数据挖掘中的模式发现(六)挖掘序列模式
2017-02-05 16:32
211 查看
序列模式挖掘
序列模式挖掘(sequence pattern mining)是数据挖掘的内容之一,指挖掘相对时间或其他模式出现频率高的模式,典型的应用还是限于离散型的序列。。其涉及在数据示例之间找到统计上相关的模式,其中数据值以序列被递送。通常假设这些值是离散的,因此与时间序列挖掘是密切相关的,但时间通常被认为是不同的活动。序列模式挖掘是结构化数据挖掘的一种特殊情况。

基础概念
为了帮助大家理解,我这里讲序列是如何产生的稍微描述一下。例如,一个事务数据库,一个事务代表一笔交易,一个单项代表交易的商品,单项属性中的数字记录的是商品ID
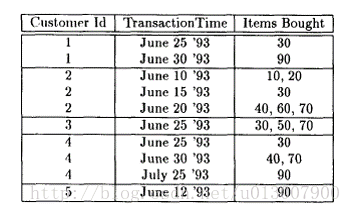
一般为了方便处理,需要把数据库转化为序列数据库。方法是把用户ID相同的记录合并,有时每个事务的发生时间可以忽略,仅保持事务间的偏序关系。

序列(Sequence)
通常以SID表示,一个序列即是一个完整的信息流。每个序列由不同的元素按顺序有序排列,每个元素由不同项目(或者也可以称之为事件)组成,让我们将其符号化
例:一条序列<(10,20)30(40,60,70)>有3个元素,分别是(10,20),30,(40,60,70);
3个事务的发生时间是由前到后。其中项目10和项目20是同时发生的,所以处在同一个元素中。这条序列是一个6-序列。
子序列(Subsequence)
设序列α=<a1a2…an>,序列β=<b1b2…bm>,ai和bi都是元素。如果存在整数序列J有1≤j1<j2<…<jn≤m,使得a1⊆bj1,a2⊆bj2,…,an⊆bjn,则称序列α为序列β的子序列,又称序列β包含序列α,记为α⊆β。支持度
序列α在序列数据库S中的支持度为序列数据库S中包含序列支持度的序列个数,记为Support(α)。给定最小支持度阈值ξ,如果序列α在序列数据库中的支持数不低于ξ,则称序列α为序列模式。
长度为l的序列模式记为l-模式。
序列模式挖掘:找出所有的频繁子序列,即该子序列在序列集中的出现频率不低于最小支持度阈值。
例子:设序列数据库如下图所示,并设用户指定的最小支持度min-support = 2。

序列<a(bc)df>是序列<a(abc)(ac)d(cf)>的子序列。
序列<(ab)c>是长度为3的序列模式,<a(abc)(ac)d(cf)>中出现了2次,<(ad)c(bc)(ae)>出现了一次。

相关文章推荐
- 数据挖掘进阶之序列模式分析算法GSP的实现
- Web使用挖掘:web数据使用模式的发现与应用(译)(1)
- 数据挖掘进阶之序列模式分析算法GSP的实现
- 数据挖掘中的模式发现(二)Apriori算法
- 数据挖掘中的模式发现(五)挖掘多样频繁模式
- 数据挖掘进阶之序列模式挖掘GSP算法
- 数据挖掘中的模式发现(三)FpGrowth算法
- 数据挖掘中的模式发现(八)轨迹模式挖掘、空间模式挖掘
- 数据挖掘之关联分析五(序列模式)
- 数据挖掘中的模式发现(七)GSP算法、SPADE算法、PrefixSpan算法
- 数据挖掘中的模式发现(四)模式评估(Pattern Evaluation)
- 数据挖掘中的模式发现(一)频繁项集、频繁闭项集、最大频繁项集
- 数据挖掘进阶之序列模式挖掘GSP算法
- 数据挖掘之关联分析五(序列模式)
- 新的大数据的知识发现和数据挖掘
- 数据挖掘--挖掘频繁模式、关联和相关(1)
- 基于网站日志数据挖掘的用户访问行为模式可视化研究
- 数据挖掘-关联分析频繁模式挖掘Apriori、FP-Growth及Eclat算法的JAVA及C++实现
- 数据挖掘--挖掘频繁模式、关联和相关(2)
- 数据集——用于数据挖掘、信息检索、知识发现等