你都怎样看知乎日报?
2017-03-07 00:00
190 查看
摘要: 用爬虫把知乎日报都趴下来,异常的爽,,早起写爬虫!!!
所需库第三方:requests
1.分析知乎日报网页(http://daily.zhihu.com/)
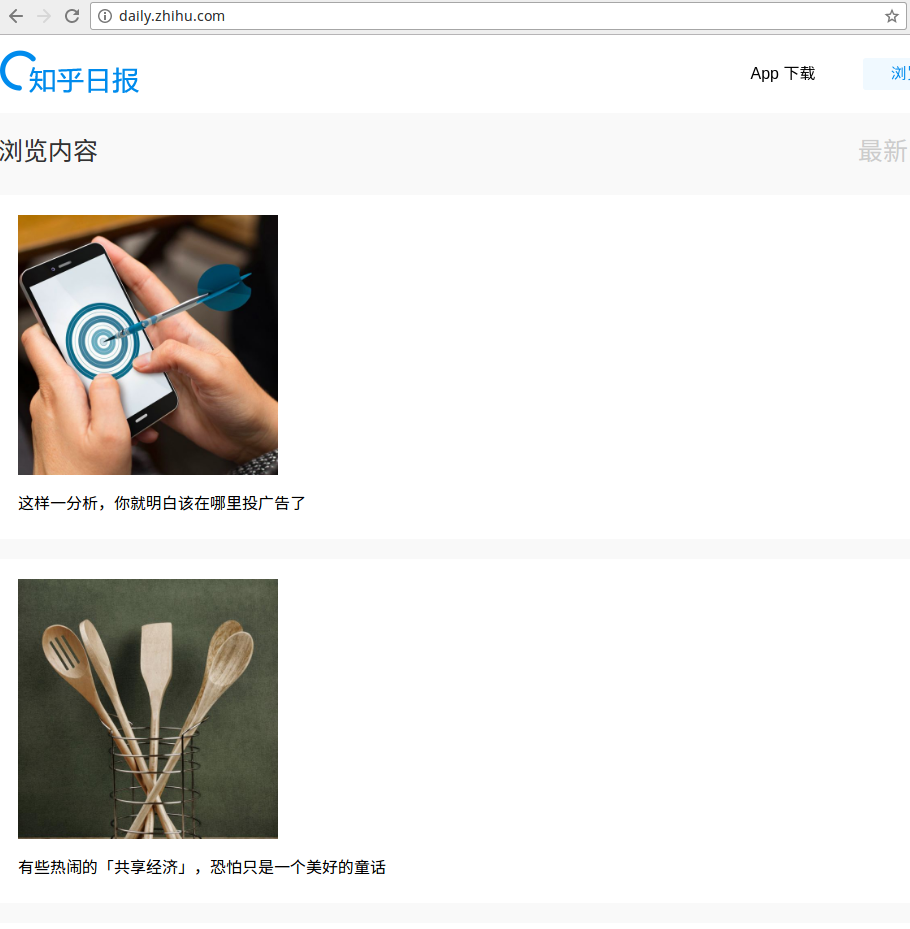
<span class="title">这样一分析,你就明白该在哪里投广告了</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9269183" class="link-button"><img src="http://pic2.zhimg.com/05c67496e38f662958a141847a734ffd.jpg" class="preview-image"><span class="title">有些热闹的「共享经济」,恐怕只是一个美好的童话</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9268452" class="link-button"><img src="http://pic3.zhimg.com/da8d8d3bf282170379c51ea0cf1ae4a6.jpg" class="preview-image"><span class="title">让孩子拥有属于自己的无聊时光,到底有多重要?</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9269792" class="link-button"><img src="http://pic2.zhimg.com/245f3cf8dd4bfdd1bf0911ba4b486295.jpg" class="preview-image"><span class="title">看不懂,说人话,不然公司就亏大发了</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9269818" class="link-button"><img src="http://pic3.zhimg.com/8b1588e23187bb05d160d599bbfe1752.jpg" class="preview-image"><span class="title">《金刚狼 3》中有哪些隐藏的彩蛋和有趣的细节?</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9266807" class="link-button"><img src="http://pic1.zhimg.com/4cb4d5dec4a68553e41dcbd483010e84.jpg" class="preview-image"><span class="title">瞎扯 · 如何正确地吐槽</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9259222" class="link-button"><img src="http://pic4.zhimg.com/16378a8129349aface9694cd27c71e2f.jpg" class="preview-image"><span class="title">小事 · 爱无能</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9267167" class="link-button"><img src="http://pic1.zhimg.com/fdf5e0ff47de69d615f706559a260168.jpg" class="preview-image">
每一个话题和图片都在一个span标签里
<span class="title">这样一分析,你就明白该在哪里投广告了</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9269183" class="link-button"><img src="http://pic2.zhimg.com/05c67496e38f662958a141847a734ffd.jpg" class="preview-image">
很简单构造一个正则表达式去匹配上面(获取标题,图片,链接)
2.下载页面匹配正则表达式
先创建一个请求头
使用下载页面使用正则匹配
3.使用多线程下载图片
4.结果

全部代码:
项目地址:https://git.oschina.net/nanxun/zhihuribao
所需库第三方:requests
1.分析知乎日报网页(http://daily.zhihu.com/)
