Memcached全攻略
2017-01-21 15:17
357 查看
最近在项目中进行核心业务模块的重构,涉及对系统接口性能的改造,随着系统业务的发展,原有系统接口响应速度已并不能满足业务需求,内部调用接口时间过多,为此,设计将多次访问查询操作的数据改为使用缓存查询,缓存查询不到再次请求接口或数据库 ,这里采用memcached进行缓存。
短时间内相同数据重复查询多次且数据更新不频繁,这个时候可以选择先从缓存查询,查询不到再从数据库加载并回设到缓存的方式。此种场景较适合用单机缓存。
高并发查询热点数据,后端数据库不堪重负,可以用缓存来扛。
其他情况,可以考虑缓存服务。目前从资源的投入度、可运维性、是否能动态扩容以及配套设施来考虑,我们优先考虑Tair。除非目前Tair还不能支持的场合(比如分布式锁、Hash类型的value),我们考虑用Redis。
2. Memcached的特点
Memcached作为高速运行的分布式缓存服务器具有以下特点。
协议简单:memcached的服务器客户端通信并不使用复杂的MXL等格式,而是使用简单的基于文本的协议。
基于libevent的事件处理:libevent是个程序库,他将Linux的epoll、BSD类操作系统的kqueue等时间处理功能封装成统一的接口。memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。
内置内存存储方式:为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached,重启操作系统会导致全部数据消失。另外,内容容量达到指定的值之后memcached回自动删除不适用的缓存。
Memcached不互通信的分布式:memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。各个memcached不会互相通信以共享信息。他的分布式主要是通过客户端实现的
有记录简单地进行malloc和free来进行的。但是这中方式会导致内存碎片,加重操作系统内存管理器的负担。
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,已完全解决内存碎片问题。SlabAllocation 的原理相当简单。将分配的内存分割成各种尺寸的块(chucnk),并把尺寸相同的块分成组(chucnk的集合)如图:

而且slab allocator 还有重复使用已分配内存的目的。也就是说,分配到的内存不会释放,而是重复利用。
Slab Allocation 的主要术语
Page:分配给Slab 的内存空间,默认是1MB。分配给Slab 之后根据slab 的大小切分成chunk.
Chunk :用于缓存记录的内存空间。
SlabClass:特定大小的chunk 的组。
Memcached删除数据时数据不会真正从memcached中消失。Memcached不会释放已分配的内存。记录超时后,客户端就无法再看见该记录(invisible透明),其存储空间即可重复使用。
LazyExpriationmemcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术称为lazyexpiration.因此memcached不会再过期监视上耗费CPU时间。
对于缓存存储容量满的情况下的删除需要考虑多种机制,一方面是按队列机制,一方面应该对应缓存对象本身的优先级,根据缓存对象的优先级进行对象的删除。
Memcached会优先使用已超时的记录空间,但即使如此,也会发生追加新纪录时空间不足的情况。此时就要使用名为LeastRecently Used(LRU)机制来分配空间。这就是删除最少使用的记录的机制。因此当memcached的内存空间不足时(无法从slabclass)获取到新空间时,就从最近未使用的记录中搜索,并将空间分配给新的记录。
3.Spirng整合Memcached
memcached和spring集成(主要说spring和memcached的集成,spring本身的东东就不多说啦),这里主要是实现底层Spirng的Cache接口,思路如图:
在以上思路基础上,我们结合具体业务逻辑和程序扩展性,封装改造了一下具体实现,由原有的KEY,VALUE形式下,增加了变成两个Key,提高缓存命中率。
具体Demo如下:
1.定义基础服务接口
2.编写具体功能提供接口继承基础服务接口
3.编写具体memcached功能实现接口实现
4.SpringXML配置文件,配置文件映射具体配置信息可自定义 如下:
5.配置文件定义
接收门店变更的消息,准实时更新。
给每一个POI缓存数据设置5分钟的过期时间,过期后从DB加载再回设到DB。这个策略是对第一个策略的有力补充,解决了手动变更DB不发消息、接消息更新程序临时出错等问题导致的第一个策略失效的问题。通过这种双保险机制,有效地保证了POI缓存数据的可靠性和实时性。
① 给缓存服务,选择合适的缓存逐出算法,比如最常见的LRU。
② 针对当前设置的容量,设置适当的警戒值,比如10G的缓存,当缓存数据达到8G的时候,就开始发出报警,提前排查问题或者扩容。
③ 给一些没有必要长期保存的key,尽量设置过期时间。
概念:缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
如何解决:业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。类似下面的代码:
四:Memcached分布式
Memcached虽然称为“分布式“缓存服务器,但服务器端并没有“分布式”的功能。Memcached的分布式完全是有客户端实现的。现在我们就看一下memcached是怎么实现分布式缓存的。
例如下面假设memcached服务器有node1~node3三台,应用程序要保存键名为“tokyo”“kanagawa”“chiba”“saitama”“gunma”的数据。
首先向memcached中添加“tokyo”。将“tokyo”传给客户端程序库后,客户端实现的算法就会根据“键”来决定保存数据的memcached服务器。服务器选定后,即命令它保存“tokyo”及其值。
同样,“kanagawa”“chiba”“saitama”“gunma”都是先选择服务器再保存。
接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库。函数库通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存的值。

