hadoop运行eclipse简单实例
2017-01-16 14:21
211 查看
整个Hadoop是基于Java开发的,所以要开发Hadoop相应的程序就得用JAVA。在linux下开发JAVA还数eclipse方便。
1、下载
进入官网:http://eclipse.org/downloads/。
找到相应的版本进行下载,我这里用的是eclipse-SDK-3.7.1-linux-gtk版本。
2、解压
下载下来一般是tar.gz文件,运行:
$tar -zxvf eclipse-SDK-3.7.1-linux-gtk.tar.gz -c ~/Tool
这里Tool是需要解压的目录。
解完后,在tool下,就可以看到eclipse文件夹。
运行:
$~/Tool/eclipse/eclipse
3、创建开始菜单项
每次运行时,输入命令行比较麻烦,最好能创建在左侧快捷菜单上。
$sudo gedit /usr/share/applications/eclipse.desktop
1)启动文本编译器,并创建文件,添加以下内容:
?
2)创建启动器
?
3)添加可执行权限
?
4)在开始菜单中输入eclipse:

就会看到软件图标,然后将其拖到左侧工具条中即可。

4、下载hadoop在eclise中的插件并配置
直接在网上搜:hadoop-0.20.2-eclipse-plugin.jar
https://issues.apache.org/jira/secure/attachment/12460491/hadoop-eclipse-plugin-0.20.3-SNAPSHOT.jar
下载后,将jar包放在eclipse安装目录下的plugins文件夹下。然后启动eclipse

第一次启动eclpse后,会让我们设定一个工作目录,即以后建的项目都在这个工作目录下。
进入后,在菜单window->Rreferences下打开设置:


点击browse选择hadoop的源码下的Build目录,然后点OK
打开Window->View View->Other 选择Map/Reduce Tools,单击Map/Reduce Locations,会打开一个View,


添加Hadoop Loacation,其中Host和Port的内容跟据conf/hadoop-site.xml的配置填写,UserName 是用户名,如

在配置完后,在Project Explorer中就可以浏览到DFS中的文件,一级级展开,可以看到之前我们上传的in文件夹,以及当是存放的2个txt文件,同时看到一个在计算完后的out文件夹。

现在我们要准备自己写个Hadoop 程序了,所以我们要把这个out文件夹删除,有两种方式,一是可以在这树上,执行右健删除。 二是可以用命令行:
$bin/hadoop fs -rmr out
用$bin/hadoop fs -ls 查看
5、编写HelloWorld
环境搭建好了,之前运行Hadoop时,直接用了examples中的示例程序跑了下,现在可以自己来写这个HelloWorld了。
在eclipse菜单下 new Project 可以看到,里面增加了Map/Reduce选项:

选中,点下一步:

输入项目名称后,继续(next), 再点Finish

然后在Project Explorer中就可以看到该项目了,展开,src发现里面啥也没有,于是右健菜单,新建类(new->new class):

然后点击Finish,就可以看到创建了一个java类了:

-----------------------------------------------
以上为转载,结合自己试验写了如下:
-----------------------------------------------
1、 新建hadoop工程
2、新建.class 文件
随便找的一个单词计数的程序如下
package helloword;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/**
* MapReduceBase类:实现了Mapper和Reducer接口的基类(其中的方法只是实现接口,而未作任何事情)
* Mapper接口:
* WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类应该实现此接口。
* Reporter 则可用于报告整个应用的运行进度,本例中未使用。
*
*/
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
/**
* LongWritable, IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口,
* 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为long,int,String 的替代品。
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();//Text 实现了BinaryComparable类可以作为key值
/**
* Mapper接口中的map方法:
* void map(K1 key, V1 value, OutputCollector<K2,V2> output, Reporter reporter)
* 映射一个单个的输入k/v对到一个中间的k/v对
* 输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
* OutputCollector接口:收集Mapper和Reducer输出的<k,v>对。
* OutputCollector接口的collect(k, v)方法:增加一个(k,v)对到output
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
/**
* 原始数据:
* c++ java hello
world java hello
you me too
map阶段,数据如下形式作为map的输入值:key为偏移量
0 c++ java hello
16 world java hello
34 you me too
*/
/**
* 以下解析键值对
* 解析后以键值对格式形成输出数据
* 格式如下:前者是键排好序的,后者数字是值
* c++ 1
* java 1
* hello 1
* world 1
* java 1
* hello 1
* you 1
* me 1
* too 1
* 这些数据作为reduce的输出数据
*/
StringTokenizer itr = new StringTokenizer(value.toString());//得到什么值
System.out.println("value什么东西 : "+value.toString());
System.out.println("key什么东西 : "+key.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
/**
* reduce过程是对输入数据解析形成如下格式数据:
* (c++ [1])
* (java [1,1])
* (hello [1,1])
* (world [1])
* (you [1])
* (me [1])
* (you [1])
* 供接下来的实现的reduce程序分析数据数据
*
*/
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
/**
* 自己的实现的reduce方法分析输入数据
* 形成数据格式如下并存储
* c++ 1
* hello 2
* java 2
* me 1
* too 1
* world 1
* you 1
*
*/
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
/**
* JobConf:map/reduce的job配置类,向hadoop框架描述map-reduce执行的工作
* 构造方法:JobConf()、JobConf(Class exampleClass)、JobConf(Configuration conf)等
*/
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
//这里需要配置参数即输入和输出的HDFS的文件路径
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
// JobConf conf1 = new JobConf(WordCount.class);
Job job = new Job(conf, "word count");//Job(Configuration conf, String jobName) 设置job名称和
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class); //为job设置Mapper类
job.setCombinerClass(IntSumReducer.class); //为job设置Combiner类
job.setReducerClass(IntSumReducer.class); //为job设置Reduce类
job.setOutputKeyClass(Text.class); //设置输出key的类型
job.setOutputValueClass(IntWritable.class);// 设置输出value的类型
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //为map-reduce任务设置InputFormat实现类 设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//为map-reduce任务设置OutputFormat实现类 设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3、工程上右键 run as Run configuration(配置)

