<机器学习>(周志华)读书笔记 -- 第一章 绪论
2017-02-06 21:07
501 查看
1.1 引言
因为人们在生活中通过"经验"可以对所看到,所听到的事物作出判断.机器学习试图研究如何通过计算的手段,利用经验来改善系统自身的性能.这里的"经验",通常是在数据中体现的,机器学习的主要研究内容就是通过这些数据,产生模型,即"学习算法". 有了学习算法,我们给学习算法数据的时候,学习算法可以基于这些数据生成模型.模型是对于对应情况的判断准则,例如:通过颜色,声音判断一个西瓜是否是一个好瓜.机器学习就是用来研究"学习算法"的学问.1.2 基本术语
在机器学习中,有很多的术语,当不了解术语的时候,越看越迷糊.越往后看,越应该牢记这些短语,符号的意思,不然既罔又怠
.而机器学习毕竟还是计算机学科,类似"="的"赋值"意思这样的和计算机程序一样的术语就不再介绍.
特征向量:

想必各位都用过excel的,D.E.F.G.H.I.J.是属性或者特征,而1,2,3,4,5,6,就是一个个特征向量.
数据集:
一般的,令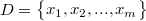
表示包含m个样本的数据集,每个示例由d个属性描述,则每个示例表示为
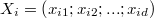
d就是x的"维数". 其实这里的数据集就是和一张excel表格一
4000
样(嗯,其实很多东西都一样,关系型数据库不也是嘛!),i就是行数,d就是列数,但是,不要忘了计算机是0开始数数的.
学习或训练:
从数据中得到模型的过程就是称为"学习"或者"训练",这个过程是执行莫个算法来完成的.训练中用到的数据称为训练数据,其中的每个样本称作训练样本.训练样本的集合称为"训练集".学得模型对应数据的某种潜在规律称为"假设";这种潜在的规律自身称为"真相"或者"真实",学习的过程就是为了找出或者逼近真相.这里真相是客观存在的,有可能永远不能到达,就像是绝对零度,不断的接近,但是却一直不能到达.样例:
对于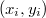
来说,表示第i个样例,xi就是上面的特征向量,yi就是对这个特征向量的标记,比如,这个特征是好的还是坏的,是第几类等等.
分类:
预测值是离散值,比如:好瓜,坏瓜.回归:
预测值是连续值,比如:瓜的成熟度是0.95,0.05聚类:
将数据集划分为几个簇,但是有可能聚成的类是内在因素导致的聚类,因为我们一般是指定聚N个类,但是具体根据什么,有时候是不可描述,但是就是一点,类内差异小,类间差异大在这里,聚类和分类有时候是可以相互转化的,分成几个类有时候也可以是聚成几个类.结果都是分开了数据.(这里被老师说了很多次...

)
1.3假设空间
对于这个概念的理解,的确,我也是没怎么搞懂。“
下面我们来构造一个“假设空间”:
比如说选择配偶时我们有以下几个指标——
体型(肥胖,匀称,过瘦)
财富(富有,一般,贫穷)
性别(同性,异性)//我这什么脑洞啊
现在我们要构建一个合适的假设空间来构建一个择偶观:
体型来说有肥胖均匀和过瘦三种,也有可能价值观里认为这个无关紧要,所以有四种可能。
加上一个极端的情况,这三个评判准则选出来的都不是想要的
所以假设空间的规模大小为4X4X3+1=49.
有很多策略来对空间里这些假设进行“筛选”,利用样本可以把假设空间里的假设一个个排除筛选。因为训练样本是有限的,所以有时会存在多个假设满足这些条件,这些假设我们叫做“训练集合”,或者版本空间(version space)
” 引用自 http://blog.csdn.net/zmdsjtu/article/details/52689392
对于这个问题,就有了这么一个理解,这个是一个对于已知各个属性的排列组合,然后我们要做的就是用训练样本在假设空间(就是属性的各种值的排列组合)验证。
嗯~ o(* ̄▽ ̄*)o,到了这里,课后习题是验证这个想法是否正确的好办法,由于作者没有哦给标准答案!!!网上也是各种答案都有啊。。。结合http://blog.csdn.net/icefire_tyh/article/details/52065224这个文章里第一题的解析,对假设空间会有更好理解。
1.4归纳偏好
首先就是为甚么需要归纳偏好,因为上面的规则我们看到了,有可能是一个集合,集合A内部的是类别A的集合B是类别B,我们也都学过集合 ,好像有个概念叫做,,,交集!!!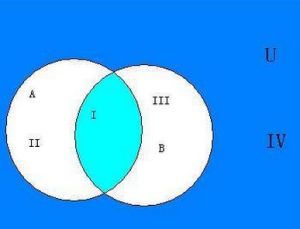
是的,如果有了交集,这个肿么办?于是就要求模型有偏好,就像找对象一样,对于两个都很优秀的小伙子,如何抉择的时候,有人选择看脸,有人选择看有木有钱。(所以我等人丑家穷的就呵呵呵了

)
在这里,其实是提出了对于一个数据集,因为偏好不一样,会有不一样的模型。这样,对于测试数据来讲结果很大可能也不一样,也就是不同模型的泛化能力,正确率不一样。
还有就是提出来了NFL定理-“没有免费午餐”定理。就是对于所有“问题”出现机会相同、或者所有问题同等重要的情况下,两个算法的期望性能一样。但是好在实际情况是现实问题是复杂的,所以脱离了具体问题的讨论“什么学习算法是最好的”是毫无意义的。嗯,是否还记得PHP是最好的语言那个梗?

相关文章推荐
- 机器学习(周志华)_第一章绪论
- 《机器学习》周志华学习笔记——第一章 绪论
- 机器学习_周志华版_读书笔记_01 绪论
- 机器学习(周志华)参考答案 第一章 绪论
- <机器学习>(周志华)读书笔记 -- 第二章 模型评估与选择
- 周志华《机器学习》读书笔记第一章
- <机器学习>(周志华)读书笔记 -- 第六章 支持向量机
- 第一章 绪论-机器学习(周志华)参考答案
- 习题答案探讨 - 《机器学习》周志华 - 第一章 绪论
- 周志华《机器学习》西瓜书第一章绪论第一部分
- <<深度探索c++对象模型>>第一章读书笔记
- 《机器学习》(周志华)第一章 绪论
- [机器学习 - 周志华] - 第一章 绪论
- 【机器学习】周志华 第一章绪论含答案
- 机器学习 周志华 读书笔记 第1章 绪论
- <机器学习>(周志华)读书笔记 -- 第五章 神经网络
- 读书笔记 --> 第一章 数据结构绪论 --> 《大话数据结构》
- 机器学习(周志华) 第一章-绪论 习题解答
- 《机器学习》-周志华 第一章 绪论 习题1.2
- 读书笔记 --> 第一章 数据结构绪论 --> 《大话数据结构》