这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式。memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。

从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。
因此,Consistent Hashing最大限度地抑制了键的重新分布。 而且,有的ConsistentHashing的实现方法还采用了虚拟节点的思想。 使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器) 在continuum上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
1. 缓存超时被移除(正常失效)
2. 缓存由于存储空间限制被移除(异常失效)
3. 由于缓存节点变化而导致的缓存失效(异常失效)
在缓存多副本的情况下,需要重新考虑缓存的分布式分布策略。其次缓存的多个副本实际本身是可能的多个读的节点,可以做为分布式的并行读,这是另外一个可以考虑的问题。
鉴于本机是windows7 64位系统 不好找安装包
这里附上教程和下载链接,为何我一样因没有管理员权限而安装不上的朋友了。。
下载链接:http://download.csdn.net/detail/zhaotengfei36520/8182503
1、下载后解压到D:\memcached

2、安装到windows服务,打开cmd命令行,进入memcached目录,执行memcached -d install命令,安装服务。 如果在没有安装过的情况下,出现"failed to install service or service already installed"错误,可能是cmd.exe需要用管理员身份运行。

3、启动服务,执行memcached -d start
4、参数介绍
-p 监听的端口
-l 连接的IP地址, 默认是本机
-d start 启动memcached服务
-d restart 重起memcached服务
-d stop|shutdown 关闭正在运行的memcached服务
-d install 安装memcached服务
-d uninstall 卸载memcached服务
-u 以的身份运行 (仅在以root运行的时候有效)
-m 最大内存使用,单位MB。默认64MB
-M 内存耗尽时返回错误,而不是删除项
-c 最大同时连接数,默认是1024
-f 块大小增长因子,默认是1.25
-n 最小分配空间,key+value+flags默认是48
-h 显示帮助
本文参考链接:http://blog.csdn.net/cn_yaojin/article/details/51943794
http://blog.sina.com.cn/s/blog_493a845501013ei0.html http://blog.csdn.net/column/details/13858.html
一、缓存概述
1、分类
本地缓存(HashMap/ConcurrentHashMap、Ehcache、Guava Cache等),缓存服务(Redis/Tair/Memcache等)。2、使用场景
什么情况适合用缓存?考虑以下两种场景:短时间内相同数据重复查询多次且数据更新不频繁,这个时候可以选择先从缓存查询,查询不到再从数据库加载并回设到缓存的方式。此种场景较适合用单机缓存。
高并发查询热点数据,后端数据库不堪重负,可以用缓存来扛。
3、选型考虑
如果数据量小,并且不会频繁地增长又清空(这会导致频繁地垃圾回收),那么可以选择本地缓存。具体的话,如果需要一些策略的支持(比如缓存满的逐出策略),可以考虑Ehcache;如不需要,可以考虑HashMap;如需要考虑多线程并发的场景,可以考虑ConcurentHashMap。其他情况,可以考虑缓存服务。目前从资源的投入度、可运维性、是否能动态扩容以及配套设施来考虑,我们优先考虑Tair。除非目前Tair还不能支持的场合(比如分布式锁、Hash类型的value),我们考虑用Redis。
二、Memcached 的使用
1.什么是Memcached
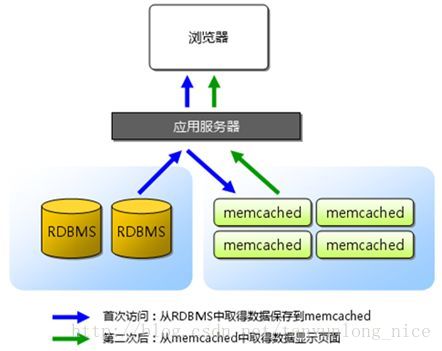
许多Web应用程序都将数据保存到RDBMS中,应用服务器从中读取数据并在浏览器中显示。但随着数据量的增大,访问的集中,就会出现REBMS的负担加重,数据库响应恶化,网站显示延迟等重大影响。Memcached是高性能的分布式内存缓存服务器。一般的使用目的是通过缓存数据库查询结果,减少数据库的访问次数,以提高动态Web应用的速度、提高扩展性。如图:2. Memcached的特点
Memcached作为高速运行的分布式缓存服务器具有以下特点。
协议简单:memcached的服务器客户端通信并不使用复杂的MXL等格式,而是使用简单的基于文本的协议。
基于libevent的事件处理:libevent是个程序库,他将Linux的epoll、BSD类操作系统的kqueue等时间处理功能封装成统一的接口。memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。
内置内存存储方式:为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached,重启操作系统会导致全部数据消失。另外,内容容量达到指定的值之后memcached回自动删除不适用的缓存。
Memcached不互通信的分布式:memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。各个memcached不会互相通信以共享信息。他的分布式主要是通过客户端实现的
3.Memcached的内存管理
最近的memcached默认情况下采用了名为SlabAllocatoion的机制分配,管理内存。在改机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是这中方式会导致内存碎片,加重操作系统内存管理器的负担。
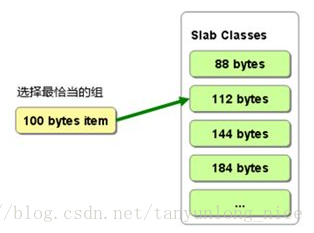
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,已完全解决内存碎片问题。SlabAllocation 的原理相当简单。将分配的内存分割成各种尺寸的块(chucnk),并把尺寸相同的块分成组(chucnk的集合)如图:
而且slab allocator 还有重复使用已分配内存的目的。也就是说,分配到的内存不会释放,而是重复利用。
