排序算法2——快速排序
2017-01-19 23:05
197 查看
算法原理
算法实现
如何选择基准数
如何处理重复数据
(1) 选定一个基准数;
(2) 分区,将所有大于基准数的数据分为一区,将所有小于等于基准数的数据分为一区;
(3) 递归,对上述分区重复(1)(2),直到每个分区只有一个数。
———————————————————————————
下面看一个动画来快速理解该算法是怎么工作的:
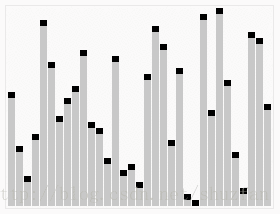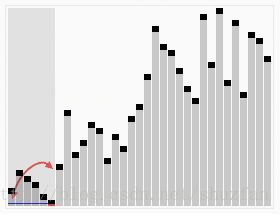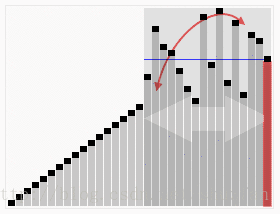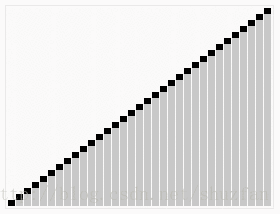
根据分区方法的不同,通常有两种处理策略:
一种称之为Lomuto 分区策略:
先上伪代码:
我们先举一个例子来理解上面的代码,由于是递归过程,我们只需要搞清楚一次分区是如何进行的就可以了。

下面给出C++的测试代码:
还有一种称之为 Hoare 的分区策略,伪代码如下:
相比Lomuto 策略,Hoare 策略需要交换的次数更少,同时可以较好的处理所有数值都相等的情况。但当数据已经有序时,Hoare 策略导致复杂度退化到O(n^2)。
比如上面我们的示例代码,要么选择最左边作为基准要么选择最右边。如果数组已经有序排列,那么这种选择方法将会导致复杂度退化到O(n^2)。
(2) 随机选择基准
虽然可以比较好的解决上面的问题,但随机数的生成往往代价不菲。
(3) 三数取中
事实上,选择中位数是一个不错的策略,但问题是计算中位数同样代价不菲。 退而求其次,左我们选择左端、右端和中心位置上的三个元素的中值作为“基准”。
随机选择的复杂度约为 \(1.386 n \log n\),三数取中的平均复杂度约为\(1.188 n \log n\)。此外,当数据量较大时,三数取中的方法可以有更好的替代策略:
\(ninther(a) = median(Mo3(first \ 1/3 \ of \ a), Mo3(middle \ 1/3\ of\ a), Mo3(final \ 1/3 \ of \ a))\)
同时,当数据量较大时,计算 \((lo + hi)/2\) 可能发生数值溢出,正确的处理方式是 \(lo + (hi−lo)/2\).
伪代码也很简单,原来只返回一个划分索引,现在要返回两个索引(小于的边界索引、大于的边界索引):
参考链接:
(1)http://www.algolist.net/Algorithms/Sorting/Quicksort
(2)https://en.wikipedia.org/wiki/Quicksort
算法实现
如何选择基准数
如何处理重复数据
——————算法原理——————
快速排序算法一种最常见的排序算法,其核心思想就是 分治 ,具体的:(1) 选定一个基准数;
(2) 分区,将所有大于基准数的数据分为一区,将所有小于等于基准数的数据分为一区;
(3) 递归,对上述分区重复(1)(2),直到每个分区只有一个数。
———————————————————————————
下面看一个动画来快速理解该算法是怎么工作的:
—————————— 算法实现 ——————————
由原理部分我们也可以先推测一下,实现算法的关键点应该和基准数的选取以及分区的存储有关。根据分区方法的不同,通常有两种处理策略:
一种称之为Lomuto 分区策略:
先上伪代码:
// 递归 quicksort(A, low, high) if low < high then // 找到新的分区点 p = partition(A, low, high) quicksort(A, low, p – 1) quicksort(A, p + 1, high) // 分区 algorithm partition(A, low, high) is // 选定最后一个元素为基准数 pivot := A[high] // 记录交换位置 i := low for j := low to high – 1 do if A[j] ≤ pivot then swap A[i] with A[j] i := i + 1 swap A[i] with A[hi] return i // 函数调用 quicksort(A, 0, length(A)-1)
我们先举一个例子来理解上面的代码,由于是递归过程,我们只需要搞清楚一次分区是如何进行的就可以了。
下面给出C++的测试代码:
#include<iostream>
// 子函数:交换两个数据
void swap(int* a, int* b)
{
int t = *a;
*a = *b;
*b = t;
}
// 子函数:数据分区,返回分区点,使得分区点左边的数据不大于分区点数据,同时分区点右边数据大于分区点数据
int partition (int arr[], int low, int high)
{
int pivot = arr[high]; // 选择基准数为最后一个元素
int i = low; // 记录待交换位置
for (int j = low; j <= high- 1; j++)
{
// 如果小于等于基准数
if (arr[j] <= pivot)
{
swap(&arr[i], &arr[j]);
i++; // 交换位置++
}
