CYQ.Data V5 分布式缓存Redis应用开发及实现算法原理介绍
2017-02-14 18:00
309 查看
前言:
自从CYQ.Data框架出了数据库读写分离、分布式缓存MemCache、自动缓存等大功能之后,就进入了频繁的细节打磨优化阶段。从以下的更新列表就可以看出来了,3个月更新了100条次功能:
前几天,决定把Redis集成进来,一鼓作气,解决了。
下面分享一下经历:
最初的想法:
一开始我是拒绝的,不愿动态调用第三方的客户端(关联依赖的dll太多)。最近打算支持Redis,有点妥协了,动态加载就动态加载了吧:
考虑着引入:StackExchange.Redis或ServiceStack.Redis?
看着这些DLL,太重量级,方法反射起来也费劲!
中间思维停顿了一会。。。
发现轻量级:Bettle.Redis
在寻找Redis的API资料时,无意发现了这个开源的轻量级Bettle.Redis。看到源码编绎后才46K,感觉就是它了。
不过才几刻间,发现了以下几个问题了:
1:自身虽然46K,但代码引用了另外两个3个dll(依赖太多):
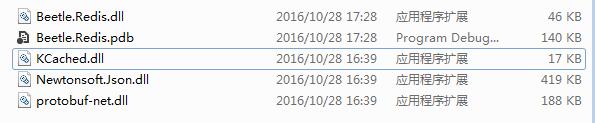
2:使用的方法不符合使用习惯,一个命令类型就对应一个类。

3:不支持集群的水平扩展(没实现支持一致性Hash)。

4:代码是用.NET 4.0 以下版本写的,(CYQ.Data 框架是支持2.0起的,改代码改到我手痛)
所以,以上原因估计是它没被普及的原因,也是最终没有被我选择集成的原因。
但是它开放了源码、对我还是有点启发和参考意义。
Redis API 扫盲:
在决定支持Redis的过程中,花了不少时间扫了Redis的文档:
更多命令详情可以看:http://doc.redisfans.com
从这么一堆的命令中,找到基本命令:Get、Set、Exists、Expire、Info,可怜没有Add。
其它的命令,多数都是可以用基本命令实现的,就被无视了。
经过短时间内大量的集中思考,决定自己实现了:
重新定位的思路:
框架之前已经集成了MemCache,而Redis和MemCache又大同小异。一些共性的东西,可以复用:
1:hash算法。
2:一致性Hash(水平扩展)。
3:SocketPool。
4:ServerPool。
5:序列化(压缩)
剩下的,就是完成Socket和Redis的交互及使用方式。
以下是Redis的协议规范,不过是我实现Redis相关功能后才发现的:
折腾的经过:
Bettle.Redis里有源码,看看实现就可以了,所以没找协议规范:通过几个小时的引进和代码调整,测试。
以为大功告成之际,测试到当Set的数据太大时,NetworkStream报异常:此流不支持Seek操作。
怀疑是Redis的Set有大小限制?:用Bettle.Redis自身试了下,发现正常,梦B了。
经代码调试,发现Bettle的Socket实现(Socket.Send)和Socket池的实现(NetworkStream.Write)不一样。
Bettle.Redis是把所有的协议构造好一次性Socket.Send(byte[])。
怀疑NetworkStream的默认缓存池太小引发的?:用memCache,Set了大量的数据,发现NetworkStream并没有抛异常,又梦B了。
怀疑是Redis协议的问题了?:改造代码,把协议分拆,先发送:$长度 ,再发送数据,发现竟然正常了,无语问苍天了!
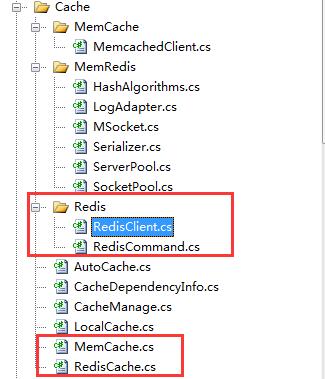
经过一夜一天的折腾,Cache目录下补了4个类,同时进行了算法优化,清掉一些没用的代码。
支持Redis后,发现cyq.data.dll的大小竟然没变化,结果超出了预期,很好!
最后改造成的源码结构是:
完整的源码已经提交在:https://github.com/cyq1162/cyqdata
Redis使用方式:
AppConfig.Cache.RedisServers = "127.0.0.1:6379,127.0.0.1:1121";//配置启用,
AppConfig.Cache.RedisServersBak = "127.0.0.1:6379";//备用配置。
CacheManage cache = CacheManage.RedisInstance;//操作对象
cache.Add("obj", cache.CacheTable);//添加DataTable
MDataTable obj = cache.Get<MDataTable>("obj");
Console.WriteLine(obj.Rows.Count);
Dictionary<string, string> dic = new Dictionary<string, string>();
dic.Add("路过秋天", "http://www.cnblogs.com/cyq1162");
cache.Add("dic", dic);//添加字段
Dictionary<string, string> dicObj = cache.Get<Dictionary<string, string>>("dic");
Console.WriteLine(dicObj["路过秋天"]);
cache.Remove("dic");//移除Dic
bool hasKey = cache.Contains("dic");//检测是否存在
Console.WriteLine(hasKey);
Console.Read();结果:

对于存储类型的改进:
由于Redis的Get只支持字符串,为了达到支持任意类型,我必须改进算法:1:存档:目标是对象时=》进行序列化(对于>128K的会进行压缩)
2:数据的第1个字节:存档数据类型。
3:获取数据时:根据第1个字节,进行准确的数据类型还原。
(aaa是通过命令行Set的,而a0是通过代码设置的,所以多了\x02的类型标识)

因此:框架靠Set与Get能支持任意类型的存取档!
对于分布式算法的改进:
1:对于水平增加节点的扩展:
内部已经实现了一致性Hash算法,因此省了不少工作:简单的描述为:把ip1产生N个hash ,ip2产生N个hash,... 然后排序(最后就看key的hash值离谁最新就粘谁了)
借用一张图表示为:

2:对于节点故障的转移:
在测试的过程中,我填写了一台异常的主机,发现被分配到异常的主机的key的读写都没反应了:(我潜意识默认以为会自动转移到相邻的主机中)
默认的算法:
1:没有自动切换相邻的主机【用思考代码疑问:主动切换可能导致雪崩效应,(累积的压力可能把所有的服务器都搞挂)】。2:有重试连接机制(2分钟试1次)。
改进了算法:增加了一个备份机的配置(AppConfig.Cache.RedisServersBak)
1:根据Hash,每一台主机都会指向一台备份机。 2:主机异常时,由备份机代理服务器15分钟(即每15分检测主机是否正常一次,如果正常,则恢复主机服务)。
3:当主机恢复时,从备份机里恢复数据,并清空备份机的数据(未实现)
由于可能同时挂掉N台,所以备份机可能存档多台主机的信息。
于是算法的思路有3个:
1:数据不要了(主机重新缓存即可) 2:主机被请求时(检测是否挂过,如果是,读自身(若没有)=》读备份机(同时发表移除指令)(若有数据)=》返回(同时写入主机) 3:主机被请求时(检测是否挂过,如果是开启线程(读备份机所有Key,检测Hash是否符合自身,如果是,则从备份读取并写入,同时清除备份机的数据)
总结:
至此,CYQ.Data已经支持上Redis了,而且在分布式算法上,借了memCache的风,以及改进的算法,显的更为实用!当然,细节仍需打磨,代码还可以改的更简洁优美。
在分布式已经泛滥的今天,能正确的判断并用好分布式框架是一种能力的体现。
刚刚群里有人发了这条消息:

其实前面的问题都可以无视,因为最后解决方案他只是把Redis部署从Windows转移到Linux就好了。
QPS最大时听说7万多(两台Web分来就是3万多,大部分是刷票造成的请求)
Redis在Windows上的表现并不如Linux的好,这个可以理解。
但是如果在架构设计方案上稍为调整,其实也毫无压力了。
最后我发现问题的根源不在于技术,在于人:.NET缺少有足够知识和思维的架构师。
不要遇到点问题就力不从心,在.NET的阵营上坚持吧,少年!
 | 版权声明:本文原创发表于 博客园,作者为 路过秋天 本文欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则视为侵权。 |
Donation(扫码支持作者):支付宝: 微信:  |

相关文章推荐
- CYQ.Data V5 分布式缓存Redis应用开发及实现算法原理介绍
- CYQ.Data V5 分布式缓存Redis应用开发及实现算法原理介绍
- html5 俄罗斯方块 ----kinetic 应用开发介绍实现算法 2
- 【Android应用开发】-(19)Android 串口编程原理和实现方式(附源码)
- CYQ.Data V5文本数据库技术原理解密
- Qt Quick应用开发介绍 1-5(介绍_环境_核心原理_元素作为基本_加载和显示)
- 最老程序员开发实训9--Android---应用介绍页面实现1
- 【Android应用开发】-(19)Android 串口编程原理和实现方式
- 带色彩恢复的多尺度视网膜增强算法(MSRCR)的原理、实现及应用
- LBP原理介绍以及算法实现
- Lucas-Kanade算法原理介绍及OpenCV代码实现分析
- JFinal的架构介绍,JFinal实现极速开发的原理是什么?又是如何实现的?
- 带色彩恢复的多尺度视网膜增强算法(MSRCR)的原理、实现及应用。
- 多口短信猫池做二次开发应用实现过程与原理
- CYQ.Data 数据框架 跨平台应用开发
- CYQ.Data V5文本数据库技术原理解密
- CYQ.Data 快速开发之UI(赋值、取值、绑定)原理
- 带色彩恢复的多尺度视网膜增强算法(MSRCR)的原理、实现及应用
- Redis源码中探秘SHA-1算法原理及其编程实现
- 【Android应用开发】-(19)Android 串口编程原理和实现方式(附源码)