新闻内容去重算法simhash实践
2017-02-16 18:50
190 查看
前言
最近做了新闻去重算法的工作,mark下两个应用场景:1. 重复新闻整体检测、去重 2. 从非重复的新闻中寻找重复的句子,依次判断两篇新闻是否存在同一个话题的不同观点(多方观点提取)
本人不负责爬虫,爬虫的同事只做了简单的新闻title重复的检测、去重。 我提供内容的检测算法
一 通用网页去重算法框架

二 simhash算法
简单一查网页去重,就知道google的simhash算法。 来自于GoogleMoses Charikar发表的一篇论文“detectingnear-duplicates for web crawling”中提出了simhash算法,专门用来解决亿万级别的网页的去重任务。
simhash作为locality sensitive hash(局部敏感哈希)的一种
流程
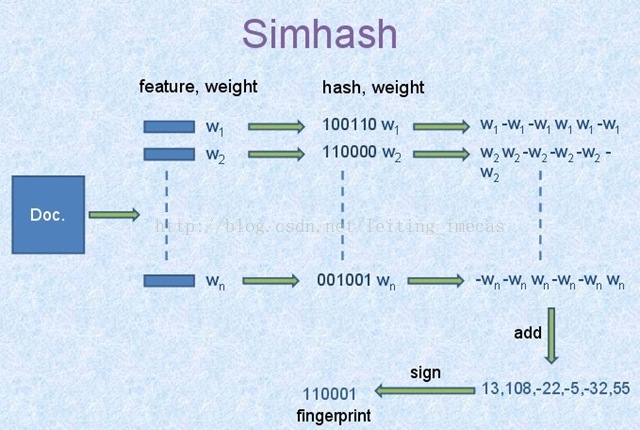
simhash算法分为5个步骤:分词、hash、加权、合并、降维,具体过程如下所述:
分词
给定一段语句,进行分词,得到有效的特征向量,然后为每一个特征向量设置1-5等5个级别的权重(如果是给定一个文本,那么特征向量可以是文本中的词,其权重可以是这个词出现的次数)。例如给定一段语句:“CSDN博客结构之法算法之道的作者July”,分词后为:“CSDN 博客 结构 之 法 算法 之 道 的 作者 July”,然后为每个特征向量赋予权值:CSDN(4) 博客(5) 结构(3) 之(1) 法(2) 算法(3) 之(1) 道(2) 的(1) 作者(5)
July(5),其中括号里的数字代表这个单词在整条语句中的重要程度,数字越大代表越重要。
hash
通过hash函数计算各个特征向量的hash值,hash值为二进制数01组成的n-bit签名。比如“CSDN”的hash值Hash(CSDN)为100101,“博客”的hash值Hash(博客)为“101011”。就这样,字符串就变成了一系列数字。
加权
在hash值的基础上,给所有特征向量进行加权,即W = Hash * weight,且遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘。例如给“CSDN”的hash值“100101”加权得到:W(CSDN) = 100101 4 = 4 -4 -4 4 -4 4,给“博客”的hash值“101011”加权得到:W(博客)=101011 5 = 5 -5 5 -5 5 5,其余特征向量类似此般操作。
合并
将上述各个特征向量的加权结果累加,变成只有一个序列串。拿前两个特征向量举例,例如“CSDN”的“4 -4 -4 4 -4 4”和“博客”的“5 -5 5 -5 5 5”进行累加,得到“4+5 -4+-5 -4+5 4+-5 -4+5 4+5”,得到“9 -9 1 -1 1”。
降维
对于n-bit签名的累加结果,如果大于0则置1,否则置0,从而得到该语句的simhash值,最后我们便可以根据不同语句simhash的海明距离来判断它们的相似度。例如把上面计算出来的“9 -9 1 -1 1 9”降维(某位大于0记为1,小于0记为0),得到的01串为:“1 0 1 0 1 1”,从而形成它们的simhash签名。
流程图:
>>> bin(2305843056189898754) '0b10000000000000000000000000101011110000000000000000000000000010' >>> bin(2305843034715062278) '0b10000000000000000000000000010111110000000000000000000000000110' >>> 2305843056189898754 & 2305843034715062278 2305843013240225794 >>> bin(2305843013240225794) '0b10000000000000000000000000000011110000000000000000000000000010' >>> 所以2305843056189898754和2305843034715062278的海明距离为6