<span class="title">这样一分析,你就明白该在哪里投广告了</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9269183" class="link-button"><img src="http://pic2.zhimg.com/05c67496e38f662958a141847a734ffd.jpg" class="preview-image"><span class="title">有些热闹的「共享经济」,恐怕只是一个美好的童话</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9268452" class="link-button"><img src="http://pic3.zhimg.com/da8d8d3bf282170379c51ea0cf1ae4a6.jpg" class="preview-image"><span class="title">让孩子拥有属于自己的无聊时光,到底有多重要?</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9269792" class="link-button"><img src="http://pic2.zhimg.com/245f3cf8dd4bfdd1bf0911ba4b486295.jpg" class="preview-image"><span class="title">看不懂,说人话,不然公司就亏大发了</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9269818" class="link-button"><img src="http://pic3.zhimg.com/8b1588e23187bb05d160d599bbfe1752.jpg" class="preview-image"><span class="title">《金刚狼 3》中有哪些隐藏的彩蛋和有趣的细节?</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9266807" class="link-button"><img src="http://pic1.zhimg.com/4cb4d5dec4a68553e41dcbd483010e84.jpg" class="preview-image"><span class="title">瞎扯 · 如何正确地吐槽</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9259222" class="link-button"><img src="http://pic4.zhimg.com/16378a8129349aface9694cd27c71e2f.jpg" class="preview-image"><span class="title">小事 · 爱无能</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9267167" class="link-button"><img src="http://pic1.zhimg.com/fdf5e0ff47de69d615f706559a260168.jpg" class="preview-image">
每一个话题和图片都在一个span标签里
<span class="title">这样一分析,你就明白该在哪里投广告了</span></a></div></div><div class="wrap"><div class="box"><a href="/story/9269183" class="link-button"><img src="http://pic2.zhimg.com/05c67496e38f662958a141847a734ffd.jpg" class="preview-image">
很简单构造一个正则表达式去匹配上面(获取标题,图片,链接)
pattern=re.compile(u'<span class="title">(.*?)</span>.*?'+ u'<a href="(.*?)".*?'+ u'<img src="(.*?)".*?' ,re.S)
2.下载页面匹配正则表达式
先创建一个请求头
self.header={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Host':'daily.zhihu.com',
'Referer':'https://www.baidu.com/link?url=Eh6CKs72Buyf0LEjPd1795QSL8ZK74kwItBvzaybausT6proAZIr3UkkmMPSDfk7&wd=&eqid=d1bd8fd9004118c90000000258bd8149',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/56.0.2924.76 Chrome/56.0.2924.76 Safari/537.36'
}使用下载页面使用正则匹配
html=self.req.get(url=self.url,headers=self.header)
pattern=re.compile(u'<span class="title">(.*?)</span>.*?'+ u'<a href="(.*?)".*?'+ u'<img src="(.*?)".*?' ,re.S)
T=list()