Slab Allocation 的主要术语
Page:分配给Slab 的内存空间,默认是1MB。分配给Slab 之后根据slab 的大小切分成chunk.
Chunk :用于缓存记录的内存空间。
SlabClass:特定大小的chunk 的组。
在Slab 中缓存记录的原理
Memcached根据收到的数据的大小,选择最合适数据大小的Slab,memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。Memcached在数据删除方面有效里利用资源
Memcached删除数据时数据不会真正从memcached中消失。Memcached不会释放已分配的内存。记录超时后,客户端就无法再看见该记录(invisible透明),其存储空间即可重复使用。
LazyExpriationmemcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术称为lazyexpiration.因此memcached不会再过期监视上耗费CPU时间。
对于缓存存储容量满的情况下的删除需要考虑多种机制,一方面是按队列机制,一方面应该对应缓存对象本身的优先级,根据缓存对象的优先级进行对象的删除。
LRU:从缓存中有效删除数据的原理
Memcached会优先使用已超时的记录空间,但即使如此,也会发生追加新纪录时空间不足的情况。此时就要使用名为LeastRecently Used(LRU)机制来分配空间。这就是删除最少使用的记录的机制。因此当memcached的内存空间不足时(无法从slabclass)获取到新空间时,就从最近未使用的记录中搜索,并将空间分配给新的记录。
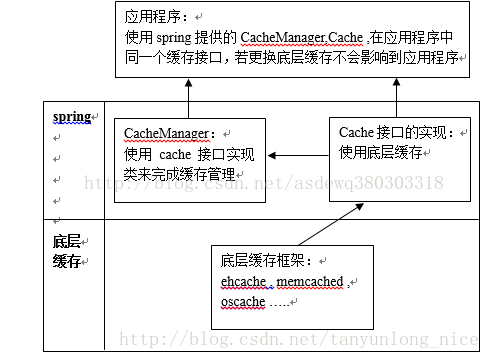
3.Spirng整合Memcached
memcached和spring集成(主要说spring和memcached的集成,spring本身的东东就不多说啦),这里主要是实现底层Spirng的Cache接口,思路如图:
在以上思路基础上,我们结合具体业务逻辑和程序扩展性,封装改造了一下具体实现,由原有的KEY,VALUE形式下,增加了变成两个Key,提高缓存命中率。
具体Demo如下:
1.定义基础服务接口
/**
* cache的工具类接口,只提供对cache方法的定义,cache具体实现,由不同的底层框架决定。
* @author tanyunlong
* @since 2016-1-5 下午14:24
* @version 1.0.0
*/
public interface ICache {
/**
* 放一个对象到cache中。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param value,放入cache的对象,可以是任意类型。
* @return 如果成功返回true。
*/
public boolean setToCache(String prefix, Object key, Object value);
/**
* 放置一个对象到cache中,并设置该对象在cache中的保存时间。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param value,放入cache的对象,可以是任意类型。
* @param second,单位:秒。表示该对象在缓存中保存多少秒。注意,如果是很长时间,比如1年等等,这样的数据使用时间失效的这个方法,意义不大。
* @return 如果成功返回true。
*/
public boolean setToCache(String prefix, Object key, Object value, long second);
/**
* 从cache中获取key所对应的对象。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @return key所对应的对象,如果没有则返回null。
*/
public Object getFromCache(String prefix, Object key);
/**
* 根据key从cache中批量获取其所对应的对象。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @return 对象数组。如果key所对应的所有对象都不存在或者key本身为null,则返回null。
*/
public Object[] getArrayFromCache(String prefix, Object[] key);
/**
* 根据key从cache中批量获取其所对应的对象。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param clasz 具体返回对象的类对象。clasz参数传入什么类对象,返回的就是相对应的类的对象。
* @return 对象的List集合。如果key所对应的所有对象都不存在或者key本身为null,则返回null。
*/
public <E> List<E> getObjArrayFromCache(String prefix, Object[] key, Class<E> clasz);
/**
* 根据key从cache中批量获取其所对应的对象。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @return Map集合。传入的T[] key 将作为Map集合的key健。如果key所对应的所有对象都不存在或者key本身为null,则返回null。
*/
public <T extends Serializable> Map<T, Object> getMapFromCache(String prefix, T[] key);
/**
* 根据key从cache中批量获取其所对应的对象。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param clasz 具体返回对象的类对象。clasz参数传入什么类对象,返回的就是相对应的类的对象。
* @return 返回Map。通过泛型,返回调用方需要的具体对象,省略调用方的类型转换工作。
*/
public <T extends Serializable, E> Map<T, E> getMapFromCache(String prefix, T[] key, Class<E> clasz);
/**