三 建立索引
在处理新闻重复检测时,由于我们只取两天内的新闻做比较,数据量小,所以直接采用了遍历的方法。但实现多放观点的算法时需要查询以往的所有新闻,高效的搜索是必须的。
四 要点说明
要点1. 我们采用了谷歌的索引策略,将64位分4段。最初按照顺序取16,16,16,16,但是发现第一个16位存在大量相等的情况,第二个16位也存在不小的重复。所以调整了分段办法,如下:
fir = hash_bits & 0b11000000000000000000000000111111110000000000000000000000001111 sec = hash_bits & 0b00111100000000000000001111000000001111000000000000000011110000 thi = hash_bits & 0b00000011110000000011110000000000000000111100000000111100000000 fou = hash_bits & 0b00000000001111111100000000000000000000000011111111000000000000实际应用中,因为使用了数据库的索引,为了可以进一步缩小范围,项目中还另外建立了4段:fir2, sec2, thi2, fou2,这四段使用不同的
取位方法。这样满足条件的句子必定满足:前四段至少一个相同并且后四段至少一个相同。 这样可以极大的缩小有效氛围。
要点2. 在数据库冲存放了四段的字段,利用数据库的索引而不用自己建索引
要点3. 涉及到句子的simhash,短文本simhash不是十分准确,测试效果来看,去除停用词、特殊词性的词后效果
明显提升。 可以参考http://www.cnblogs.com/zhengyun_ustc/archive/2012/06/12/sim.html
要点4. 由索引找到hash值上相似的句子后,为了避免hash策略可能带来的冲突问题,可以直接使用cos距离或者直接
判断相同词比例来更精确的判断两个句子是否相等。 我采用了后一种方法。
还可以自建hash索引http://www.lanceyan.com/tech/arch/simhash_hamming_distance_similarity2-html.html, 消耗内存
五 去重策略------后补充
前面讲的主要是simhash算法,用于检测相同的文本。那重复的新闻如何选择丢掉哪一篇呢? 实际项目中,需要考虑的是新闻的评分机制,正在进行,初步选定LR来做,等项目
完成再做补充

相关文章推荐
- [新闻资讯] Flex开发指南---创建用户体验的工作流程和最佳实践
- js类似新闻图片轮换(带有文字介绍,其实可以放任何内容)
- 新闻标题太长加省略号和对内容太长分页
- 《Windows Server 2012活动目录管理实践》 内容提要、前言
- [转]php初级教程(九)添加新闻内容程序的编写
- js+div控制新闻内容分页【转】
- 碎片的最佳实践——一个简易版的新闻应用
- 新闻内容展示
- 【安卓学习】4.碎片(Fragment)实践---一个简单的新闻应用。
- 20145209 2016-2017-2 《Java程序设计》课堂实践内容
- DEDECMS首页获取新闻内容
- iOS界面-仿网易新闻左侧抽屉式交互 续(添加新闻内容页和评论页手势)
- 基于BeautifulSoup抓取网站内容的实践(Kanunu8)(1)
- 基于Android小巫新闻客户端开发---显示新闻详细内容UI设计
- Extjs4 get getCmp getDom实践 动态修改tbar内容
- 新闻内容中对关键词添加连接
- 新闻内容入库前过滤
- 新闻客户端的新闻内容图文混排
- 一步步打造漂亮的新闻列表(无刷新分页、内容预览)(1)
- asp如何读取新闻内容中的N张图片地址(转载)