Node.js Design Patterns--2. Asynchronous Control Flow Patterns
2017-01-16 15:40
627 查看
异步编程的困难
创建一个简单的网络爬虫
考虑如下的一个网络爬虫生成的代码:var request = require('request');
var fs = require('fs');
var path = require('path');
function urlToFilename(url) {
url = url.replace('https://', '');
url = url.replace('/', '');
url = url.replace(/\./g, '_');
return url;
}
function spider(url, cb) {
var filename = urlToFilename(url);
fs.stat(filename, (err, stats) => {
// 文件不存在
if (err) {
request(url, (err, response, body) => {
if (err) return cb(err);
fs.open(filename, 'w+', (err, fd) => {
if (err) return cb(err);
fs.writeFile(fd, body, (err) => {
if (err) return cb(err);
cb(null, filename, true);
});
})
});
} else {
cb(null, filename, false);
}
});
}
spider('https://www.baidu.com/', function(err, filename, flag) {
if (err) {
return console.error(err);
}
if (!flag) {
console.log('file exists');
}
console.log('success');
});如果回调函数继续增加, 则会造成臭名昭著的"回调地狱".
回调地狱
回调地狱的一般格式如下:asyncFoo(function(err) {
asyncBar(function(err) {
asyncFooBar(function(err) {
[...]
})
})
})它主要缺点有两个:
1. 可读性差.
2. 不断声明的嵌套作用域中, 变量名无法良好的进行命名.
使用朴素的JavaScript
回调原则
编写异步代码的首要原则在于: 不要滥用闭包特性. 以下是一些基本的原则:1. 尽可能的exit. 可以使用return, continue, 或者break; 而非过多使用if/else进行判断.
2. 尽量给所调用的函数命名, 而非大量的使用匿名函数.
3. 尽量模块化, 将代码分割成更小, 可复用.
应用回调原则
使用上面的回调原则进行代码优化.var request = require('request');
var fs = require('fs');
var path = require('path');
function urlToFilename(url) {
url = url.replace('https://', '');
url = url.replace('/', '');
url = url.replace(/\./g, '_');
return url;
}
function saveFile(filename, body, cb) {
fs.open(filename, 'w+', (err, fd) => {
if (err) return cb(err);
fs.writeFile(fd, body, (err) => {
if (err) cb(err);
cb(null, filename, true);
});
})
}
function download(url, filename, cb) {
request(url, (err, response, body) => {
if (err) return cb(err);
saveFile(filename, body, (err) => {
if (err) return cb(err);
cb(null, filename, true);
});
});
}
function spider(url, cb) {
var filename = urlToFilename(url);
fs.stat(filename, (err, stats) => {
if (!err) return cb(null, filename, false);
download(url, filename, (err) => {
if (err) return cb(err);
cb(null, filename, true);
});
});
}
spider('https://www.baidu.com/', function(err, filename, flag) {
if (err) {
return console.error(err);
}
if (!flag) {
console.log('file exists');
}
console.log('success');
});顺序执行
顺序执行的流程图如下:
1. 执行队列中的任务, 不需要链式或者传播结果.
2. 每个任务的输出是下一个任务的输入.
3. 每个任务上的异步也是顺序执行.