* 判断当前key是否在cache存在映射关系。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @return key及其对应的值存在,返回true。如果不存在,返回false。
*/
public boolean keyExists(String prefix, Object key);
/**
* 从cache中移除key所对应的对象。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @return 成功返回true。
*/
public boolean removeFromCache(String prefix, Object key);
/**
* 清空cache中所有对象。
* @return 成功返回true。
*/
public boolean flushAll();
}2.编写具体功能提供接口继承基础服务接口
/**
*@comment cache的工具扩展功能接口,只提供对cache方法的定义,cache具体实现,由不同的底层框架决定。
*@author tanyunlong
*@date 2017-1-5 下午14:53
*@version 1.0.1
*/
public interface ICacheExtend extends ICache{
/**
* 放置一个对象到cache中,当且仅当cache不存在该对象的key值。如果cache中已经存在,将不会放置。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param value,放入cache的对象,可以是任意类型。
* @return 如果成功返回true。如果cache中已经存在该对象的key,则表示不成功,将返回false。
*/
public boolean addToCache(String prefix, Object key, Object value);
/**
* 放置一个对象到cache中,并设置该对象在cache中的保存时间,当且仅当cache不存在该对象的key值。如果cache中已经存在,将不会放置。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param value,放入cache的对象,可以是任意类型。
* @param second,单位:秒。表示该对象在缓存中保存多少秒。注意,如果是很长时间,比如1年等等,这样的数据使用时间失效的这个方法,意义不大。
* @return 如果成功返回true。如果cache中已经存在该对象的key,则表示不成功,将返回false。
*/
public boolean addToCache(String prefix, Object key, Object value, long second);
/**
* 更新cache中的某个key-value值。当且仅当cache中存在该key,才会更新。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param value,放入cache的对象,可以是任意类型。
* @return 如果成功返回true。如果cache中没有找到该key,更新不成功,则返回false。
*/
public boolean replaceToCache(String prefix, Object key, Object value);
/**
* 更新cache中的某个key-value值,并设置该对象在cache中的保存时间,当且仅当cache中存在该key,才会更新。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param value,放入cache的对象,可以是任意类型。
* @param second,单位:秒。表示该对象在缓存中保存多少秒。注意,如果是很长时间,比如1年等等,这样的数据使用时间失效的这个方法,意义不大。
* @return 如果成功返回true。如果cache中没有找到该key,更新不成功,则返回false。
*/
public boolean replaceToCache(String prefix, Object key, Object value, long second);
/**
* 放一个计数值到cache中,并通过incrCounter、decrCounter等方法,对该值进行加、减修改,以实现计数器的功能。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param counter,初始化的计数值。
* @return 成功返回true。
* 一般的业务下,该方法使用的场景不多,完全可以由addOrIncrCounter or addOrDecrCounter代替。
*/
public boolean putCounterToCache(String prefix, Object key, long counter);
/**
* 对cache中的计数值进行加1操作。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @return 返回更新后的计数值。如果是-1,表示该key在cache对应的计数值不存在。
*/
public long incrCounter(String prefix, Object key);
/**
* 对cache中的计数值进行加操作。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param number,需要相加的值。该值必须大于0.
* @return 返回更新后的计数值。如果是-1,表示该key在cache对应的计数值不存在或者number值传入了负数。
*/
public long incrCounter(String prefix, Object key, long number);
/**
* 对cache中的计数值进行减1操作。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @return 返回更新后的计数值。如果是-1,表示该key在cache对应的计数值不存在。
*/
public long decrCounter(String prefix, Object key);
/**
* 对cache中的计数值进行减操作。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param number,需要相减的值。该值必须大于0.
