机器学习-3 cost function 代价函数
2017-02-24 09:25
302 查看
1、代价函数简介
代价函数是用来衡量假设函数(hypothesis function)的准确性,具体衡量指标是采用平方差的方式计算。例如,假设函数是 hθ(xi) = θ0 + θ1yi,那么,代价函数就是: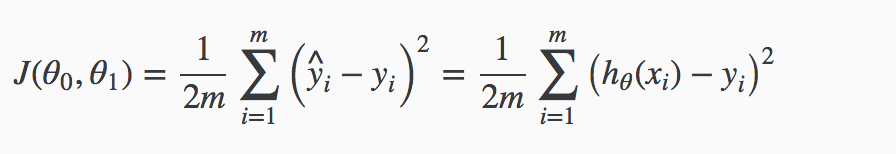
其中,m是样本数量。同时,这个函数还可以称为"Squared error function" 或者 "Mean squared error”,同时,除以2的原因是为了方便之后的梯度下降,也利于导数项的减少。
下面这幅图片更加直观的表达代价函数的由来:

2、代价函数详述
2.1 单变量情况
为了更加直观的理解代价函数,我们还是以线性的训练集为例子。训练集落在x-y坐标集中,在这个回归问题中,我们想生成一个假设函数,这个假设函数生成一个直线,可以大致贯穿给定的训练集。我们的目标就是获取一个尽可能完美的直线。最好的直线,就是使我们的预估值与样本值之间的方差最小。理想情况下,直线穿过所有的训练样本集,也就是说方差等于0,也就是 代价函数J(θ0,θ1)等于0。下面的例子,就是理想情况:
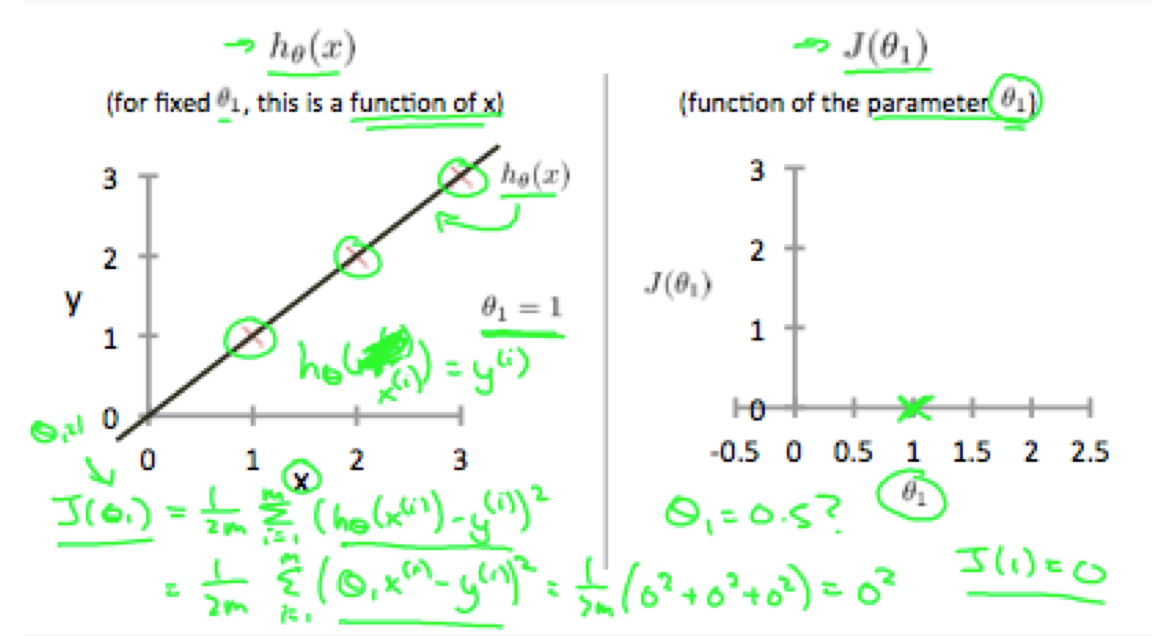
当 θ1=1 的时候,我们的模型贯穿所有的训练样本集的点,相比之下,当θ1=0.5的时候,模型的直线距离样本集的点的垂直距离会加大,如下图:
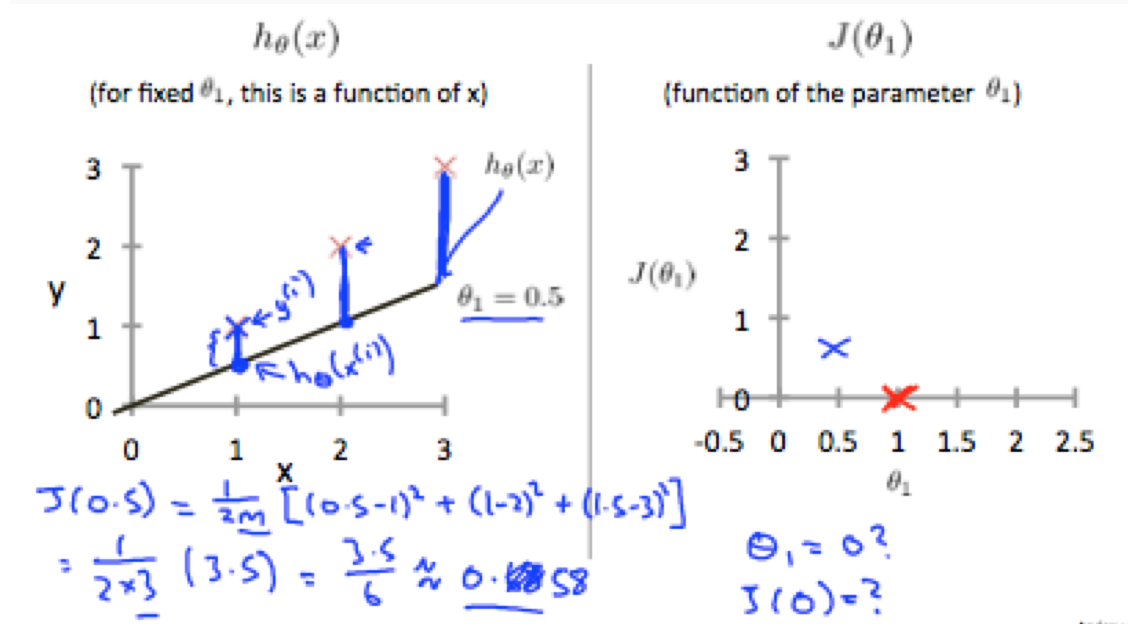
在不断调整θ1的值之后,我们发现,在代价函数的图中会生成一个曲线图:
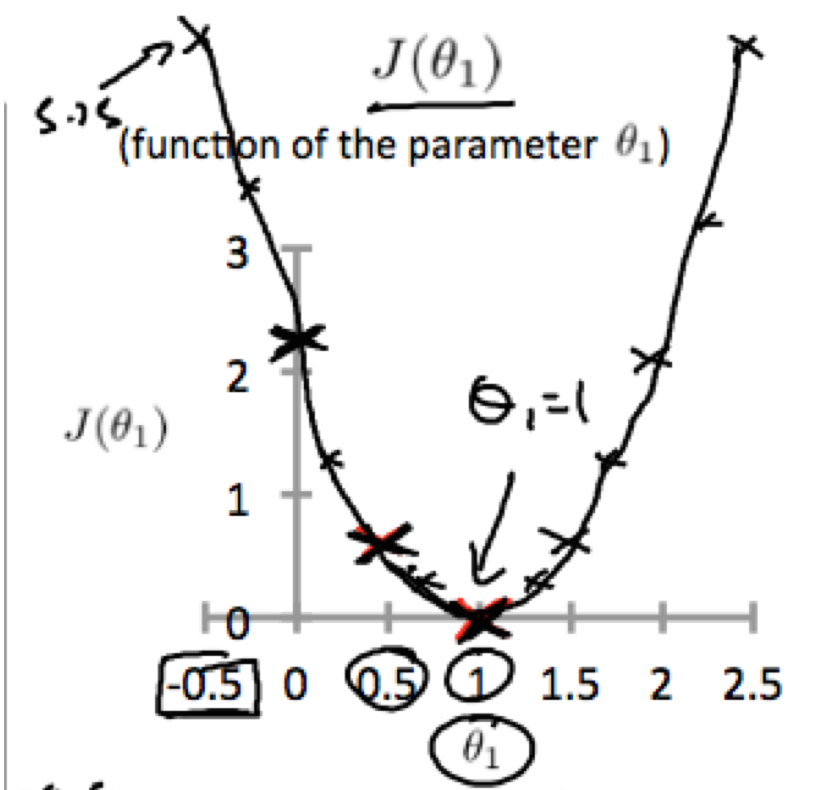
