hadoop2.6.0伪分布式环境搭建
2017-02-07 00:08
525 查看
Hadoop作为分布式大数据处理框架在数据处理应用中有广泛的应用,本文介绍在Linux环境下搭建hadoop伪分布式集群,记录下自己的学习过程。
一、虚拟机准备,为了减少折腾,不建议在windows上利用cygwin来模拟linux系统,直接利用vmware新建Linux虚拟机,可以减少很多不必要的麻烦,尤其是ssh远程连接、免密钥登录等环节的设置,在虚拟机上几乎不用浪费时间。
以下截图是我安装的机器信息,最好对机器设置静态IP,不用每次重启就重新修改hosts配置文件,另外hosts文件一定要设置。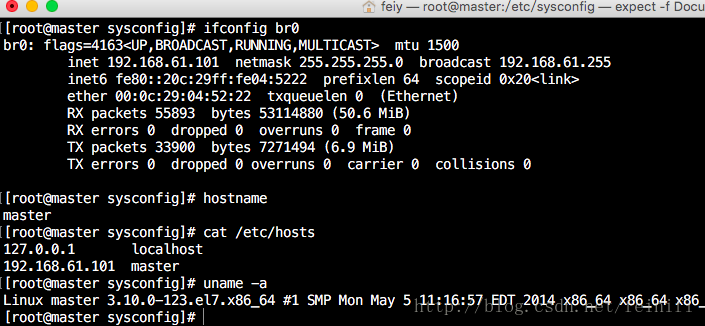
二、配置jdk
hadoop是用java语言写的,需要运行在java虚拟机上,因此需要安装jdk,这里不介绍如何安装jdk,在redhat上可以通过rpm方式安装jdk,也可以在oracle官网直接下载jdk的包,解压到指定位置就可以。另外还需要把jdk的安装路径加入到环境变量。
下图所示是我的linux虚拟机上安装的jdk和设置的环境变量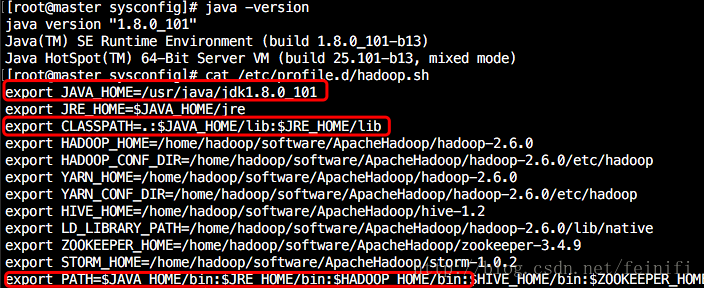
三、配置免密钥登录
默认情况下在redhat系列机器上自动就装上了ssh远程登录服务,因此不用再安装,如果需要可以使用yum install -y ssh-server来安装。ubuntu系统就使用apt-get install openssh-server.接着生成密钥:
ssh-keygen -t rsa
输入该命令后,一路回车,会生成一个id_rsa.pub的文件,生成的密钥会在根目录下的.ssh文件夹下,将id_rsa.put文件拷贝一份为authorized_keys文件,必须要拷贝。
cd ~/.ssh cp id_rsa.pub authorized_keys

之所以要生成密钥,主要是hadoop在启动时会远程登录节点(即使是单机模式和伪分布式模式),如果没有密钥,那么在ssh登录节点时,需要手工输入密码,这一步在单机模式下或着伪分布式模式下可以接受,但是完全分布式部署时机器数量非常大,一个个输入密码会非常麻烦,免密钥登录就是减少了输入密码的步骤,这一步至关重要。
四、配置Hadoop
这里包括Hadoop所在目录的环境变量(见第二步jdk环境配置)和Hadoop本身的配置文件(etc/hadoop目录下)。1)core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/software/ApacheHadoop/hadoop-2.6.0/hdfs/name</value> </property> </configuration>
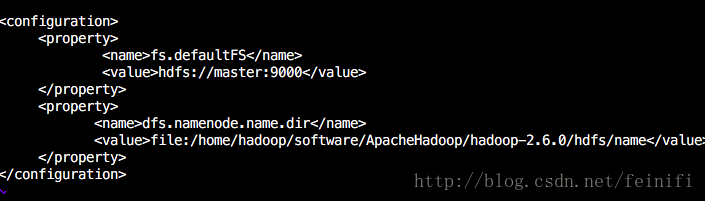
