数据挖掘中的模式发现(五)挖掘多样频繁模式
2017-02-04 15:40
351 查看
挖掘多层次的关联规则(Mining Multi-Level Associations)
定义
项经常形成层次。如图所示
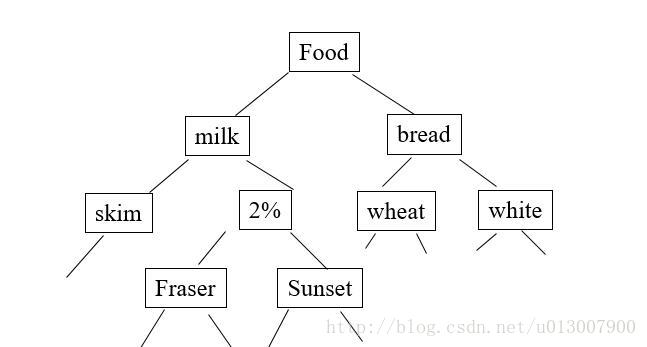
那么我们可以根据项的细化分类得到更多有趣的模式,发现更多细节的特性。
Level-reduced min-support
使用的是Level-reduced min-support方法来设置最低支持度,即,越低的层有着越低的支持度。假设我们使用的是统一的最低支持度,那么如果支持度过低,低层的频繁项集就会较少,导致很多特性显示不出来;如果支持度过高,高层的频繁项集就过多,导致过多无用的特性被展示出来。
group-based “individualized” min-support
不同种类的物品对应的最低支持度应该是不同的,比如钻石等贵重物品出现的频率肯定是低于牛奶面包等日常用品的。所以应该分组设置最低支持度。
Shared multi-level mining
使用最低层次的支持度来计算和传递候选集。也就是使用的是所有层中支持度最小的。因为这样可以保证挖掘出的关联规则不会减少。
冗余规则(redundant rules)
挖掘多层关联规则时,由于项之间的“父子”关系,有些发现的规则是冗余的。例如
已知,14的milk销售的是2%milk。
milk→wheatbread [support = 8%, confidence = 70%]
2%milk→wheatbread [support = 2%, confidence = 72%]
我们可以发现,第一个规则是第二个规则的祖先。而我们可以根据第一个规则的值以及比例放缩,计算出第二个规则的期望。而如果一个规则的支持度和置信度都接近“期望值”,那么我们称之为冗余规则。
挖掘多维度的关联规则(Mining Multi-Dimensional Associations)
单维规则:buys(X,"milk")→buys(X,"bread")
可写成形如milk→bread的boolean关联规则
多维规则:2维 或者 断言
维间关联规则 (no repeated predicates)
age(X,"19−25")∧occupation(X,"student")→buys(X,"coke")
混合维关联规则 (repeated predicates)
age(X,"19−25")∧buys(X,"popcorn")→buys(X,"coke")
分类属性
具有有限个不同值,没有排序
定量属性
数值的, 并在数值间具有隐含的序
挖掘量化关联规则(Mining Quantitative Associations)
定义
量化关联指的是具有数字数据的属性,例如,年龄、工资等。静态离散化(static discretization)
简单来说就是使用取值范围替代数值。这里使用取值范围的原因和ID3和C4.5对于离散数字的处理有关,如果你要考虑每一个年龄,或者每一个薪酬,那么项的种类就会过于丰富,从而导致我们不能敏感地发现有价值的关联规则。
但是,如果我们使用十年,或者五年作为一次年龄的分割,我们就可以将项的种类缩小,而每个项出现的频率增加。
数据立方(data cube)
使用一些预定义的层次结构概念,再加上静态的离散化,我们可以得到类似下图的数据立方体。从而更好地实现挖掘功能。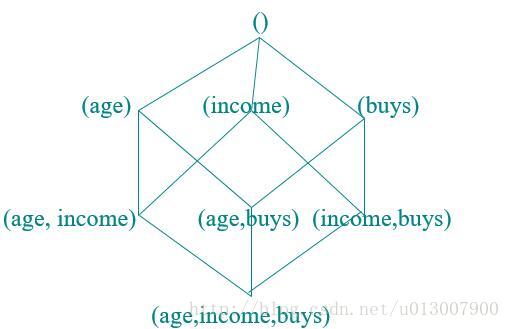
当然,这是固定的分类或者量化方法,也可以通过聚类将某一具体的数据进行分类,从而动态地决定量化方法。
偏差分析(deviation analysis)
用的是统计学的方法进行分析,一般是使用平均值或者中位数等等,然后根据规则和平均值的偏差来挖掘的。Gender=female⇒Wage:mean=$7/hr(overall mean=$9)
当然,我们也要通过一些统计学的测试来证明这个规则有着较高的可信度,而不仅仅一个例外。
挖掘负相关(Mining Negative Correlations)
罕见模式(Rare Pattern)
它们很少发生,有着较低的支持度,但是它们还是很有趣的。比如,我们买了周大生的珠宝,虽然很少发生,但是我们需要这方面的规则。
那么,之前说过需要使用分组的方式来设置个性化的最低支持度。
负模式(Negative Pattern)
基于支持度的定义(support-based definition)