看看hdfs中的文件结构路径是咋放的:
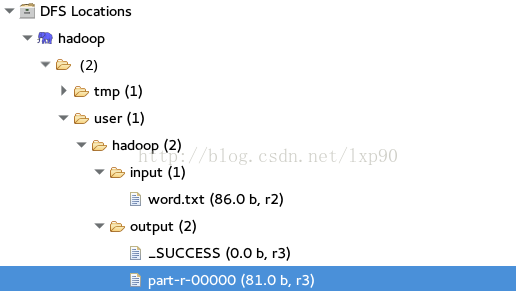
对应的参数配置写法:
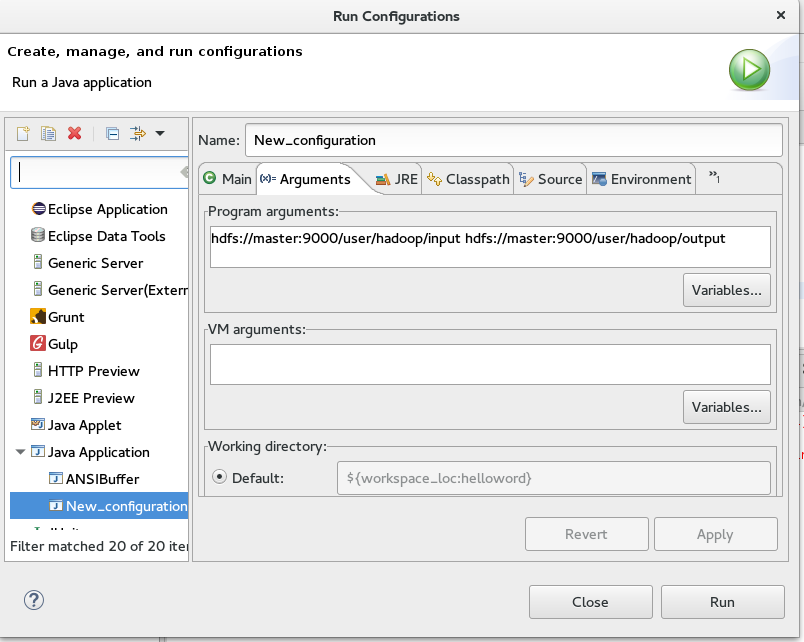
对 VM argument 进行补充配置可以有效的消除 运行过程中的警告信息~~~
4、看结果
调试结果
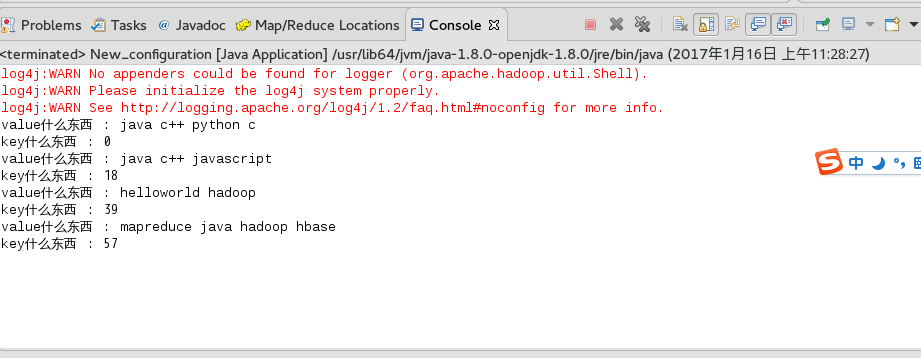
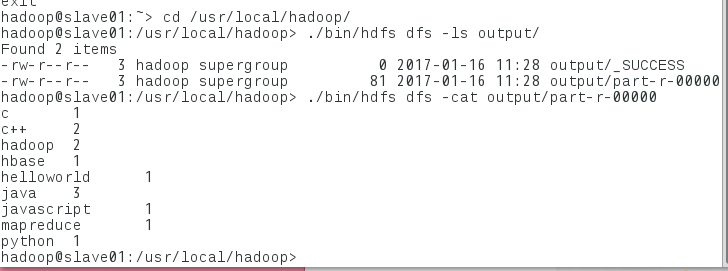
计数结果:
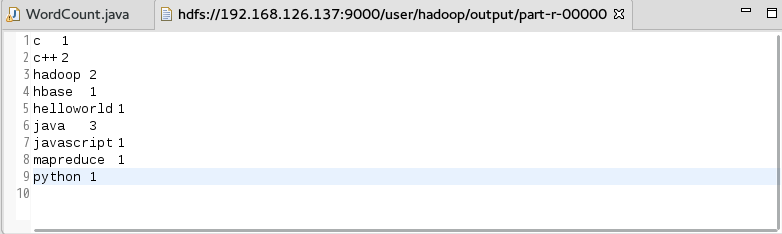
datanode上的结果
1、下载
进入官网:http://eclipse.org/downloads/。
找到相应的版本进行下载,我这里用的是eclipse-SDK-3.7.1-linux-gtk版本。
2、解压
下载下来一般是tar.gz文件,运行:
$tar -zxvf eclipse-SDK-3.7.1-linux-gtk.tar.gz -c ~/Tool
这里Tool是需要解压的目录。
解完后,在tool下,就可以看到eclipse文件夹。
运行:
$~/Tool/eclipse/eclipse
3、创建开始菜单项
每次运行时,输入命令行比较麻烦,最好能创建在左侧快捷菜单上。
$sudo gedit /usr/share/applications/eclipse.desktop
1)启动文本编译器,并创建文件,添加以下内容:
?
?
?
就会看到软件图标,然后将其拖到左侧工具条中即可。
4、下载hadoop在eclise中的插件并配置
直接在网上搜:hadoop-0.20.2-eclipse-plugin.jar
https://issues.apache.org/jira/secure/attachment/12460491/hadoop-eclipse-plugin-0.20.3-SNAPSHOT.jar
下载后,将jar包放在eclipse安装目录下的plugins文件夹下。然后启动eclipse
第一次启动eclpse后,会让我们设定一个工作目录,即以后建的项目都在这个工作目录下。
进入后,在菜单window->Rreferences下打开设置:
点击browse选择hadoop的源码下的Build目录,然后点OK
打开Window->View View->Other 选择Map/Reduce Tools,单击Map/Reduce Locations,会打开一个View,
添加Hadoop Loacation,其中Host和Port的内容跟据conf/hadoop-site.xml的配置填写,UserName 是用户名,如
在配置完后,在Project Explorer中就可以浏览到DFS中的文件,一级级展开,可以看到之前我们上传的in文件夹,以及当是存放的2个txt文件,同时看到一个在计算完后的out文件夹。
现在我们要准备自己写个Hadoop 程序了,所以我们要把这个out文件夹删除,有两种方式,一是可以在这树上,执行右健删除。 二是可以用命令行:
$bin/hadoop fs -rmr out
用$bin/hadoop fs -ls 查看
5、编写HelloWorld
环境搭建好了,之前运行Hadoop时,直接用了examples中的示例程序跑了下,现在可以自己来写这个HelloWorld了。
在eclipse菜单下 new Project 可以看到,里面增加了Map/Reduce选项:
选中,点下一步:
输入项目名称后,继续(next), 再点Finish
然后在Project Explorer中就可以看到该项目了,展开,src发现里面啥也没有,于是右健菜单,新建类(new->new class):
然后点击Finish,就可以看到创建了一个java类了:
-----------------------------------------------
以上为转载,结合自己试验写了如下:
-----------------------------------------------
1、 新建hadoop工程
2、新建.class 文件
随便找的一个单词计数的程序如下
package helloword;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/**
* MapReduceBase类:实现了Mapper和Reducer接口的基类(其中的方法只是实现接口,而未作任何事情)
* Mapper接口:
* WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类应该实现此接口。
* Reporter 则可用于报告整个应用的运行进度,本例中未使用。
*
*/
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
/**
* LongWritable, IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口,
* 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为long,int,String 的替代品。
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();//Text 实现了BinaryComparable类可以作为key值
/**
* Mapper接口中的map方法:
* void map(K1 key, V1 value, OutputCollector<K2,V2> output, Reporter reporter)
* 映射一个单个的输入k/v对到一个中间的k/v对
* 输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