2)hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/software/ApacheHadoop/hadoop-2.6.0/hdfs/data</value> </property> </configuration>
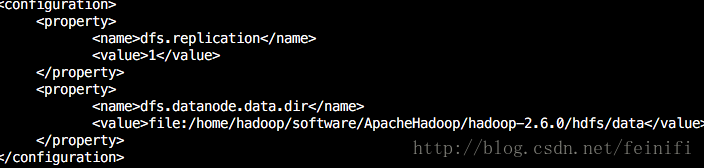
3)mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>

4)yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
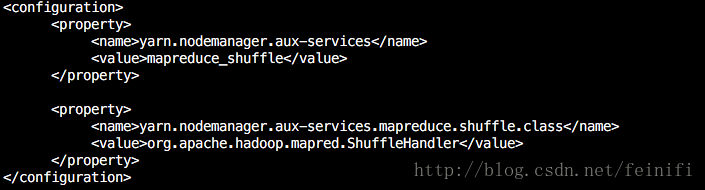
Hadoop的配置基本是按照官网的配置来的,没什么好说的。
五、数据格式化
hadoop namenode -format
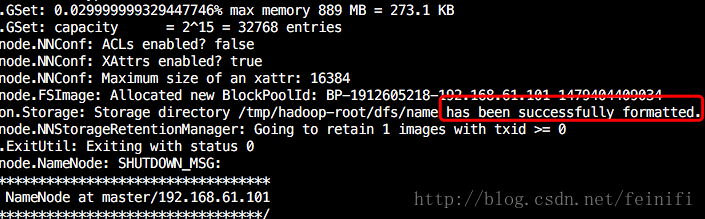
如图数据格式化出现has been successfully formatted.表示格式化成功。接着就可以依次启动Hadoop的服务了。
六、启动Hadoop
进入Hadoop安装目录,先启动hdfs,后启动yarn,如果是关闭hadoop,那么刚好相反。sbin/start-dfs.sh sbin/start-yarn.sh
停止hadoop服务
sbin/stop-yarn.sh sbin/stop-dfs.sh
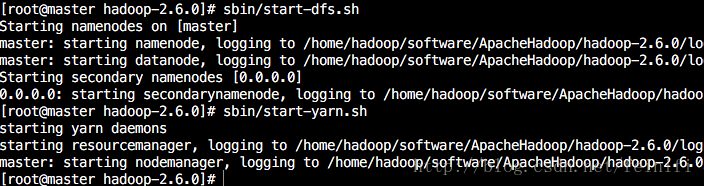
七、检验Hadoop伪分布式集群环境
a)查看java进程jps

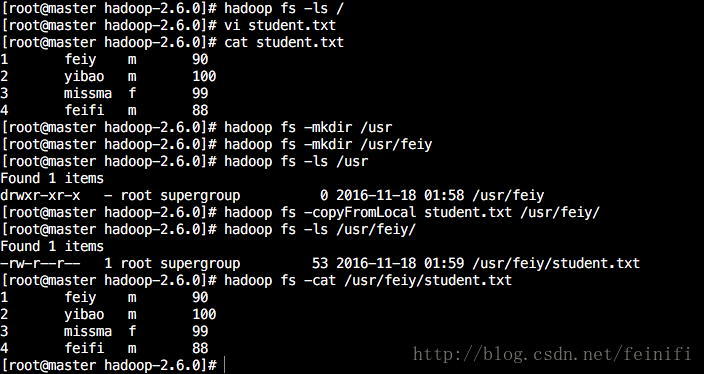
b)hadoop命令行检验hdfs文件系统
[root@master hadoop-2.6.0]# hadoop fs -ls / [root@master hadoop-2.6.0]# vi student.txt [root@master hadoop-2.6.0]# cat student.txt 1 feiy m 90 2 yibao m 100 3 missma f 99 4 feifi m 88 [root@master hadoop-2.6.0]# hadoop fs -mkdir /usr [root@master hadoop-2.6.0]# hadoop fs -mkdir /usr/feiy [root@master hadoop-2.6.0]# hadoop fs -ls /usr Found 1 items drwxr-xr-x - root supergroup 0 2016-11-18 01:58 /usr/feiy [root@master hadoop-2.6.0]# hadoop fs -copyFromLocal student.txt /usr/feiy/ [root@master hadoop-2.6.0]# hadoop fs -ls /usr/feiy/ Found 