R语言实现简单的网页数据抓取
2017-02-17 23:39
337 查看
在知乎遇到这样一个问题。
https://www.zhihu.com/question/26385408/answer/147009602
这是要爬取的内容的网页:
R语言的代码的实现方式如下:
我们还可以保存为其他格式:
https://www.zhihu.com/question/26385408/answer/147009602
这是要爬取的内容的网页:
R语言的代码的实现方式如下:
#安装XML包
>install.packages("XML")
#载入XML包
> library(XML)
#确定网页地址,通过网页地址分析网页表格
> url<-"http://hz.house.ifeng.com/detail/2014_10_28/50087618_1.shtml"
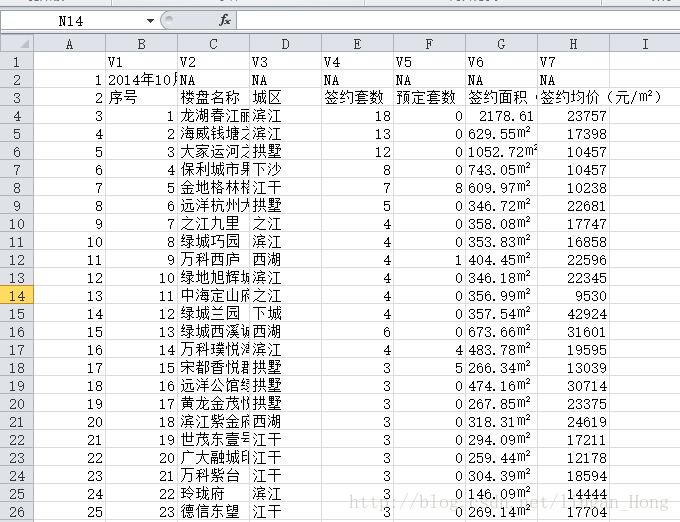
> tbls<-readHTMLTable(url)
> sapply(tbls,nrow)
NULL NULL
93 8
#读取网页url的第一张表
> pop<-readHTMLTable(url,which = 1)
#存储pop为CSV文档
> write.csv(pop,file="F:/pop.csv")我们还可以保存为其他格式:
#保存为简单文本: >write.table(x, file = "*.txt") #保存为R格式文件: >save(x, file = "*.Rdata")

相关文章推荐
- java简单实现爬虫、jsoup实现网页抓取、POI实现数据导出Excel
- 利用Java实现简单的抓取网页数据并存放于plist中
- 利用iframe实现ajax跨域请求,抓取网页中ajax数据
- 实现从网页上抓取数据(htmlparser)
- php 网页数据抓取 简单实例
- htmlparser实现从网页上抓取数据
- HttpClient+jsoup实现网页数据抓取和处理
- PHP实现简单爬虫-抓取网页url
- 实现从网页上抓取数据(htmlparser)
- 【工作笔记0006】C#调用HtmlAgilityPack类库实现网页数据抓取
- 用python进行分布式网页数据抓取(三)—— 编码实现
- 使用R语言和XML包抓取网页数据-Scraping data from web pages in R with XML package
- 简单的java爬虫抓取网页实现代码(未测试)
- Java简单的抓取网页数据
- c#关于网页内容抓取,简单爬虫的实现。(包括动态,静态的)
- Java实现简单网页抓取
- 网页实现从数据库读取数据并简单分页
- 网页爬虫抓取URL简单实现
- java简单网页抓取的实现方法
- htmlparser实现从网页上抓取数据