* @return 返回更新后的计数值。如果是-1,表示该key在cache对应的计数值不存在或者number值传入了负数。
*/
public long decrCounter(String prefix, Object key, long number);
/**
* 对cache中的计数值做加操作。如果该值不存在,则添加(number值作为初始化值),如果该值存在,则相加。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param number,需要相加的值。该值必须大于0.
* @return 返回更新后的计数值。如果number为负数,则返回-1,表示操作无效。。为0,表示计数值已经归零。
*/
public long addOrIncrCounter(String prefix, Object key, long number);
/**
* 对cache中的计数值做减操作。如果该值不存在,则添加(number值作为初始化值),如果该值存在,则相减。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param number,需要相减的值。该值必须大于0.
* @return 返回更新后的计数值。如果number为负数,则返回-1,表示操作无效。为0,表示计数值已经归零。
*/
public long addOrDecrCounter(String prefix, Object key, long number);
/**
* 获得key所对应的计数值。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @return 返回具体计数值,如果计数值不存在则返回-1.
*/
public long getCounter(String prefix, Object key);
/**
* 通过key批量获取相对应的计数值。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @return Map集合。传入的T[] key 将作为Map集合的key健。如果key所对应的所有对象都不存在或者key本身为null,则返回null。
*/
public <T extends Serializable> Map<T, Long> getCounterMap(String prefix, T[] key);
/**
* 用户访问控制接口。<br/>
* 该接口负责一些特殊业务,比如说,控制单位时间内,用户访问服务的次数。<br/>
* 例子1,用户在应用内,1天只能做10次操作。时间由millisecond传入,访问的次数+1作为上限,用limit传入。<br/>
* 例子2,某业务,不论被访问多少次,只显示limit次。
* @param prefix,该对象在cache中对应的前缀key。
* @param key,该对象的实际key,通常,可以是对象的id等等。前缀key+key,是该对象在cache中的最终key值。
* @param millisecond cache的有效时间,多少毫秒后过期,过期后,再次访问,将重新设置计数值。单位:毫秒。 如果传-1,表示永久有效。
* @param limit 上限值。second期间内,访问次数应小于limit这个上限值。
* @return 该用户目前的访问次数,小于limit时,返回具体数值;>=limit,均返回limit的数值。
*/
public long accessControl(String prefix, Object key, long millisecond, long limit);
}3.编写具体memcached功能实现接口实现
/**
* memcached缓存接口实现
* @author tanyunlong
* @since 2017/1/5 下午15:33
* @version 1.0.0
*/
public class MemcachedAdapter implements ICacheExtend {
private MemCachedClient memCachedClient;
public boolean setToCache(String prefix, Object key, Object value) {
return memCachedClient.set(buildKey(prefix, key), value);
}
public boolean setToCache(String prefix, Object key, Object value,
long second) {
return memCachedClient.set(buildKey(prefix, key), value, toDate(second));
}
public boolean addToCache(String prefix, Object key, Object value) {
return memCachedClient.add(buildKey(prefix, key), value);
}
public boolean addToCache(String prefix, Object key, Object value,
long second) {
return memCachedClient.add(buildKey(prefix, key), value, toDate(second));
}
public boolean replaceToCache(String prefix, Object key, Object value) {
return memCachedClient.replace(buildKey(prefix, key), value);
}
public boolean replaceToCache(String prefix, Object key, Object value,
long second) {
return memCachedClient.replace(buildKey(prefix, key), value, toDate(second));
}
public boolean putCounterToCache(String prefix, Object key, long counter) {
return memCachedClient.set(buildKey(prefix, key), "" + counter);
/*
* 客户端的storeCounter存在问题,在内部set,没有将counter值转化为String,而是直接作为Object进行处理的。因此调用incr、decr等方法会出错。
* 在本方法中,我们使用set方法,自己来实现这个简单功能。
*
* return memCachedClient.storeCounter(buildKey(prefix, key), new Long(counter));
*/
}
public long incrCounter(String prefix, Object key) {
return memCachedClient.incr(buildKey(prefix, key));
}
public long incrCounter(String prefix, Object key, long number) {
return memCachedClient.incr(buildKey(prefix, key), number);
}
public long decrCounter(String prefix, Object key) {
return memCachedClient.decr(buildKey(prefix, key));
}
public long decrCounter(String prefix, Object key, long number) {
return memCachedClient.decr(buildKey(prefix, key), number);
}
public long addOrIncrCounter(String prefix, Object key, long number) {