function task1(cb) {
asyncOperation(function() {
task2(cb);
});
}
function task2(cb) {
asyncOperation(function() {
task3(cb);
});
}
function task3(cb) {
asyncOperation(function() {
cb();
});
}
task1(function() {
// task1, task2, task3 completed
});网络爬虫第二版本如下:
var request = require('request');
var fs = require('fs');
var path = require('path');
function urlToFilename(url) {
url = url.replace('https://', '');
url = url.replace('http://', '');
url = url.replace('/', '');
url = url.replace(/\./g, '_');
return url;
}
function saveFile(filename, body, cb) {
fs.open(filename, 'w+', (err, fd) => {
if (err) return cb(err);
fs.writeFile(fd, body, (err) => {
if (err) cb(err);
cb(null, filename, true);
});
})
}
function download(url, filename, cb) {
request(url, (err, response, body) => {
if (err) return cb(err);
saveFile(filename, body, (err) => {
if (err) return cb(err);
cb(null, filename, true);
});
});
}
function spider(url, cb) {
var filename = urlToFilename(url);
fs.stat(filename, (err, stats) => {
if (!err) return cb(null, filename, false);
download(url, filename, (err) => {
if (err) return cb(err);
cb(null, filename, true);
});
});
}
tasks = ['https://www.baidu.com/', 'http://www.oschina.net/'];
function iterator(index) {
if (index === tasks.length) return finish();
var task = tasks[index];
spider(task, (err, filename, falg) => {
if (!err) iterator(index + 1);
else console.error(err);
});
}
function finish() {
console.log('all download');
}
iterator(0);而使用递归执行数组内元素的顺序执行的整体思路大概如下:
function iterate(index) {
if (index === tasks.length) return finish();
var task = tasks[index];
task(function() {
iterate(index + 1);
});
}
function finish() {
// iteration completed
}
iterate(0);并行执行
考虑一下特殊的情况: 多任务中顺序并不重要, 只要都完成即可. 那么我们就可以使用并行执行策略: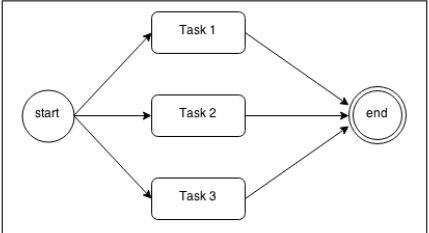
网络爬虫第三版修改为并行执行中, spiderLinks修改如下:
tasks = ['https://www.baidu.com/', 'http://www.oschina.net/'];
var completed = 0;
function iterator() {
tasks.forEach((task) => {
spider(task, (err, filename, flag) => {
if (!err) completed++;
else console.error(err);
if (completed === tasks.length) {
finish();
}
});
});
}
function finish() {
console.log('all download');
}
iterator();并行执行的思路如下:
var tasks = [...];
var completed = 0;
tasks.forEach(function(task) {
task(function() {
if (++completed === tasks.length) {
finish();
}
});
});
function finish() {
// all the tasks completed
}并行执行存在一个问题是: 竞争条件如何解决? 考虑如下spider函数:
function spider(url, nesting, cb) {
var filename = utilities.urlToFilename(url);
fs.readFile(...);
}如果存在多个相同的url, 由于是并行操作导致竞争条件: url对应的文件不存在, 两个url"同时"创建了文件, 同时读取了url, 生成相同的文件...
这里解决思路很简单:
var spidering = {};
function spider(url, nesting, cb) {
if (spidering[url]) return process.nextTick(cb);
spidering[url] = true;
[...]
}限制并行执行
考虑一种极端的情况: 我们有上千条url, 上千个文件要读取下载, 上千个数据连接打开操作. 这种情况极类似DOS攻击. 所以正常情况下我们应该限制并行执行的数量. 例如下图中并行执行数量被限制为2: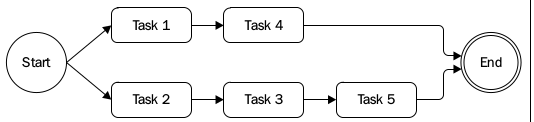
限制并发数
var request = require('request');
var fs = require('fs');
var path = require('path');
var filename_index = 0;
function urlToFilename(url) {
url = url.replace('https://', '');
url = url.replace('http://', '');
url = url.replace('/', '');
url = url.replace(/\./g, '_');
url += filename_index++;
return url;
}
function saveFile(filename, body, cb) {
fs.open(filename, 'w+', (err, fd) => {
if (err) return cb(err);
fs.writeFile(fd, body, (err) => {
if (err) cb(err);
cb(null, filename, true);
});
})
}
function download(url, filename, cb) {
request(url, (err, response, body) => {
if (err) return cb(err);
saveFile(filename, body, (err) => {
if (err) return cb(err);
cb(null, filename, true);
});
});
}
function spider(url, cb) {
var filename = urlToFilename(url);