}
swap(&arr[i], &arr[high]);
return i;
}
// 快排主函数
void quickSort(int arr[], int low, int high)
{
if (low < high)
{
// 记录新的分区点
int pi = partition(arr, low, high);
// 分别处理前后两个分区
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
// 打印数组
void printArray(int arr[], int size)
{
int i;
for (i=0; i < size; i++)
printf("%d ", arr[i]);
printf("\n");
}
// 主函数
int main()
{
int arr[] = {3, 7, 8, 5, 2, 4};
quickSort(arr, 0, 5);
printf("Sorted array: \n");
printArray(arr, 6);
return 0;
}还有一种称之为 Hoare 的分区策略,伪代码如下:
algorithm quicksort(A, lo, hi) is if lo < hi then p := partition(A, lo, hi) quicksort(A, lo, p) quicksort(A, p + 1, hi) algorithm partition(A, lo, hi) is // 选定第一个元素为基准数 pivot := A[lo] i := lo - 1 j := hi + 1 loop forever do i := i + 1 while A[i] < pivot do j := j - 1 while A[j] > pivot if i >= j then return j // 分别找到一个大于和小于基准数的数值并交换 swap A[i] with A[j]
相比Lomuto 策略,Hoare 策略需要交换的次数更少,同时可以较好的处理所有数值都相等的情况。但当数据已经有序时,Hoare 策略导致复杂度退化到O(n^2)。
—————————— 如何选择基准数 ——————————
(1) 选择固定的基准比如上面我们的示例代码,要么选择最左边作为基准要么选择最右边。如果数组已经有序排列,那么这种选择方法将会导致复杂度退化到O(n^2)。
(2) 随机选择基准
虽然可以比较好的解决上面的问题,但随机数的生成往往代价不菲。
(3) 三数取中
事实上,选择中位数是一个不错的策略,但问题是计算中位数同样代价不菲。 退而求其次,左我们选择左端、右端和中心位置上的三个元素的中值作为“基准”。
随机选择的复杂度约为 \(1.386 n \log n\),三数取中的平均复杂度约为\(1.188 n \log n\)。此外,当数据量较大时,三数取中的方法可以有更好的替代策略:
\(ninther(a) = median(Mo3(first \ 1/3 \ of \ a), Mo3(middle \ 1/3\ of\ a), Mo3(final \ 1/3 \ of \ a))\)
同时,当数据量较大时,计算 \((lo + hi)/2\) 可能发生数值溢出,正确的处理方式是 \(lo + (hi−lo)/2\).
—————————— 如何处理重复数据 ——————————
最极端的情况就是数组里面的所有元素都是相等的,这个时候前面的划分为 “小于等于”和“大于”两个区的处理方式就非常低效。 这里有一种简单的线性处理策略:将数据分为三组:小于、等于、大于。伪代码也很简单,原来只返回一个划分索引,现在要返回两个索引(小于的边界索引、大于的边界索引):
algorithm quicksort(A, lo, hi) is if lo < hi then p := pivot(A, lo, hi) left, right := partition(A, p, lo, hi) // note: multiple return values quicksort(A, lo, left - 1) quicksort(A, right + 1, hi)
参考链接:
(1)http://www.algolist.net/Algorithms/Sorting/Quicksort
(2)https://en.wikipedia.org/wiki/Quicksort

相关文章推荐
- 排序算法---最常用的快速排序
- 排序算法-交换排序之快速排序
- 排序算法——快速排序
- 常用排序算法笔记之冒泡排序、快速排序
- java算法(一)——排序算法(下)之 快速排序
- C语言常用的几种排序算法代码(选择排序,冒泡排序,插入排序,快速排序)
- 排序算法(六):快速排序
- 排序算法之--快速排序
- 排序算法(五)——快速排序
- 【常用排序算法】快速排序(Java实现)
- 排序算法之快速排序
- 排序算法(Java语言)——快速排序
- 易混的排序算法:冒泡排序、选择排序、快速排序
- 排序算法--快速排序
- 排序算法之快速排序(Java)
- 排序算法复习(Java实现)(一): 插入,冒泡,选择,Shell,快速排序
- 排序算法之快速排序
- 排序算法(三)------冒泡排序和快速排序
- 排序算法-----快速排序
- 排序算法总结-插入排序、希尔排序、堆排序、快速排序