return memCachedClient.addOrIncr(buildKey(prefix, key), number);
}
public long addOrDecrCounter(String prefix, Object key, long number) {
return memCachedClient.addOrDecr(buildKey(prefix, key), number);
}
public Object getFromCache(String prefix, Object key) {
return memCachedClient.get(buildKey(prefix, key));
}
public Object[] getArrayFromCache(String prefix, Object[] key) {
if(key == null){
return null;
}
return memCachedClient.getMultiArray(buildKeys(prefix, key));
}
public <E> List<E> getObjArrayFromCache(String prefix, Object[] key,
Class<E> clasz) {
Object[] objs = getArrayFromCache(prefix, key);
if (objs == null) {
return null;
}
List<E> list = new ArrayList<E>();
for(Object obj : objs){
list.add(clasz.cast(obj));
}
return list;
}
public <T extends Serializable> Map<T, Object> getMapFromCache(
String prefix, T[] key) {
if(key == null){
return null;
}
Map<String, Object> map = memCachedClient.getMulti(buildKeys(prefix, key));
if(map == null || map.isEmpty()){
return null;
}
Map<T, Object> ret = new HashMap<T, Object>();
for(T k : key){
Object obj = map.get(buildKey(prefix, k));
ret.put(k, obj);
}
return ret;
}
public <T extends Serializable, E> Map<T, E> getMapFromCache(String prefix,
T[] key, Class<E> clasz) {
if(key == null || clasz == null){
return null;
}
Map<String, Object> map = memCachedClient.getMulti(buildKeys(prefix, key));
if(map == null || map.isEmpty()){
return null;
}
Map<T, E> ret = new HashMap<T, E>();
for(T k : key){
Object obj = map.get(buildKey(prefix, k));
//使用cast,而不是(E)obj的强制类型转换,是因为通过clasz,可以对用户传入的E做详细控制。如果使用(E)obj,则用户无需传入clasz,则用户可以用任意E来接收返回值,从而调用时发生类型转换异常。
ret.put(k, clasz.cast(obj));
}
return ret;
}
public long getCounter(String prefix, Object key) {
return memCachedClient.getCounter(buildKey(prefix, key));
}
public <T extends Serializable> Map<T, Long> getCounterMap(String prefix,
T[] key) {
if(key == null){
return null;
}
Map<String, Object> map = memCachedClient.getMulti(buildKeys(prefix, key), null, true);
Map<T, Long> ret = new HashMap<T, Long>();
for(T k : key){
Long count = -1L;
if(map != null){
Object obj = map.get(buildKey(prefix, k));
if(obj != null){
try{
count = Long.valueOf((String)obj);
}catch(Exception e){
//出现问题,count返回-1即可。不做处理。
}
}
}
ret.put(k, count);
}
return ret;
}
public boolean keyExists(String prefix, Object key){
return memCachedClient.keyExists(buildKey(prefix, key));
}
public boolean removeFromCache(String prefix, Object key) {
return memCachedClient.delete(buildKey(prefix, key));
}
public boolean flushAll() {
return memCachedClient.flushAll();
}
public long accessControl(String prefix, Object key, long millisecond, long limit){
return this.accessControl(prefix, key, 1, millisecond, limit);
}
private long accessControl(String prefix, Object key, long number, long millisecond, long limit){
String memKey = buildKey(prefix, key);
long num = memCachedClient.getCounter(memKey);
//计数值小于limit,才进行增加,大于等于,都已经超越上限值,不考虑。
if(num < limit){
boolean notIncSign = false;
//num为-1,表示计数值不存在。
if(num == -1){
//如果需要处理失效时间。
if(millisecond > 0){
notIncSign = memCachedClient.add(memKey, number + "", new Date(millisecond));
}else{
notIncSign = memCachedClient.add(memKey, number + "");
}
}
//notIncSign为true,表示add成功,不需要inc,num为number值。为false时有两个可能性:1、计数值存在,需要inc;2、在add时候,产生了并发,没有add成功,则进行inc操作。
if(notIncSign){
num = number;
}else{
num = memCachedClient.incr(memKey, number);
}
}
//计数值通过上一个代码块,incr方法,因为并发问题,有可能返回大于limit的值,因此,在小于limit时,返回计数值,大于limit,一律返回limit值作为最终计数值。
if(num < limit){
return num;
}
return limit;
}
private String buildKey(String prefix, Object key){
return (new StringBuilder()).append(prefix).append(key).toString();
}
private String[] buildKeys(String prefix, Object[] key){