为了使J(0,θ1) 最小,从图中,就可以看出,应该取θ1作为目标值。
2.2 双变量情况
在2.1 中具体阐述了单变量的代价函数的具体情况,这一小节具体阐述一下双变量的代价函数设计的相关概念。在双变量的代价函数中,使用等高线图描述代价函数的变化,每个等高线代表相同的J(θ0,θ1)值,但是对应的(θ0,θ1)不一定一样,如下图: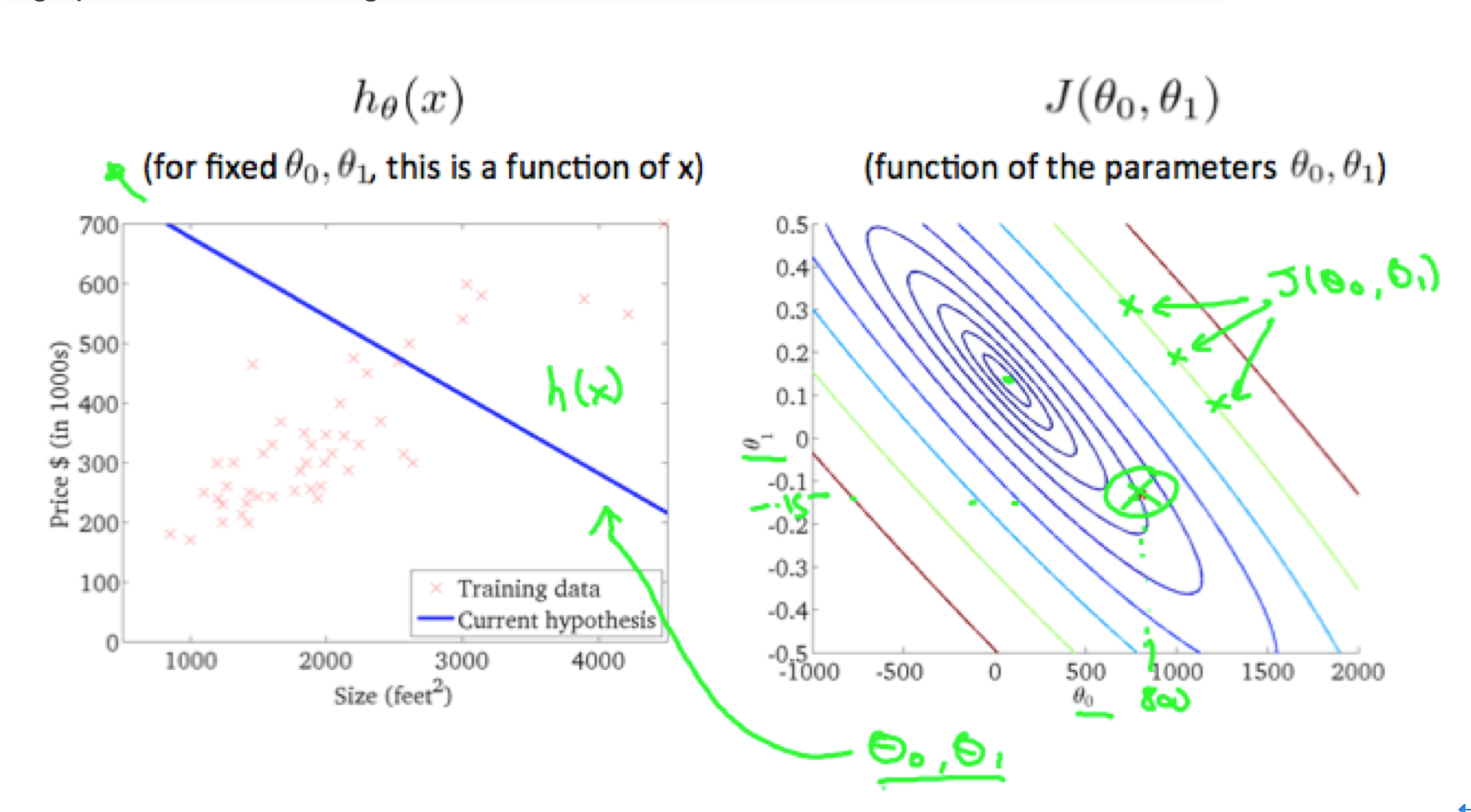
在比如:
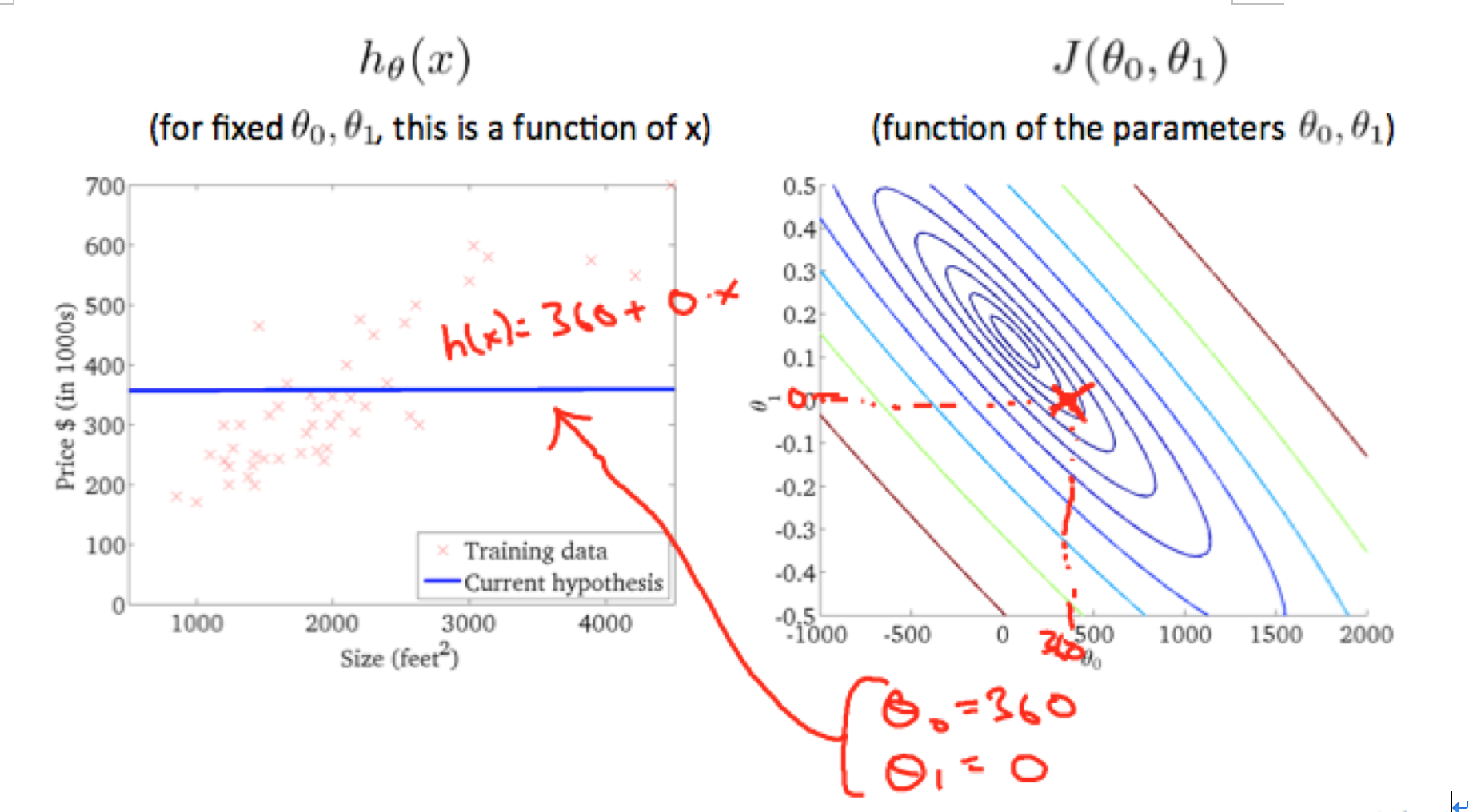
当 θ0 = 360,θ1 = 0, J(θ0,θ1)的值距离圆心更近,同时,模型的直线更加拟合样本集。
继续调整(θ0,θ1)的值,更加靠近圆心,发现,模型的直线更加拟合样本集,如下图:
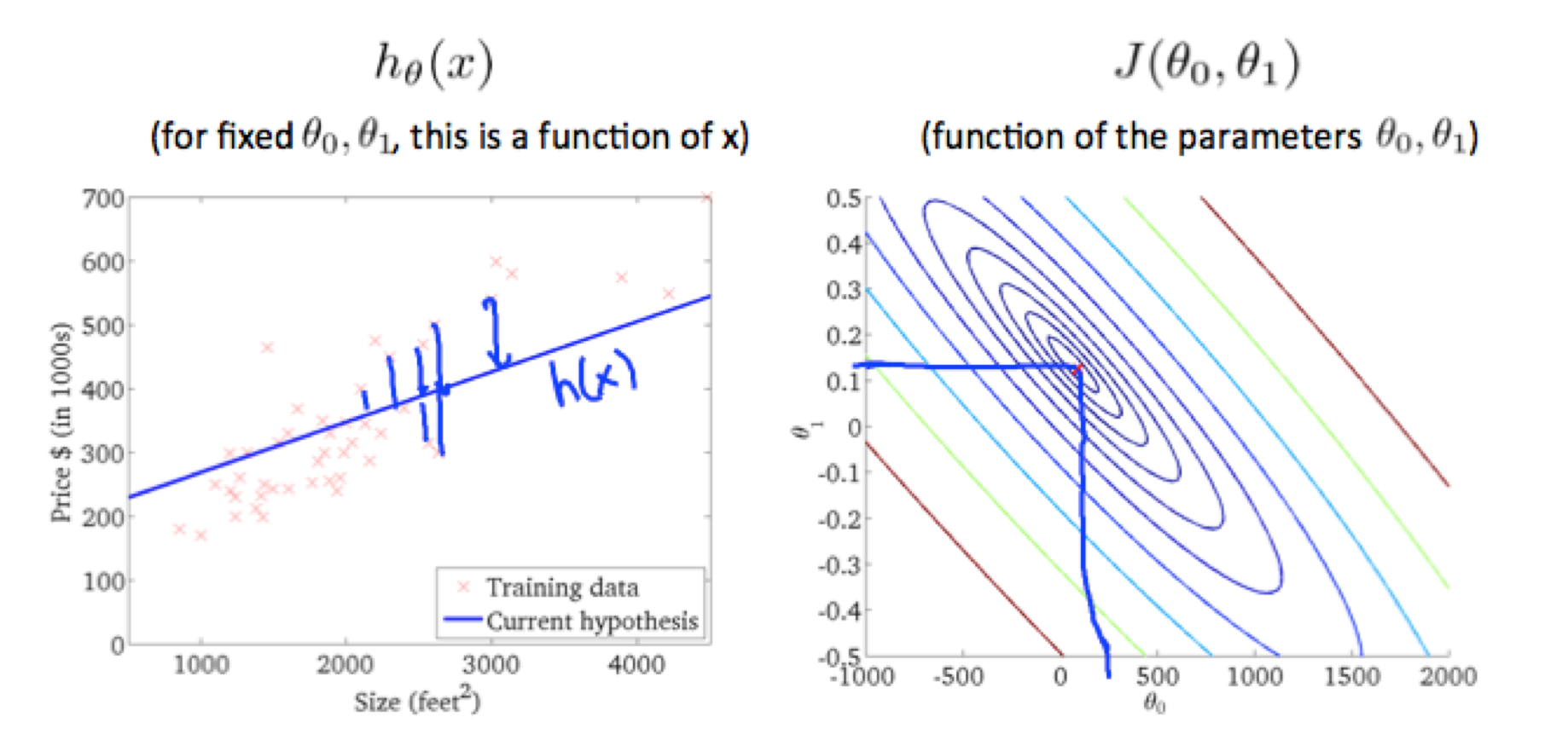
为了尽可能的降低J(θ0,θ1)的值,我们发现 θ1, θ0的值大概在(0.12,250)附近。由此可以看出,当在圆心的时候,应该是最佳的选值,以上就是cost function的一些概念。
欢迎大家关注:数据之下 微信公众号,系统性的分享机器学习、深度学习等方面的知识,不做碎片化学习的牺牲者,要做利用好碎片化时间的受益者。


相关文章推荐
- 【机器学习】代价函数(cost function)
- 机器学习之代价函数(cost function)
- [机器学习] 代价函数(cost function)
- 机器学习:代价函数cost function
- 机器学习中代价函数选择的数学推导
- 机器学习-代价函数
- 机器学习中的代价函数
- 第一周-机器学习-代价函数_intuition
- 机器学习之建模与代价函数
- 机器学习笔记之代价函数(三)
- [机器学习2]模型与代价函数
- 机器学习-逻辑回归-代价函数
- Machine Learning(Stanford)| 斯坦福大学机器学习笔记--第一周(3.代价函数直观理解)
- 损失函数(Loss function)和代价函数(成本函数)(Cost function)的区别与联系
- 机器学习-梯度下降III(为何梯度下降能最小化代价函数)
- 【机器学习入门】Andrew NG《Machine Learning》课程笔记之二 :基本概念、代价函数、梯度下降和线性回归
- 机器学习入门(4)--代价函数
- 机器学习笔记之代价函数
- 《机器学习》第一周 一元回归法 | 模型和代价函数,梯度下降
- 机器学习笔记02-代价函数与梯度下降算法(一)