* OutputCollector接口:收集Mapper和Reducer输出的<k,v>对。
* OutputCollector接口的collect(k, v)方法:增加一个(k,v)对到output
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
/**
* 原始数据:
* c++ java hello
world java hello
you me too
map阶段,数据如下形式作为map的输入值:key为偏移量
0 c++ java hello
16 world java hello
34 you me too
*/
/**
* 以下解析键值对
* 解析后以键值对格式形成输出数据
* 格式如下:前者是键排好序的,后者数字是值
* c++ 1
* java 1
* hello 1
* world 1
* java 1
* hello 1
* you 1
* me 1
* too 1
* 这些数据作为reduce的输出数据
*/
StringTokenizer itr = new StringTokenizer(value.toString());//得到什么值
System.out.println("value什么东西 : "+value.toString());
System.out.println("key什么东西 : "+key.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
/**
* reduce过程是对输入数据解析形成如下格式数据:
* (c++ [1])
* (java [1,1])
* (hello [1,1])
* (world [1])
* (you [1])
* (me [1])
* (you [1])
* 供接下来的实现的reduce程序分析数据数据
*
*/
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
/**
* 自己的实现的reduce方法分析输入数据
* 形成数据格式如下并存储
* c++ 1
* hello 2
* java 2
* me 1
* too 1
* world 1
* you 1
*
*/
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
/**
* JobConf:map/reduce的job配置类,向hadoop框架描述map-reduce执行的工作
* 构造方法:JobConf()、JobConf(Class exampleClass)、JobConf(Configuration conf)等
*/
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
//这里需要配置参数即输入和输出的HDFS的文件路径
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
// JobConf conf1 = new JobConf(WordCount.class);
Job job = new Job(conf, "word count");//Job(Configuration conf, String jobName) 设置job名称和
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class); //为job设置Mapper类
job.setCombinerClass(IntSumReducer.class); //为job设置Combiner类
job.setReducerClass(IntSumReducer.class); //为job设置Reduce类
job.setOutputKeyClass(Text.class); //设置输出key的类型
job.setOutputValueClass(IntWritable.class);// 设置输出value的类型
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //为map-reduce任务设置InputFormat实现类 设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//为map-reduce任务设置OutputFormat实现类 设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
3、工程上右键 run as Run configuration(配置)
看看hdfs中的文件结构路径是咋放的:
对应的参数配置写法:
对 VM argument 进行补充配置可以有效的消除 运行过程中的警告信息~~~
4、看结果
调试结果
计数结果:
datanode上的结果

相关文章推荐
- java ee JPA的关系
- JAVA常用的高级数据类型
- Java对象的序列化与反序列化
- Java内存系列二之对象创建
- TransactionTemplate VS @transaction
- RxJava
- Java Web Start
- 学习笔记:如何从Eclipse导入github上的项目源代码
- javafx TableView 添加事件
- 在eclipse/myeclipse中新建Maven框架的web项目
- Struts1实现文件上传
- 开涛的博客之shiro
- java 访问后台方法顺序混乱
- java 小技巧
- spring boot 整合 freemark(简单结构)
- Java调用Microsoft exchange ews接口空指针问题分析
- Java访问权限修饰词
- [JAVA+japidview] 金额及百分数处理
- eclipse 如何debug jdk源码(转)
- java 枚举——java中枚举的运用和使用场景