self.l=re.findall(pattern,html.text)
3.使用多线程下载图片
T=list() self.l=re.findall(pattern,html.text) for i in self.l: self.w.write(str(i)+'\n') #if(self.n<29): t=Thread(target=self.getimg,args=(i[2],self.n)) #self.getimg(i[2],self.n) T.append(t) t.start() #print(i) self.n+=1 #time.sleep(1) for tt in T: tt.join()
def getimg(self,src,n):
try:
h=self.req.get(url=src)
s=open(str(n)+'.jpg','wb')
s.write(h.content)
s.close()
except requests.exceptions.MissingSchema:
print('这个url无效',n)4.结果
全部代码:
#!/usr/bin/python3
#coding:utf8
import requests
import re
import time
from threading import Thread
class main(object):
def __init__(self):
self.url='http://daily.zhihu.com/'
self.l=list()
self.n=0
self.req=requests.Session()
self.header={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Host':'daily.zhihu.com',
'Referer':'https://www.baidu.com/link?url=Eh6CKs72Buyf0LEjPd1795QSL8ZK74kwItBvzaybausT6proAZIr3UkkmMPSDfk7&wd=&eqid=d1bd8fd9004118c90000000258bd8149',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/56.0.2924.76 Chrome/56.0.2924.76 Safari/537.36'
}
def getpage(self):
html=self.req.get(url=self.url,headers=self.header)
pattern=re.compile(u'<span class="title">(.*?)</span>.*?'+ u'<a href="(.*?)".*?'+ u'<img src="(.*?)".*?' ,re.S)
T=list() self.l=re.findall(pattern,html.text) for i in self.l: self.w.write(str(i)+'\n') #if(self.n<29): t=Thread(target=self.getimg,args=(i[2],self.n)) #self.getimg(i[2],self.n) T.append(t) t.start() #print(i) self.n+=1 #time.sleep(1) for tt in T: tt.join()
def getimg(self,src,n): try: h=self.req.get(url=src) s=open(str(n)+'.jpg','wb') s.write(h.content) s.close() except requests.exceptions.MissingSchema: print('这个url无效',n)
if __name__=='__main__':
p=main()
p.w=open('zh.txt','w')
p.getpage()
p.w.close()
项目地址:https://git.oschina.net/nanxun/zhihuribao

相关文章推荐
- Java UI 是怎样演变的以及它的前景如何?
- making an os NO.1 怎样进内核之一
- 工作室需要怎样的一款代答软件
- 怎样提交FIREDAC数据集的DELTA到中间件然后保存进数据库
- 知乎日报:她把全世界的学术期刊都黑了
- ROS探索总结(十九)——怎样配置机器人的导航功能
- 怎样建RAID5阵列
- (转)怎样让两台笔记本联网,并能共享上网冲浪
- 伟大的程序员是怎样炼成的?
- 怎样才是理想的程序员
- [Unity&C#&接口]接口怎样运用到游戏当中
- 在Jboss中怎样快速布署一个WEB应用开发或测试环境
- 怎样写 Linux LCD 驱动程序
- jquery叫你怎样对图层进行隐藏和现实 一行代码超简单
- 怎样在编译时不显示警告
- 怎样通过MindMapper 16在模板中新建导图
- android 怎样将主菜单图标改成按安装时间排序
- 怎样才能去掉MFC单文档中的“无标题”字样?
- 如果数据库处于归档模式但自动归档功能没有开启会产生什么后果呢,产生这种情况后又怎样解决呢?