负相关项集 项集X是负相关的,如果s(X)<∏kj=1s(xj)=s(x1)×s(x2)×⋯×s(xk)
s(x)是给出了X的所有项统计独立的概率估计。如果它的支持度小于使用统计独立性假设计算出的期望支持度。s(X)越小,模式就越负相关。简单来说,就是这两个事件不太会同时发生。
基于Kulczynski测量的定义
如果两个项集A和B,有如下关系P(A|B)+P(B+A)2<ϵ
则称其为负相关。(其中ϵ是人为设置的负相关的阈值)
负相关关联规则
规则X→Y是负相关的,如果s(X∪Y)<s(X)s(Y)
其中X∩Y=∅,这里定义的X和Y中的项的负相关部分条件,负相关的完全条件为
s(X∩Y)<∏is(xi)∏js(yj)
其中xi∈X而yi∈Y。因为X或Y中的项通常是正相关的,因此使用部分条件而不是完全条件来定义负相关关联规则更实际。如规则
眼镜,镜头清洁剂→隐形眼镜,盐溶液
是负相关的,但是其中项集内的项之间是负相关的,眼镜盒镜头清洁剂是负相关的,如果使用完全条件,可能就不能发现该规则了。
负相关条件也可以用正项集和负项集的支持度表示
s(X∪Y)−s(X)s(Y)=s(X∪Y)−[s(X∪Y)+s(X∪Y¯¯¯)][s(X∪Y)+s(X¯¯¯∪Y)]=s(X∪Y)s(X¯¯¯∪Y¯¯¯)−s(X∪Y¯¯¯)s(X¯¯¯∪Y)
可以得到负相关的条件为
s(X∪Y)s(X¯¯¯∪Y¯¯¯)<s(X∪Y¯¯¯)s(X¯¯¯∪Y)
负相关项集和负相关关联规则统称为负相关模式(negatively correlated pattern)。
挖掘压缩模式(Mining Compressed Patterns)
我们在进行数据挖掘的时候,会发现大量的模式,但是其中有不少的模式会有一些相似的地方,所以你得出这些规则并没有太多的意义。
例如,P1和P2的项集内容十分相近,而且他们的支持度也十分接近。但是P2和P3的项集内容十分接近,但是他们的支持度相差甚远。
压缩
闭合频繁项集我们不能用它来压缩的原因是,闭合频繁项集要求相同的支持计数。
最大频繁项集
我们当然可以使用,比如,我们可以使用P3来表示所有其他的项集,但是,我们可以清楚地知道,P3会因此损失不少可能挖掘出的规则。
Pattern Distance Measures
定义为Dist(P1,P2)=1−|T(P1)∩T(P2)||T(P1)∪T(P2)|
δ聚类:对于每一个模式,找到所有与这个模式距离小于δ的模式。
Desired patterns
这一类理想的模式具有较高的意义和较低的冗余度。
a图表示深色的模式更有意义,浅色的模式更没有意义;模式聚类成三大块。
c图使用的是传统的top-k,则找到的模式全是属于一个聚类的。
d图使用的是相关程度,找的是三个聚类的中心。
b图使用的是结合了冗余与意义的top-k方法,相比其他几个有着更加全面的考虑。
有种有趣的Maximal Marginal Significance算法可以用于解决这一类的问题。

相关文章推荐
- 数据挖掘中的模式发现(一)频繁项集、频繁闭项集、最大频繁项集
- Web使用挖掘:web数据使用模式的发现与应用(译)(1)
- 数据挖掘中的模式发现(六)挖掘序列模式
- 数据挖掘系列之三:频繁模式、关联和相关
- 本体建模与语义Web知识发现 4 基于频繁模式挖掘的XML网页分类技术
- 【数据挖掘概念与技术】学习笔记6-挖掘频繁模式、关联和相关性:基本概念和方法(编缉中)
- 数据挖掘之模式挖掘(频繁模式挖掘与Apriori算法)
- 数据挖掘中的模式发现(七)GSP算法、SPADE算法、PrefixSpan算法
- 数据挖掘中的模式发现(二)Apriori算法
- 数据挖掘读书笔记--第六章:频繁模式挖掘、关联及相关性
- 数据挖掘-关联分析频繁模式挖掘Apriori、FP-Growth及Eclat算法的JAVA及C++实现
- 数据挖掘-关联分析频繁模式挖掘Apriori、FP-Growth及Eclat算法的JAVA及C++实现
- C++---Apriori算法实现,频繁模式数据挖掘,最大频繁项集,闭频繁项集
- 数据挖掘中的模式发现(八)轨迹模式挖掘、空间模式挖掘
- 数据挖掘(七):Apriori算法:频繁模式挖掘
- 利用mahout自带的fpgrowth程序以及自己的原始数据挖掘频繁模式
- 读书笔记 -- 012_数据挖掘_频繁模式_关联性_相关性_2
- 6.数据挖掘概念笔记——挖掘频繁模式、关联和相关性术
- 数据挖掘--挖掘频繁模式、关联和相关(2)