可以通过先创建一个 SparkConf 对象来配置你的应用,然后基于这个
SparkConf 创建一个 SparkContext 对象。
示例代码:
!/user/bin/python
-*- coding=utf-8
from pyspark import SparkContext,SparkConfdef main():
conf = SparkConf().setMaster(“localhost”).setAppName(“My App”)
sc = SparkContext(conf = conf)
lines = sc.textFile(“dd.json”)
print lines.collect()
print lines.count()
if name == ‘main‘:
main()

相关文章推荐
- Spark的核心概念——RDD
- 深入理解Spark(一):Spark核心概念RDD
- Spark由浅到深(2)-- 了解核心概念RDD
- Spark2.x学习笔记:3、 Spark核心概念RDD
- Spark 核心概念 RDD 详解
- Spark核心概念之RDD
- Spark RDD 核心总结
- 理解Spark的核心RDD
- 【概念、概述】Spark入门教程[1]
- 理解Spark的核心RDD
- Spark核心编程:RDD持久化详解
- spark源码阅读笔记RDD(一)RDD的基本概念
- “戏”说Spark-Spark核心-RDD转换操作算子详解(一)
- Spark核心概念理解
- Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
- Spark核心概念
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
- 《Spark大数据分析:核心概念、技术及实践》大数据技术一览
- Spark Streaming 教程文档--概述、基本概念、性能调优
- Spark 核心 RDD 剖析