fs.stat(filename, (err, stats) => {
if (!err) return cb(null, filename, false);
download(url, filename, (err) => {
if (err) return cb(err);
cb(null, filename, true);
});
});
}
tasks = ['https://www.baidu.com/', 'http://www.oschina.net/', 'https://www.google.com/', 'https://www.baidu.com/'];
tasks = tasks.concat(tasks);
console.log(tasks.length);
var concurrency = 2, running = 0, completed = 0, index = 0;
function next() {
while (running < concurrency && index < tasks.length) {
task = tasks[index++];
spider(task, (err, filename, flag) => {
if (!err) {
completed++;
running--;
} else {
console.error(err);
}
if (completed === tasks.length) {
return finish();
}
next();
});
running++;
}
}
next();
function iterator() {
tasks.forEach((task) => {
spider(task, (err, filename, flag) => {
if (!err) completed++;
else console.error(err);
if (completed === tasks.length) {
finish();
}
});
});
}
function finish() {
console.log('all download');
}Generators
生成器基本语法
以function* 定义函数, 以yield生成结果, 返回的值为:{
value: <yielded value>
done: <true if the execution reached the end>
}一个简单的示例为:
function* fruitGenerator() {
yield 'apple';
yield 'orange';
return 'watermelon';
}
var gen = fruitGenerator();
console.log(gen.next());
console.log(gen.next());
console.log(gen.next());输出:
leicj@leicj:~/test$ node test.js
{ value: 'apple', done: false }
{ value: 'orange', done: false }
{ value: 'watermelon', done: true }生成器一般可用于迭代
function* iteratorGenerator(arr) {
for (let i = 0; i < arr.length; i++) {
yield arr[i];
}
}
var iterator = iteratorGenerator(['apple', 'orange', 'watermelon']);
var currentItem = iterator.next();
while (!currentItem.done) {
console.log(currentItem.value);
currentItem = iterator.next();
}而生成器传值的语法如下:
function* Generator() {
var what = yield null;
console.log('Hello ' + what);
}
var gen = Generator();
gen.next();
gen.next('world');当第一次调用next时候, 执行yield null, 而第二次调用next所传递的参数, 会赋值给第一个yield的返回值what.
这段代码输出: Hello world
生成器控制异步流程
以下代码执行拷贝当前运行文件:var fs = require('fs');
var path = require('path');
function asyncFlow(gen) {
function cb(err) {
if (err) return generator.throw(err);
var results = [].slice.call(arguments, 1);
generator.next(results.length > 1 ? results : results[0]);
}
var generator = gen(cb);
generator.next();
}
asyncFlow(function* (cb) {
var fileName = path.basename(__filename);
var myself = yield fs.readFile(fileName, 'utf8', cb);
yield fs.writeFile('clone_of_' + fileName, myself, cb);
console.log('Clone created');
});1. 正常的回调函数第一个参数为err, 而后面的参数用arguments来获取.
2. myself为读取文件的数据, 并作为参数传递到写入文件中.
备注: 关于Generator这段, 不太理解其实际的具体应用.

相关文章推荐
- Node.js学习笔记 02 Implementing flow control
- ajax请求node.js接口时出现 No 'Access-Control-Allow-Origin' header is present on the requested resource错误
- 异步 JS: Callbacks, Listeners, Control Flow Libs 和 Promises【转载+翻译+整理】
- Node.js使用MongoDB3.4+Access control is not enabled for the database解决方案
- Control Flow in Node
- TCP flow control and asynchronous writes
- 【读书】《Node.js Design Patterns》1.1——Node.js哲学
- 【读书】《Node.js Desgin Patterns》前言
- Understanding Asynchronous IO With Python 3.4's Asyncio And Node.js
- Asynchronous Control Flow with Promises
- 异步js调用:callback,listeners,control flow libs 和 promises
- ajax请求node.js接口时出现跨域问题Access-Control-Allow-Origin
- Node.js Design Patterns--1.Node.js Design Fundamentals
- Node.js Design Patterns--3. Coding with Streams
- nodejs express 允许跨域访问(Access-Control-Allow-Origin)
- Asynchronous Code Design with Node.js
- Asynchronous Code Design with Node.js
- Node.js howto: make asynchronous callback from thread
- 【读书笔记】《Node.js Design Patterns》前言
- nodejs express 允许跨域访问(Access-Control-Allow-Origin)