if(key == null){
return null;
}
int size = key.length;
String[] ret = new String[size];
for(int i =0;i<size ;i++){
ret[i] = buildKey(prefix, key[i]);
}
return ret;
}
private Date toDate(long second){
return new Date(second * 1000l);
//早起版本,下面注释的这段代码设置时间,会有问题。目前的版本该问题已经被修正。上面使用的方式,早期和目前版本都适用。
/*
* return new Date(System.currentTimeMillis() + (second * 1000l));
*/
}
public MemCachedClient getMemCachedClient() {
return memCachedClient;
}
public void setMemCachedClient(MemCachedClient memCachedClient) {
this.memCachedClient = memCachedClient;
}
}4.SpringXML配置文件,配置文件映射具体配置信息可自定义 如下:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd "> <!--开启缓存--> <!--<cache:annotation-driven cache-manager="cacheManager" proxy-target-class="true"/>--> <!--导入配置properties--> <context:property-placeholder location="classpath:memcache.properties"/> <bean id="memCacheSockIOPool" class="com.whalin.MemCached.SockIOPool" factory-method="getInstance" init-method="initialize"> <!--构造函数--> <!--<constructor-arg>--> <!--<value>neeaMemcachedPool</value>--> <!--</constructor-arg>--> <!--设置连接池可用的cache服务器列表,server的构成形式是IP:PORT(如:127.0.0.1:11211)--> <property name="servers"> <list> <value>${memcache.server}</value> </list> </property> <property name="weights"> <list> <value>2</value> </list> </property> <!--设置开始时每个cache服务器的可用连接数--> <property name="initConn"> <value>${memcache.initConn}</value> </property> <!--设置每个服务器最少可用连接数--> <property name="minConn"> <value>${memcache.minConn}</value> </property> <!--设置每个服务器最多可用连接数--> <property name="maxConn"> <value>${memcache.maxConn}</value> </property> <property name="maxIdle"> <value>${memcache.maxIdle}</value> </property> <!--设置连接池维护线程的睡眠时间 设置为0,维护线程不启动--> <property name="maintSleep"> <value>${memcache.maintSleep}</value> </property> <!--设置是否使用Nagle算法,因为我们的通讯数据量通常都比较大(相对TCP控制数据)而且要求响应及时,因此该值需要设置为false(默认是true)--> <property name="nagle"> <value>${memcache.nagle}</value> </property> <!--设置socket的连接等待超时值--> <property name="socketConnectTO"> <value>${memcache.socketConnectTO}</value> </property> <property name="socketTO"> <value>${memcache.socketTO}</value> </property> </bean> <bean name="memCachedClient" class="com.whalin.MemCached.MemCachedClient" depends-on="memCacheSockIOPool"> <!-- 该值默认为false,如果为true,表示以二进制协议传输 --> <constructor-arg type="boolean" value="true" /> <!-- 2.6.0以后的客户端版本不再提供set这两个变量,2.6.0版本是没有set方法,2.6.2版本set方法中会抛出异常。 <property name="compressEnable" value="true"></property> <property name="compressThreshold" value="65536"></property> --> </bean> <bean id="memcachedAdapter" class="com.sinosoft.ebusiness.autopriceCore.service.spring.MemcachedAdapter"> <property name="memCachedClient" ref="memCachedClient" /> </bean> <!--<bean id="cacheManager" class="com.cdsmartlink">--> </beans>
5.配置文件定义
#######################Memcached配置####################### #服务器地址 memcached.server=127.0.0.1:11211 #初始化时对每个服务器建立的连接数目 memcached.initConn=20 #每个服务器建立最小的连接数 memcached.minConn=10 #每个服务器建立最大的连接数 memcached.maxConn=50 #自查线程周期进行工作,其每次休眠时间 memcached.maintSleep=3000 #Socket的参数,如果是true在写数据时不缓冲,立即发送出去 memcached.nagle=false #Socket阻塞读取数据的超时时间 memcached.socketTO=3000
三、设计关键点及需要注意的地方
1.什么时候更新缓存?如何保障更新的可靠性和实时性?
更新缓存的策略,需要具体问题具体分析。这里以门店POI的缓存数据为例,来说明一下缓存服务型的缓存更新策略是怎样的?目前约10万个POI数据采用了Tair作为缓存服务,具体更新的策略有两个:接收门店变更的消息,准实时更新。
给每一个POI缓存数据设置5分钟的过期时间,过期后从DB加载再回设到DB。这个策略是对第一个策略的有力补充,解决了手动变更DB不发消息、接消息更新程序临时出错等问题导致的第一个策略失效的问题。通过这种双保险机制,有效地保证了POI缓存数据的可靠性和实时性。
2.缓存是否会满,缓存满了怎么办?
对于一个缓存服务,理论上来说,随着缓存数据的日益增多,在容量有限的情况下,缓存肯定有一天会满的。如何应对?① 给缓存服务,选择合适的缓存逐出算法,比如最常见的LRU。
② 针对当前设置的容量,设置适当的警戒值,比如10G的缓存,当缓存数据达到8G的时候,就开始发出报警,提前排查问题或者扩容。
③ 给一些没有必要长期保存的key,尽量设置过期时间。
3.缓存是否允许丢失?丢失了怎么办?