1 items -rw-r--r-- 1 root supergroup 53 2016-11-18 01:59 /usr/feiy/student.txt [root@master hadoop-2.6.0]# hadoop fs -cat /usr/feiy/student.txt 1 feiy m 90 2 yibao m 100 3 missma f 99 4 feifi m 88
以上命令依次是
查看hdfs文件系统根目录下的文件,返回为空。因为第一次操作,什么也没有。
接着在本地新建一个student.txt的文件,利用cat命令 查看到里面包含4条用tab键分割的用户信息,后面会用到。
然后在hdfs上创建了一个目录/usr
接着在/usr下创建了feiy文件夹,这两步可以合成一个命令:hadoop fs -mkdir -p /usr/feiy
接着利用copyFromLocal命令将本地文件上传到hdfs的/usr/feiy目录下,copyFromLocal可以使用put代替,效果是一样的,都比较直观,拷贝本地文件到hdfs上面。
查看该目录/usr/feiy下有什么文件(夹)
最后一条命令是查看hdfs上的student.txt文件,即为本地上传的student.txt文件。
c)浏览器查看hadoop服务(http://192.168.61.101:50070/)
服务概况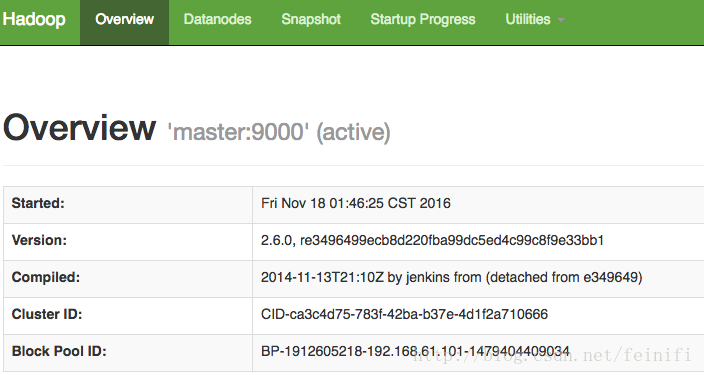
查看文件系统
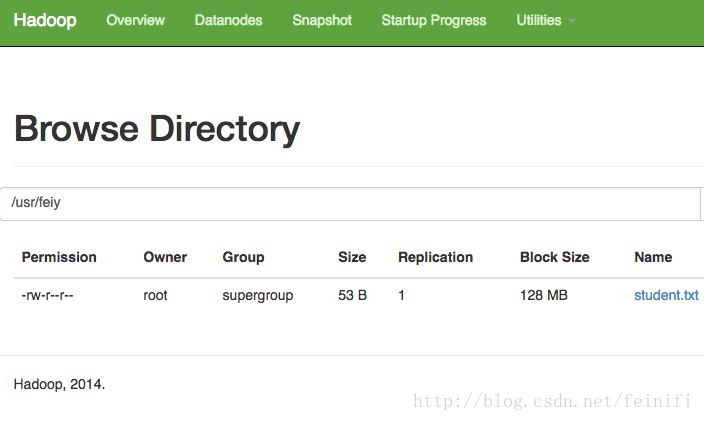

相关文章推荐
- YII2 nginx配置pathinfo模式与隐藏入口index.php
- Apache Curator实战
- 使用COPY的镜像文件进行基于表空间/数据文件的恢复
- Linux上安装DB2 Express-C 10.5 64 位的过程。
- Debian8设置开启终端快捷键
- 用x64汇编优化8位S盒置换(三)
- 网站性能优化
- Nginx配置优化指南
- linux常用命令
- Eclipse的Servers视图中无法添加Tomcat
- 使用Hive时提示org.apache.hadoop.metrics.jvm.EventCounter is deprecated警告的解决方案
- Linux 软件安装到 /usr,/usr/local/ 还是 /opt 目录?
- wondiws-tomact-restart-脚本
- 深入理解 Linux 2.6 的 initramfs 機制 (上)
- Apache ActiveMQ 官方文档中文版
- Docker private registry via Docker Registry
- Docker private registry via Harbor
- Linux-CenOS7 Samba的安装与配置
- centos7显示时间的时区修改
- linux开机自启动(开机启动)的三种方法