根据业务场景判断,是否允许丢失。如果不允许,就需要带持久化功能的缓存服务来支持,比如Redis或者Tair。更细节的话,可以根据业务对丢失时间的容忍度,还可以选择更具体的持久化策略,比如Redis的RDB或者AOF。4.缓存被“击穿”问题
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑另外一个问题:缓存被“击穿”的问题。概念:缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
如何解决:业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。类似下面的代码:
public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}四:Memcached分布式
Memcached虽然称为“分布式“缓存服务器,但服务器端并没有“分布式”的功能。Memcached的分布式完全是有客户端实现的。现在我们就看一下memcached是怎么实现分布式缓存的。例如下面假设memcached服务器有node1~node3三台,应用程序要保存键名为“tokyo”“kanagawa”“chiba”“saitama”“gunma”的数据。
首先向memcached中添加“tokyo”。将“tokyo”传给客户端程序库后,客户端实现的算法就会根据“键”来决定保存数据的memcached服务器。服务器选定后,即命令它保存“tokyo”及其值。
同样,“kanagawa”“chiba”“saitama”“gunma”都是先选择服务器再保存。
接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库。函数库通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存的值。
这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式。memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
ConsistentHashing的简单说明
Consistent Hashing如下所示:首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。 然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。
因此,Consistent Hashing最大限度地抑制了键的重新分布。 而且,有的ConsistentHashing的实现方法还采用了虚拟节点的思想。 使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器) 在continuum上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
缓存多副本
缓存多副本主要是用于在缓存数据存放时存储缓存数据的多个副本,以防止缓存失效。缓存失效发生在以下几种情况:1. 缓存超时被移除(正常失效)
2. 缓存由于存储空间限制被移除(异常失效)
3. 由于缓存节点变化而导致的缓存失效(异常失效)
在缓存多副本的情况下,需要重新考虑缓存的分布式分布策略。其次缓存的多个副本实际本身是可能的多个读的节点,可以做为分布式的并行读,这是另外一个可以考虑的问题。
五、番外篇:windows7 64bit 环境下安装memcached
代码编写完成后为了在我们测试环境服务器LINUX环境下安装memcached,我竟然按了一天都没安装成功,总是提示没有权限,最后没办法,为了测试只能在本机测试咯鉴于本机是windows7 64位系统 不好找安装包
这里附上教程和下载链接,为何我一样因没有管理员权限而安装不上的朋友了。。
下载链接:http://download.csdn.net/detail/zhaotengfei36520/8182503
1、下载后解压到D:\memcached
2、安装到windows服务,打开cmd命令行,进入memcached目录,执行memcached -d install命令,安装服务。 如果在没有安装过的情况下,出现"failed to install service or service already installed"错误,可能是cmd.exe需要用管理员身份运行。
3、启动服务,执行memcached -d start
4、参数介绍
-p 监听的端口
-l 连接的IP地址, 默认是本机
-d start 启动memcached服务
-d restart 重起memcached服务
-d stop|shutdown 关闭正在运行的memcached服务
-d install 安装memcached服务
-d uninstall 卸载memcached服务
-u 以的身份运行 (仅在以root运行的时候有效)
-m 最大内存使用,单位MB。默认64MB
-M 内存耗尽时返回错误,而不是删除项
-c 最大同时连接数,默认是1024
-f 块大小增长因子,默认是1.25
-n 最小分配空间,key+value+flags默认是48
-h 显示帮助
本文参考链接:http://blog.csdn.net/cn_yaojin/article/details/51943794
http://blog.sina.com.cn/s/blog_493a845501013ei0.html http://blog.csdn.net/column/details/13858.html

相关文章推荐
- DBGRIDEH 组件在Borland开发工具中应用全攻略
- ASP.NET MVC中使用Memcached
- 自由路由软件ZEBRA基本配置完全攻略
- memcached(十八)并发原语CAS与GETS操作
- phpstudy 安装memcached服务和memcache扩展
- JBuilder5 + Weblogic 6.0 安装配置全攻略
- 2003服务器安全攻略
- 转:Memcached Java Client API详解
- 用memcached-session-manager实现Tomcat集群
- springMVC整合memcached
- 分布式缓存系统Memcached在Asp.net下的应用
- 提升PHP速度全攻略
- Windows Phone Marketplace注册攻略
- DAVINCI DM3730开发攻略——DVSDK4_03和双核CODEC机制介绍
- Memcached在项目中的应用
- memcached出现:Fatal error: Call to undefined method Memcached::connect()
- Inndy的Hack Game攻略(WEB篇)
- Window 服务全攻略
- 用Nexus做Maven私服全攻略